Az Intel vezetése már jó előre beharangozta, hogy szeptember 19-én és szeptember 20-án tartják az Intel Innovation Event 2023-as kiadását, azt viszont nem árulták el, konkrétan miről is lesz szó. A találgatások között volt a Meteor Lake processzorok bejelentése, valamint a Raptor Lake Refresh generáció bemutatása is, ugyanakkor sokan abban is reménykedtek, akár a következő generációs Arc videokártyákról is szó eshet majd, plusz szerverpiaci fejlesztésekkel kapcsolatos bejelentésekre is lehetett számítani.
A rendezvény bejelentésekkel teletűzdelt bevezető részét időközben megtartották, elő is kerültek a Meteor Lake processzorok, de csak architektúra szintjén, konkrét modellek még nem. Szóba kerültek a következő generációs architektúrák is, valamint egy Lunar Lake demót is láthattunk. A vállalat egy extrém sok, 288 processzormaggal ellátott szerverpiaci fejlesztésről is lerántotta a leplet, valamint néhány egyébre is fény derült. A legfontosabb bejelentéseket az alábbiakban összegezzük.
December 14-én érkeznek a Core Ultra sorozatú Meteor Lake processzorok
A korábbi bejelentések alapján már nem okozhat meglepetést, hogy az Intel a Meteor Lake generációtól kezdve új nevezéktant vezet be, erről már írtunk is. Előtte még egy Raptor Lake Refresh generáció is be fog mutatkozni az aktuális nevezéktannal, ami a 14. Core generációt alkotja, ám ezekről a termékekről most sajnos nem beszéltek a vállalat illetékesei. A Meteor Lake motorháztetője alatt lévő fejlesztéseket viszont minden eddiginél részletesebben kifejtették, igaz, erre nem konkrétan az Intel Innovation Event 2023, hanem a Malajziában zajló Intel Tech Tour alkalmával került sor. Lényeg a lényeg: nagyon sok részletre derült fény, amelyekről érdemes említést tenni.
A Meteor Lake felépítése

A Meteor Lake processzorokkal kapcsolatban már régóta tudható, hogy úgynevezett csempés felépítés alkalmaznak majd, vagyis az egyes részegységeket külön lapkákba szervezik ki, ezeket pedig a Foveros 3D tokozás fogja össze egy tokozáson belülre. Ez, vagyis a Foveros 3D az Intel szerint az elmúlt 40 esztendő legnagyobb váltása architektúra terén, ami megnyitja az utat a még fejlettebb chipek előtt – ezt Pat Gelsinger, az Intel vezetője a vállalat következő „Centrino pillanatának” nevezte, amiben bizony van is valami.

Maga a Meteor Lake processzor négy darab csempéből, vagy ha úgy tetszik, chipletből épül fel, amelyek egy 3D Foveros passzív interposer lapkára épülnek. A processzormagokat tartalmazó CPU Tile az Intel 4 gyártástechnológiával készül, míg a GPU Tile, ami a grafikus processzor részegységeit tartalmazza, már a TSMC N5 gyártástechnológiáját használhatja. A fennmaradó két lapka, vagyis az IO Tile és a SoC Tile egyformán a TSMC N6 gyártástechnológiája köré épül. Ezek a lapkák egy passzív interposer réteg felett foglalnak helyet (Foveros 3D), ami összeköttetést biztosít közöttük. Maga a Foveros 3D lapka az Intel 22FFL, azaz az Intel 16 gyártástechnológia köré épül, ahhoz ugyanis egy régebbi, kiforrott csíkszélesség is elegendő volt az optimális működéshez. A 3D Foveros tokozás jóvoltából az egyes részegységek között kellő sávszélességgel és kellően alacsony késleltetéssel dolgozó kapcsolat húzódik annak érdekében, hogy a teljesítmény olyan lehessen, mint egy monolitikus chipnél, ami egyetlen nagy lapkából áll.
Az Intel 4 gyártástechnológia
A CPU Tile ismertetése előtt érdemes megemlékezni az Intel 4 gyártástechnológiáról is. Az Intel 4 gyártástechnológia az első olyan Intel csíkszélesség, ami EUV levilágítást használ. Ez a gyártástechnológia az Intel szerint az elmúlt évtized csíkszélességei között a legjobb kihozatali arányt kínálta a nulladik napon, ami mindenképpen komoly fegyvertény. Erre a kicsinek semmiképpen sem nevezhető sikerélményre persze szükség is van a 10 nm-es csíkszélesség körüli botladozások után, amelyek miatt hosszú évekre parkolópályára került a vállalat csíkszélesség-fejlesztése. Az Intel 4 gyártástechnológia esetében a nagyteljesítményű tranzisztor skálázódását duplázták az előző node-hoz képest, ugyanakkora teljesítményszint mellett pedig akár 20%-kal magasabb órajelek elérésére van mód, ami igencsak jól hangzik. Az új gyártástechnológiánál 20%-kal kevesebb maszkot és 5%-kal kevesebb gyártási lépést használnak, hála az EUV levilágítás bevetésének. Az Intel szakemberei szerint a vállalat történetében igazából ez az első olyan gyártástechnológia, amelynél a maszkok száma az előző node-nál használt mennyiséghez képest csökkenhetett.
A CPU Tile

A kirakós egyik legfontosabb eleme tehát a CPU Tile, ami az Intel 4 gyártástechnológiát használja és vegyesen tartalmaz P-Core, illetve E-Core típusú processzormagokat – előbbiek a teljesítményre hangolt, utóbbiak pedig az energiahatékonyságra optimalizált megoldások. Mellettük a SoC Tile tartalmaz még további két processzormagot, amelyek ugyancsak energiahatékonyságra optimalizálva érkeznek, ezekről majd később ejtünk szót, a SoC Tile részletezésnél. A CPU Tile tehát Redwood Cove típusú P-Core és Crestmont típusú E-Core processzormagokból épül fel. Ezek közül a RedWood Cove példányok lényegében nem hoznak IPC növekedést a Raptor Cove alapú megoldásokhoz képest, ezek ugyanis úgynevezett „Tick” sorozatú megoldások, amelyeknél a régi Tick-Tock stratégia értelmében nincs változás architektúra terén, de a csíkszélesség kisebb lett, azaz Intel 7 helyett Intel 4 van használatban, ami természetesen számos előnyt tartogat.

Az új gyártástechnológia jóvoltából persze így is növekszik a teljesítmény, hiszen magasabb órajelek érhetőek el ugyanolyan teljesítmény mellett, de opcionálisan ugyanolyan teljesítményszint is belőhető, alacsonyabb fogyasztás mellett. Az Intel 4 csíkszélesség a Intel 7-hez képest nagyjából 20%-os előrelépést hoz energiahatékonyság terén, ami óriási.
Az új csempés felépítés hatékonyabbá tétele érdekébe a memória és a gyorsítótár esetében történtek optimalizációk, amelyek segítenek a sávszélesség növelésében mind a magonkénti kommunikációnál, mind platform szinten. Az energiahatékonyságot fokozza a kibővített telemetria, ami segíti a Thread Director működését és a tápmenedzsmenttel foglalkozó egység is hatékonyabban dolgozhat általa, így a különböző terhelésformák a megfelelő processzormagokra kerülhetnek a megfelelő időben.

Az E-Core részleg, vagyis a Crestmont architektúra köré épülőprocesszormagok nagyjából 3%-os IPC növekedést hoznak a Gracemont architektúrához képest, amelynek nagy része a VNNI utasításkészlet támogatásának köszönhető, így az AI jellegű terhelésformák alatt jobb teljesítményt lehet elérni. A Crestmont processzormagok esetében nagy változás, hogy itt már nemcsak négymagos, hanem kétmagos dizájn alkalmazására is van mód a magfürtöknél – mindkét esetben maximum 4 MB-nyi L2 Cache és 3 MB-nyi L3 Cache használható. A kétmagos megoldásoknál értelemszerűen duplázódik az egy magra jutó gyorsítótár kapacitása, ami bizonyos terhelésformák esetében kifejezetten jól jöhet. Igazából a SoC Tile fedélzetén található Crestmont E-Core részlegnél pont ezt a dizájnt veti be a vállalat. Az E-Core részleg természetesen továbbra sem rendelkezik Hyper-Threading támogatással, viszont AVX10 támogatás rendelkezésre áll, ami szimmetrikus utasításkészlet-támogatást eredményez a P-Core és az E-Core részleg között. Ezen felül AVX-DOT-PROD-INT8, AVX-IFMA, BF16 és FP16 támogatást is fel tudnak mutatni az új processzormagok.
A GPU Tile
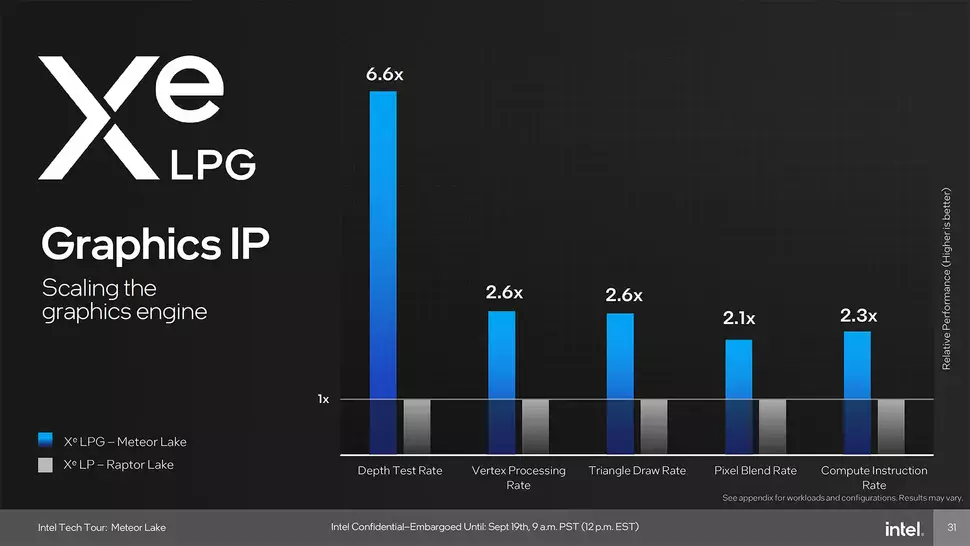
A következő nagy csempe a GPU Tile, ami már a TSMC N5 gyártástechnológiáját használhatja. Ez a csempe az Xe-LPG architektúra köré épül, és az Intel szerint kétszer jobb teljesítmény/watt hányadossal rendelkezik, mint az Xe-LP architektúra, amit az Iris Xe sorozatú iGPU-k használhatnak. Ezzel egy időben a teljesítmény is duplájára növekszik az előző generációhoz képest, vagyis dGPU szintű teljesítményre számíthatunk egy kompakt formátumban, ami nem hangzik rosszul. Hogy ez pontosan mekkora teljesítményt takar? Erről majd később, a független tesztek érkezésekor beszélhetünk, az viszont már most is világos, hogy az iGPU dizájn változik, jóval ütőképesebb lesz.
A számok nyelvén ez azt jelenti, hogy az Xe-LPG alapú iGPU maximum 8 darab Xe grafikus maggal rendelkezik, amelyek egyenként 16, azaz összesen 128 vektormotorral rendelkeznek, valamint összesen 8 mintavételező is rendelkezésre áll. Ez 1,33x-os növekedés az Intel Xe-LP alapú megoldásaihoz képest. A kínálat részét képezi még 4 Pixel Backend is, amelyekből az előző generációs megoldások fedélzetén csak 3 darab volt, és ezzel egy időben a geometriai futószalagok számát is megduplázták. Újítás, hogy az iGPU részleg most már 8 dedikált Ray-Tracing egységet is kapott (RTU), ami az előző generációnál hiánycikk volt. A RoP egységek és a textúrázók számát egyelőre sajnos nem részletezték, de remélhetőleg velük kapcsolatban is kiszivárog ez-az az elkövetkező hetek folyamán.

Az egyes Xe magok tehát 16 vektormotorral rendelkeznek, amelyek 256-bites sávszélességgel dolgozhatnak, valamint minden egyes Xe mag tartalmaz még 192 KB-nyi megosztott elsőszintű gyorsítótárat is. Egy-egy vektormotor maximum 16 FP32-es műveletet tud elvégezni órajelenként, míg FP16-os műveletekből 32-t, INT8-as műveletekből pedig 64-et. Újítás az FP64 támogatás bevezetése is, ami még az Arc Alchemist sorozatból is hiányzik. A DirectX 12 optimalizációval készülő iGPU esetében immár Out of Order Sampling támogatás is rendelkezésre áll, amellyel kapcsolatban még nem árult el részleteket a gyártó, de ami késik, nem múlik.

Érdekes, de felettébb hasznos döntés, hogy az iGPU részlegből kivették a Media Engine és a Display Engine névre keresztelt komponenseket, vagyis a médiamotort és a kijelzőmotort, amelyek átkerültek a SoC Tile fedélzetére, így ezek a iGPU alacsony fogyasztású állapotában is teljesen függetlenül, önállóan működhetnek. Ha például a rendszer videót kódol vagy videót játszik le, nem kell az iGPU-t felébreszteni, így energiát lehet megtakarítani, ami egy okos döntés. Az Xe-LPG architektúra köré épülő iGPU-k egyébként részben annak is köszönhetik nagyobb teljesítményüket és magasabb energiahatékonyságukat, hogy alacsonyabb feszültség/frekvencia görbét használnak, mint az előző generációs megoldások, azaz alacsonyabb minimális üzemi feszültséget vethetnek be magasabb maximális órajel mellett, ami egy mobil platform esetében kulcsfontosságú előny. Érdemes még megemlíteni, hogy az iGPU a fentiekkel együtt az AI feladatok gyorsítására is képes, hála a DP4A gyorsításnak.
A SoC Tile
El is érkeztünk a következő komponenshez, a TSMC N6 gyártástechnológiájával készülő SoC Tile-hoz, ami központi kommunikációs pontnak tekinthető, hiszen egy új generációs Uncore részlegről van szó. Ennél a komponensnél az elsődleges szempont az alacsony fogyasztás elérése, így az Intel alacsony fogyasztású szigetként is hivatkozik rá. A „sziget” fedélzetén találunk két darab E-Core típusú processzormagot, valamint egy Neurális Feldolgozó Egységet (NPU), ami egyebek mellett az AI feladatok futtatására készült. Ebben a chipletben foglal helyet a fentebb említett médiamotor és a kijelzőmotor is, ami nemcsak a fentebb említett energiahatékonyság-növelés miatt nevezhető jó döntésnek, hanem azért is, mert így nem kell a drága tranzisztorbüdzsét ezekre pazarolni az iGPU esetében, ami ugye a drágább TSMC N5 gyártástechnológiát használja. A SoC Tile kijelző-vezérlője egyebek mellet HDMI 2.1 és DisplayPort 2.1 támogatással rendelkezik, utóbbihoz pedig DSC 1.2a támogatás is jár. A médiamotor képes a 8K HDR tartalmak és az AV1 alapú tartalmak dekódolásának és kódolásának gyorsítására, azaz fel van készítve a modern tartalmak kezelésére.
Maga a SoC Tile a GPU Tile szomszédságában foglal helyet, a kettő között pedig kommunikációs csatornát alakítottak ki, amely gondoskodik a megfelelő sávszélesség és késleltetés mellett történő adatátvitelről. Egy másodlagos kapcsolat is rendelkezésre áll, ez viszont már az órajel, a teszt és a debug jelek továbbításáról gondoskodik, valamint egy dedikált PMC (Power Managemenet Controller) interfész is húzódik a csempék között ami a tápellátással kapcsolatos kommunikációt biztosítja. Maga a GPU egyébként egy izolált nagyteljesítményű gyorsítótár-koherens hálózathoz kapcsolódik a chipen belül, ami az NPU-hoz, a két E-Core-hoz, valamint a médiamotorhoz és a kijelző*motorhoz is hozzáférést biztosít, mindezt hatékony memória-sávszélesség hozzáférés mellett, amit az ugyanezen a buszon lógó memóriavezérlők biztosítanak. Ez a gyorsítótár-koherens hálózat (NOC) a Compute Tile felé is kapcsolatot biztosít a lapka másik oldalán.

A lapka használ egy második, alacsonyabb fogyasztású IO összekötőt is, ami az I/O lapkát köti be. Ez az összekötő az alacsonyabb prioritású komponenseket szolgálja ki, vagyis a Wi-Fi 6E és a Wi-Fi 7 vezérlőket, a Bluetooth vezérlőket, a biztonsági motorokat, az Ethernet vezérlőt, valamint a PCIe és a SATA portokat, plusz egyéb hasonló komponenseket is. Ezzel lényegében két független összekötő is dolgozik a lapkán, amelyeknek egymással is kommunikálniuk kell. Ezeket az Intel egy I/O Cache segítségével kapcsolta össze, ami buffereli a forgalmat a két összekötő között, vagyis így van némi extra késleltetés a kommunikációban, de ez megfelel a megcélzott teljesítményszintnek az alacsonyabb prioritású összekötő esetében.
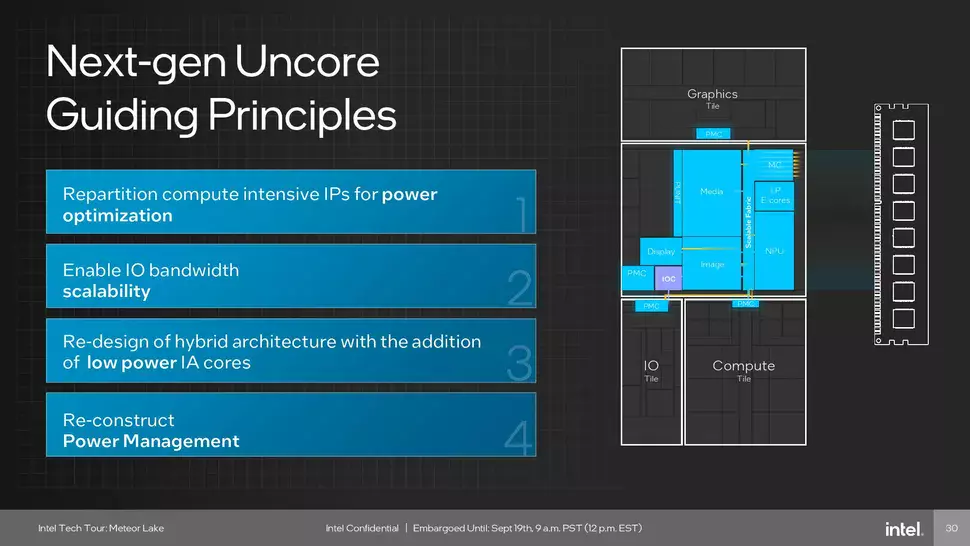
Ezt az új összekötő hierarchiát az Intel következő generációs Uncore néven emlegeti. Erre mindenképpen szükség is volt, hiszen a SoC Tile most már sávszélesség-éhes komponensekkel bővült, amelyeket a korábbi generációs, klasszikus Uncore rendszernem tudott volna hatékonyan kiszolgálni. Utóbbinál az I/O összekötő a System Agent Controlleren keresztül kommunikálhatott, ami izolált memória-vezérlőkhöz kapcsolódott, viszont ez a System Agent Controller ugyanakkor a gyűrűs összekötő felé folyó memória-sávszélességet is kézben tartotta, ami a processzormagok kiszolgálásához nélkülözhetetlen volt.
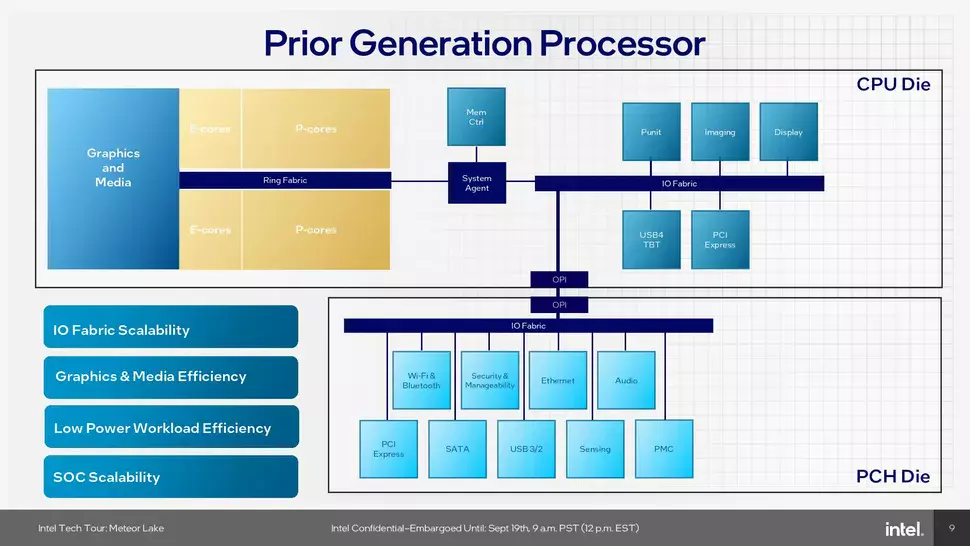
Ez a rendszer sávszélesség terén kihívásokkal küzdött, amit az új megoldással meg lehetett kerülni. Újítás még az is, hogy minden egyes csempe külön PMC vezérlőt kapott, amelyekkel egyedileg vezérelhető az egyes csempék üzemi feszültsége és órajele, ami hatékonyabb tápmenedzsmentet is eredményez. Az egyes csempék PMC-i persze a SoC Tile fedélzetén található két PMC-hez kapcsolódnak, így van egy hierarchia is a tápmenedzsment esetében, ami segít az energiahatékonyság további növelésében. Említést érdemel még, hogy minden egyes csempe saját digitális lineáris feszültségszabályzókat kapott (DLVR), amelyekkel még hatékonyabban modulálhatóak a feszültségek. Ezzel egy időben dinamikusan módosíthatóak az összekötők órajelei az alapján, hogy milyen sávszélességre van éppen szükség, ami szintén hozzájárul az energiahatékonyabb működéshez.
A SoC Tile esetében már említettük a két energiahatékonyságra optimalizált Crestmont processzormagot, amelyek feladata az, hogy az alacsony terhelést jelentő feladatokat futtassák, miközben a CPU Tile éppen energiatakarékos módban van. Az egyelőre nem derült ki, hogy ez a kétmagos tömb pontosan milyen teljesítménnyel bír, az viszont biztos, hogy jelentős szerepe van az energiahatékonyság javításában.
Ebben az új Thread Director is segít, ami most már nem a P-Core részleghez irányítja alapértelmezetten a feladatokat, mint korábban, hanem a két új E-Core processzormaghoz, amelyek a SoC Tile fedélzetén találhatóak. Amennyiben nagyobb teljesítményre van szükség, természetesen a gyorsabb processzormagokra mozgatja a rendszer a feladatokat, ám az nem derült ki, hogy ezt milyen gyorsan teszi, azaz rányomja-e a bélyegét a rendszer válaszkészségére és mennyivel növeli a késleltetést.
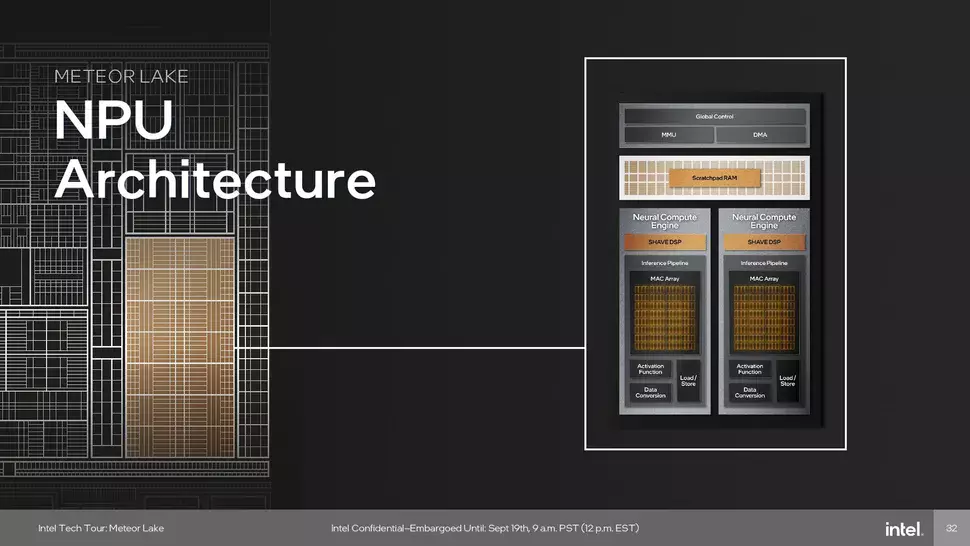
A SoC Tile tartalmaz még egy NPU-t, azaz neurális feldolgozó egységet, ami dedikáltan az AI terhelésformák kiszolgálására készült. Az AI feladatokat ezzel egy időben a CPU és az iGPU is végezheti, valamint van egy GNA motor is a kínálatban. Az NPU főként a háttérben futó feladatok kiszolgálásra készült, míg a processzor az alacsony késleltetésű, kisebb teljesítményt igénylő dedukciós feladatokra vethető be, a GPU pedig a nagyfokú párhuzamosítás mellett futó, nagyobb teljesítményű feladatok esetén jut szerephez. Egyes feladatok akár a GPU és az NPU együttes munkája mellett is futhatnak. A kisebb teljesítményt igénylő, főként audió-, videó- és képfeldolgozással kapcsolatos feladatok ezzel a megoldással helyben, a PC-n végezhetőek el, nem úgy, mint a nagy nyelvi modellek tréningezése, amihez jellemzően adatközpontok kellenek továbbra is.
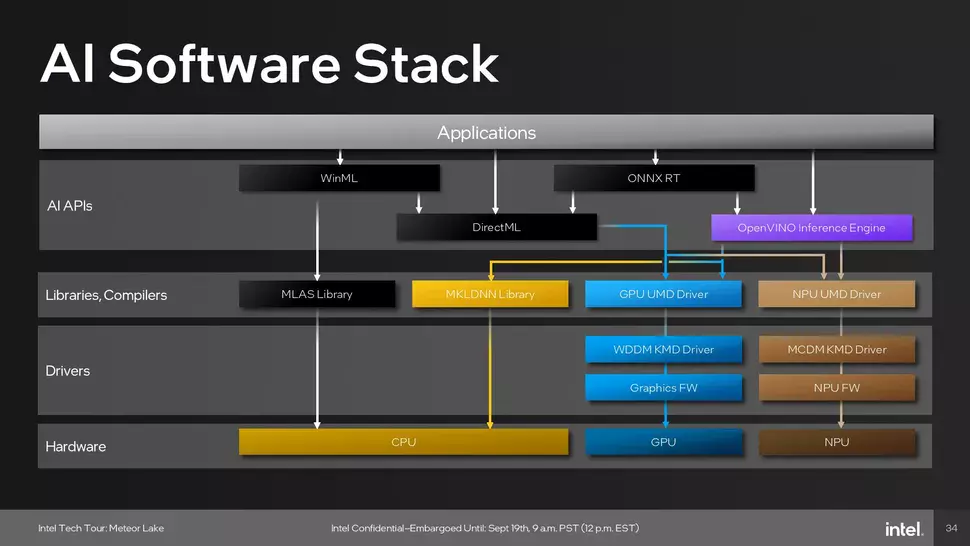
A Gaussian Neural Accelerator (GNA) tehát a Meteor Lake fedélzetén is helyet kap, ám a GNA-ra írt kódok egy része már az NPU-n is fut, ráadásul nagyobb hatékonysággal, így a GNA helyét idővel az NPU veheti majd át a következő generációs chipek fedélzetén. Maga az NPU egyébként DirectML, ONNX és OpenVINO támogatással egyaránt rendelkezik. A cél idővel az, hogy a különböző PC-s szoftverek hatékony dedikált AI gyorsítóval szerelt processzorokon futhassnak, igaz, ezekből az alkalmazásokból egyelőre még nem lehet Dunát rekeszteni, de ahogy a megfelelő processzorok rohamosan terjedni kezdenek a piacon, a megcélozható konfigurációk száma exponenciálisan növekszik, ami a szoftverek számának növekedését hozhatja.
Az I/O Tile
Ezzel el is érkeztünk az utolsó chiplet alapú építőkockához, ami az I/O Tile nevet kapta. Erre a lapkára azért volt szükség, mert a következő generációs Uncore dizájnnak nem csak előnyei, de hátrányai is vannak. Mivel a SoC Tile tartalmazza a DDR5-ös memóriavezérlőket és a PCI Express vezérlőket is, és a hozzájuk tartozó külső interfészeket csak a lapka két szélére lehet helyezni – a lapka másik két oldalát a többi lapkával való kommunikációra használják. Ez a dizájn behatárolja a lapka szélein kialakítható csatlakozások számát, ami miatt egy másodlagos I/O lapkát kellett készíteni, amellyel extra hely nyerhető a további PCI Express sávok és a Thunderbolt 4-es interfészek számára. Ez, vagyis az I/O Tile a legkisebb lapka a Meteor Lake processzorok esetében, ami csak az I/O funkciókat szolgálja ki, mint amilyen a Thunderbolt 4 támogatás és a PCI Express 5.0 támogatás. Ebben az esetben Thunderbolt 5 támogatásról sajnos még nincs szó.

A Foveros 3D
A fenti chipleteket a Foveros 3D tokozás fogja össze, ami egy költséghatékonyságra és alacsony fogyasztásra optimalizált gyártástechnológiával készül, ez az Intel 16 (22FFL). A passzív Foveros 3D interposer tetején foglalnak helyet a fentebb említett aktív csempék, amelyek mikro-érintkezőkkel kapcsolódnak ehhez a réteghez. A passzív interposer nem tartalmaz semmilyen logikai áramkört, csak a gyors és energiahatékony összeköttetés biztosításáról gondoskodik. A stabil tápellátás érdekében beágyazott MIM kondenzátorokat is tartalmaz a dizájn (500 nf/ négyzetmilliméter), így a nagyobb terhelés alkalmával is megfelelően működhet a rendszer.

Ezek az apró mikro-érintkezők immár 30 mikronnyi távolságra helyezkednek el egymástól, míg a korábbi megoldásnál még 55 mikron volt ez az érték, azaz jelentős előrelépés történt. A Foveros 3D négyzetmilliméterenként akár 770 ilyen mikro-érintkezőt is tartalmazhat, de a későbbiekben még tovább csökkentik az érintkezők távolságát, ugyanis jönnek a 25 és 18 mikronos megoldások is. Az Intel szerint a Foveros interconnect lapka milliméterenként 160 GB/s-os adatátviteli sávszélességet biztosít, a dizájn remekül skálázódik a további interconnectekkel, így nincs jelentősebb sávszélességgel vagy késleltetéssel kapcsolatos megkötés, ami miatt kompromisszumokra lenne szükség a tervezés során.
A Meteor Lake sorozat tagjairól egyelőre semmi konkrétumot nem árult el a vállalat, csak annyi biztos, hogy a mobil konfigurációkba szánt processzorok 2023. december 14-én rajtolhatnak el.
Szóba kerültek a következő generációs gyártástechnológiák és processzorok is
Az Intel vezetője egy speciális, Intel 20A gyártástechnológiával készülő szilícium ostyát is bemutatott, amelyen Arrow Laka processzorlapkák foglaltak helyet. Ez, vagyis az Arrow Lake várhatóan 2024 folyamán jelenik meg, és a dolgok jelenlegi állása szerint sikerül is tartani a céldátumot. A vállalat négy éven belül ötféle node-ot állít csatasorba, amelyek közül az Intel 4 már készen áll a gyártásra, és az Intel 3 is bevethető lesz az év vége felé.
Az Intel 20A az Intel 3 után érkezik majd és az Arrow Lake CPU chipletek alapjául szolgál. Ez a csíkszélesség számos újítást vezet be, amelyekkel az Intel az eddigieknél jobb pozícióba kerülhet a TSMC-vel vívott versenyben. A tranzisztorok esetében áttérnek a PowerVia Backside Power Delivery technológiára, ami a tápellátást a tranzisztorok hátuljára vezeti el, míg az adatok továbbítása a szokásos oldalon zajlik majd. Az újítás a mérnökök szerint számos előnnyel jár, például sűrűbb tranzisztortömbök építhetőek vele, valamint csökkenthető a szivárgási áram, amelynek köszönhetően magasabb órajel elérésére van mód.
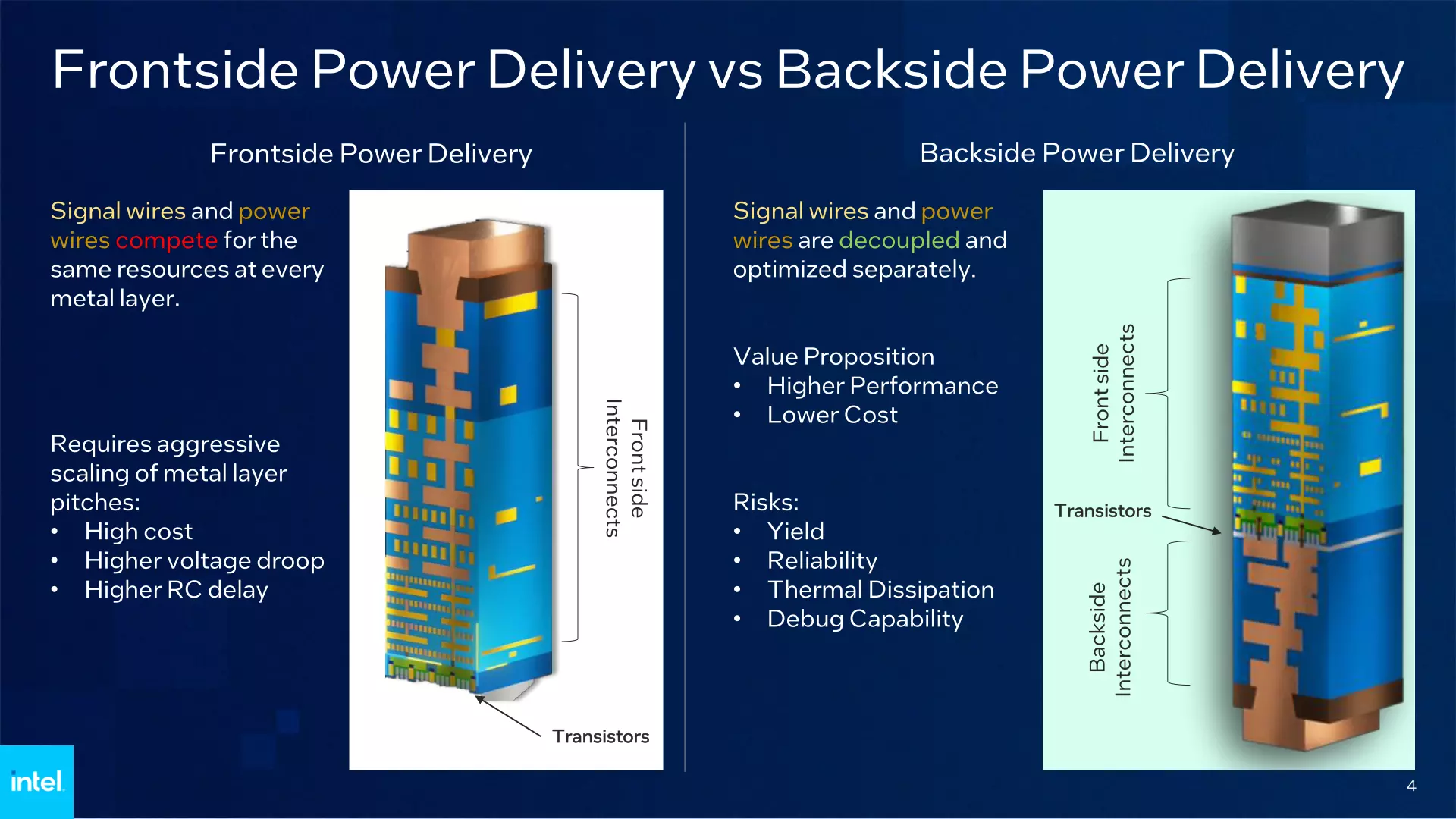
Ezzel együtt gyorsabb tranzisztor-kapcsolásra és sűrűbb jel-elvezetésre is lehetőség lesz a chip felső részén. A jeltovábbítás abból is profitál, hogy egyszerűbb lesz a jelvezetékek kialakítása, ami gyorsabb átvitelt eredményez alacsonyabb ellenállás és kapacitancia mellett. Ezt a technológiát az Intel már 2024 folyamán be akarja vezetni, míg a TSMC háza táján majd csak 2026-tól állhat csatasorba.
Az Intel 20A gyártástechnológiája a RibbonFet GAA technológiát használja, ami 2011, vagyis a FinFET bevezetése óta az első új tranzisztordizájnnak tekinthető. Ebben az esetben a dizájn négy darab egymásra rétegezett nanolemezt tartalmaz, amelyeket teljesen körül öleli majd a Gate, ami gyorsabb tranzisztorkapcsolást eredményez ugyanakkora meghajtóáram mellett, kisebb területen.

Ezzel egy időben a 18A gyártástechnológia fejlesztése is a tervek szerint halad, ennek bevetésére már 2024 második felében sor kerülhet. A TSMC-nél közben a GAA technológia majd csak 2025-ben érkezik, vagyis a tajvani félvezetőipari bérgyártó-óriás utolsóként vezeti be az új tranzisztor-technológiát, ami persze egyáltalán nem biztos, hogy baj – sőt.
Az Arrow Lake processzorokkal kapcsolatban sajnos semmilyen konkrétum nem hangzott el, vagyis egyelőre rejtély, hogy milyen magszámmal és milyen kiépítésben érkeznek majd. Itt igazából nem is ez volt a lényeg, hanem az, hogy az Arrow Lake a terveknek megfelelően érkezik és jól állnak a munkálatokkal a háttérben – kvázi megnyugtatták a befektetőket, minden rendben van.
Megmutattak viszont egy 15. generációs Intel Core processzorral szerelt noteszgépet, ami a Lunar Lake lapka köré épül. A demó alkalmával megláthattuk, hogyan bánik el az AI alapú terhelésformákkal az újdonság: a feladata az volt, hogy egy Taylor Swift stílusához hasonló nótát készítsen az AI. Ezt néhány másodperc alatt teljesítette is. Pat Gelsinger itt viccelődni kezdett a noteszgép bumfordiságával, majd kiderült, hogy a csúnya köntös igazából a legmodernebb hardvert rejti, ugyanis a noteszgép Lunar Lake mobil processzorral rendelkezik.

A Lunar Lake generáció tagjai várhatóan tovább viszik a több chipletből álló dizájnt, a CPU chiplet pedig 18A gyártástechnológiával készülhet. A CPU részleg a Lion Cove és a Skymont architektúrát alkalmazza majd – előbbi a P-Core, utóbbi pedig az E-Core részleg alapját adhatja. Arról egyelőre nincs hír hogy magszám terén nagyjából mire számíthatunk, de az már biztos, hogy energiahatékonyság terén áttörést hozhat az új fejlesztés, legalábbis az Intel szakemberei ezt állítják.

Az útiterven felbukkant a Lunar Lake után érkező Panther Lake is, ami 2025 folyamán jelenik meg. E processzorok gyártása már 2024 elején megkezdődhet, az viszont egyelőre rejtély, pontosan milyen felépítéssel rendelkeznek majd. Idővel persze erre is választ kapunk.
Az adatközpontok szerelmesei is kaptak némi csemegét
A show alkalmával előkerült egy 6. generációs Intel Xeon Scalable sorozatú processzor, ami nem kevesebb, mint 288 processzormaggal rendelkezik. A Sierra Forest lapka köré épülő termék fedélzetén csak és kizárólag energiahatékonyságra optimalizált processzormagok foglalnak helyet. A Sierra Forest esetében eddig arról volt szó, hogy egyetlen chiplet 144 processzormagot tartalmazhat, de a Granite Rapids fejlesztés, ami már P-Core típusú processzormagokat használ, akár három chiplettel is felvértezhető, így nem akkora meglepetés a 288 magos Sierra Forest CPU.

Az újdonság Intel 3 gyártástechnológiával készül és két I/O chipletet is tartalmaz, amelyek viszont már Intel 7 alapokra támaszkodnak, így rugalmas architektúrát biztosítanak ahhoz, hogy több chiplet hozzáadásával skálázható legyen a processzormagok száma. A Sierra Forest és a Granite Rapids ugyanabba a platformba illeszkedik és ugyanazt a dizájnt használja, így elméletben akár három Sierra Forest CPU chiplet is kerülhet egy tokozáson belülre, ami 432 processzormagot eredményezne. A megvalósítás persze nem ilyen egyszerű, hiszen ennyire sok processzormagnál a TDP keret, a rendelkezésre álló kommunikációs sávszélesség és a hűtés egyaránt problémás lehet.
Ne is szaladjunk ennyire előre, hiszen a következő fejlesztés a szerverprocesszorok szegmensében az Intel térfelén az Emerald Rapids lesz, ami az 5. generációs Intel Xeon Scalable sorozatot erősíti, és ugyanúgy 2023 december 14-én jelenik meg, mint a fentebb említett Meteor Lake sorozat.
Végszó
Az Intel Innovation Event 2023 egy kétnapos rendezvény, ami több előadást is tartalmaz, így biztosra vehetjük, hogy a fentieken kívül hamarosan egyéb érdekességekről is szó esik. Amennyiben így lesz, azokról természetesen be fogunk számolni az elkövetkező időszakban.
