Az Nvidia következő generációs GeForce RTX videokártyái, amelyek a GeForce RTX 3000-es sorozatot erősítik, szeptember elsején mutatkoztak be a nagyérdemű számára, ugyanis ezen a napon tartotta a vállalat speciális GeForce rendezvényét.
Az eseményt egy hosszas visszaszámlálás előzte meg, amelynek során az elmúlt 21 év legfontosabb állomásait vették sorra mind a GeForce sorozat tekintetében, mind pedig a játékok terén – jó volt velük nosztalgiázni. A show alkalmával összesen háromféle videokártyáról esett szó: a szeptember 17-én érkező GeForce RTX 3080-ról, a szeptember 24-én debütáló GeForce RTX 3090-ről, valamint az október 15-én megjelenő GeForce RTX 3070-ről.

Ezek a termékek sorrendben 699, 1499 és 499 dollárba kerülnek majd listaáron, de a partnerek egyedi felépítéssel és/vagy gyárilag megemelt órajelekkel büszkélkedő videokártyái ezeknél az összegeknél egészen biztosan drágábbak lesznek. Az RTX 3000-es sorozattal kapcsolatos legfontosabb információkat szeptember elsején már tálaltuk, most azonban eljött az ideje annak is, hogy egy kicsit mélyebbre ássunk: az elkövetkező néhány bekezdésben sorra vesszük, pontosan milyen újításokra is lehet számítani.
Az Ampere architektúra meghódítja a gamer videokártyák szegmensét
Az Nvidia az első Ampere alapú GPU-t, a GA100-as modellt már hónapokkal ezelőtt bemutatta, ám ez, illetve az azonos névvel ellátott gyorsítókártya nem a gamereknek készült, hanem egy speciális piaci területre, az adatközpontok szegmensébe szánja az Nvidia. Lényegében egy AI feladatok, illetve általános számítások gyorsítására alkalmas termékről van szó, ami nem rendelkezik a gamer videokártyák extráival, például nincsenek benne RT magok, csak Tensor magok, cserébe viszont olyasmire is képes, amire a gamer videokártyák nem: nagyon magas dupla pontosságú számítási teljesítményt kínál, hála az FP64-es egységeknek – utóbbiak a konzumerpiacra szánt videokártyákból hiányoznak, de ezt később majd részletesebben is kifejtjük.
Ezzel együtt a GA100 természetesen egyéb területeken is a GeForce sorozatba szánt termékek fölé emelkedik, de jellemzően csak olyanokban, amelyek az adott paici szegmens igényeihez passzolnak.

A gyorsítókártyákra szánt GA100-as GPU esetében a TSMC 7 nm-es csíkszélességét használta az Nvidia, maga a GPU pedig összesen 128 SM tömbbel rendelkezik, de ezekből csak 108 aktív, így csak 6912 CUDA mag várja a feladatokat. A fedélzeti memória szerepét ebben az esetben HBM2-es lapkák töltik be, amelyek ugyan drágábbak GDDR6-os, illetve GDDR6X típusú társaiknál, cserébe viszont óriási memória-sávszélességgel ajándékozzák meg a rendszert.
A szóban forgó GPU aktuális kiadása csak 5 ilyen HBM2-es memóriaszendvicset tud használni, de gyakorlatilag hattal is megbirkózna, vagyis 40 GB helyett akár 48 GB-nyi fedélzeti memóriával ellátott kártya is készülhetne, ha a letiltott SM tömböket és velük együtt a hatodik memóriavezérlőt is engedélyeznék. Persze ebben a kiépítésben sem kell sajnálni a terméket, ugyanis 1555 GB/s-os maximális memória-sávszélességre képes, ami a GeForce RTX 3080-éhoz képest lényegében bő kétszeres értéknek tekinthető.

A konzumerpiacra persze nem ezt a GPU-t hozza el az Nvidia, hanem a GA102-es és a GA104-es modelleket, legalábbis egyelőre, amelyek némi extrával is rendelkeznek. Ezeknél a grafikus processzoroknál már nem a TSMC 7 nm-es, hanem a Samsung egyedi, az Nvidia igényeihez igazodó 8 nm-es gyártástechnológiája jut szerephez, valamint itt már az RT magok sem hiányoznak a kínálatból, nem úgy, mint a GA100-nál. A GA102 teljes kiépítésben 84 SM tömbbel rendelkezik, de a GeForce RTX 3090 esetében csak 82, míg a GeForce RTX 3080-nál csak 68 aktív. Hogy miért? A Titan RTX helyére érkező GeForce RTX 3090 esetében a két letiltott SM tömb jóvoltából javítható a kihozatali arány, míg azok a GPU-k, amelyeknél minden SM tömb hibátlanul működik, egy későbbi csúcskártyára is kerülhetnek, amennyiben lesz rá lehetőség.
A gamereknek szánt GPU-k természetesen nem a HBM2-es memórialapka-szendvicseket alkalmazzák, mert azok bonyolítanák a dizájnt és alaposan megemelnék a kártyák árait. Éppen ezért az Nvidia a Micron segítségével egy új memóriatípust fejlesztett, ami a GDDR6 alapjaira épül, ám kettő helyett már négy jelszintet tud kezelni egy órajel alatt, ami igen komoly mértékben megemelte az effektív memória-sávszélességet. Erről később részletesebben is említést teszünk, egy külön bekezdést szentelve a témának. Annyit még lényeges megemlíteni, hogy a GeForce RTX 3080 esetében 760 GB/s-os memória-sávszélességet eredményez az új memória a 320-bites memória-adatsínnel és a 19, GHz-es effektív memória-órajellel karöltve, míg a GeForce RTX 2080 csak 448 GB/s-os memória-sávszélességgel gazdálkodhatott.
A GDDR6X memóriával kapcsolatos részletek kitárgyalása előtt még érdemes tisztázni, milyen architekturális változásokat vezet be az Ampere a Turinghoz képest, azaz miért duplázódott meg a CUDA magok száma és miért nőtt akkorát az egyszeres pontosságú számítási teljesítmény (FP32). A Turingnál az Nvidia bevezette a konkurens FP32+INT támogatást, vagyis az FP32-es lebegőpontos művelet mellett egy INT32-es műveletsor elvégzésére is volt lehetőség.
Ezzel szemben az Ampere esetében ennek az INT32-es egységnek bővült a funkcionalitása, így már FP32-es lebegőpontos műveletet is el tud végezni a csak FP32-es számításokra szánt egységgel párhuzamosan, amennyiben nincs éppen INT32-es feladat, így lényegében jelentősen megnőtt az elméleti maximális számítási teljesítmény. Ez viszont csak ideális esetben érhető el, ugyanis ehhez tisztán FP32-es műveletekre van szükség, márpedig a játékoknál ilyen ideális eset egyszerűen soha nincs, mindig jelen vannak integer alapú számítások is a különböző munkafolyamatokban.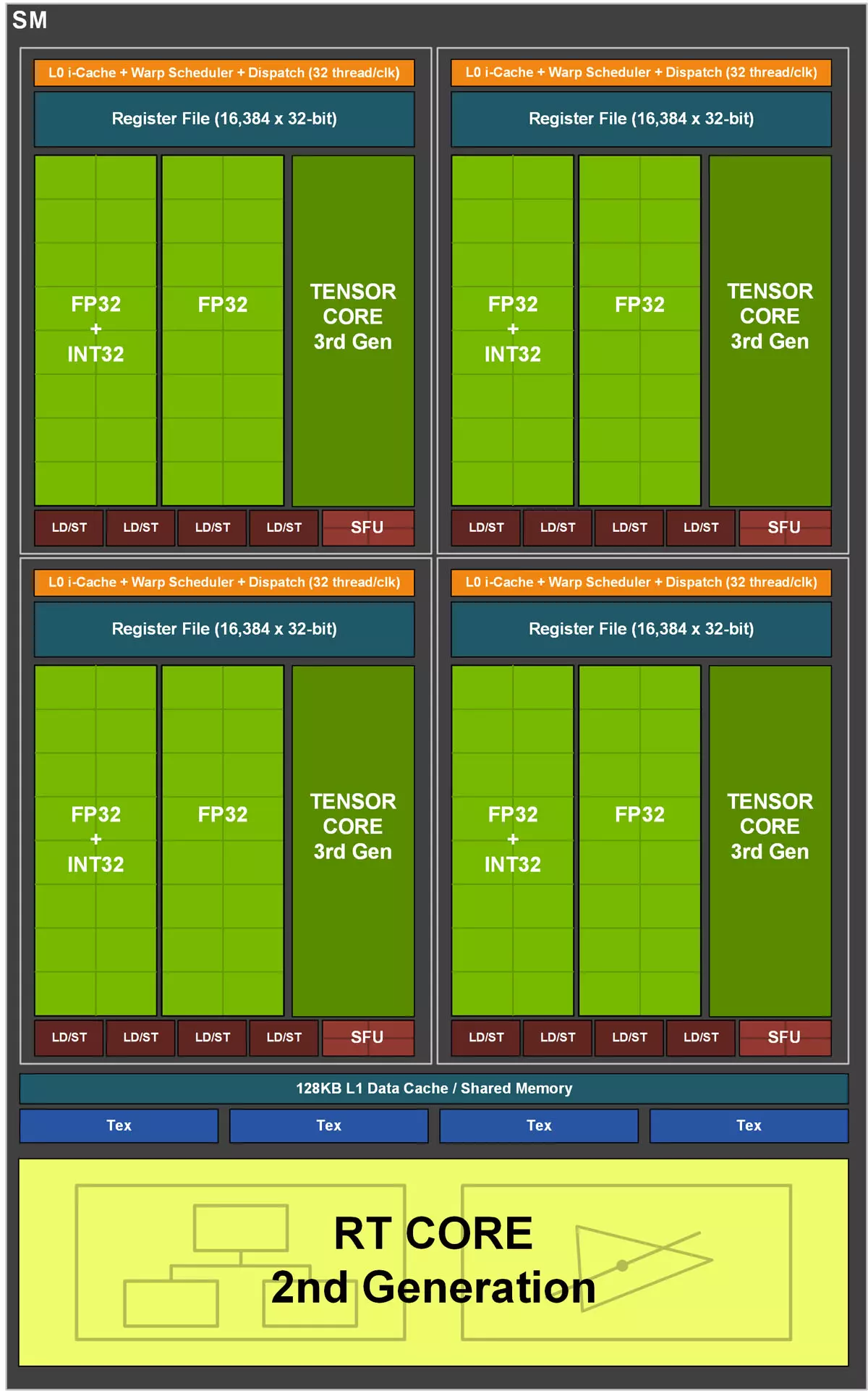
Az Nvidia a Turing kapcsán anno azt állította, amikor az újítás előnyeit ecsetelték, hogy a játékok futásakor a CUDA magokat érintő számítási feladatoknak nagyjából 35%-át, azaz lényegében egyharmadát teszik ki az integer számítást igénylő munkafolyamatok, márpedig ez azt jelenti, hogy ezek az SM tömbök FP32+INT részlegének több, mint felét foglalják el, már ami a számítási kapacitást illeti. Ezt az Nvidia aktuális számai alá is támasztják, ugyanis hiába lett háromszor magasabb az FP32-es számítási teljesítmény az RTX 3080 esetében az RTX 2080-hoz képest (29,77 TFLOP/s vs. 10,1 TFLOP/s), a tényleges gyorsulás a két kártya között játékok alatt maximum kétszeres lehet.
Hogy még világosabb legyen a helyzet, nézzük, milyen számítási teljesítményekkel bír az RTX 2080 és az RTX 3080. Előbbinél, vagyis az előző generációs zászlóshajónál 10,1 TFLOP/s-os FP32-es, illetve 10,1 TFLOP/s-os INT32-es számítási teljesítménnyel lehet gazdálkodni. Ehhez képest az RTX 3080 már 29,97 TFLOP/s-os maximális FP32-es számítási teljesítményre képes, ha kizárólag FP32-es feladatokat kap a GPU. Az INT32 teljesítmény 15 TOP/s, amihez 15 TFLOP/s FP32-es teljesítmény társulhat egyidejűleg, ha mindkét részleget csúcsra járatják. Arra sajnos nincs mód, hogy a GPU INT32+FP32 egységei integer és lebegőpontos műveletet végezzenek egyidejűleg, így ezen a téren marad a vagy-vagy állapot, ahogy azt már emlíettük.
A fenti példa alapján, vagyis 35% körüli INT32 terhelés alkalmával, ami tipikus a játékok alatt az Nvidia szakemberei szerint, az FP32-es teljesítmény 15 TFLOP/s, ha csak az FP32-es egységeket vesszük, az INT32+FP32 részlegből pedig le kell venni egyharmad teljesítményt az INT32 műveletek miatt, így nagyon optimális esetben 10 TFLOP/s maradhat, ám az 5 TFLOP/s-os szintre is lehet példa. Vagyis valahol 20-25 TFLOP/s között lesz az elérhető FP32-es számítási teljesítmény, de többnyire inkább a 20 TFLOP/s környékére kell felkészülni. A tesztek ezt a képet úgyis tisztába fogják tenni.
Annak érdekében, hogy az új felépítést, vagyis az FP32-es funkcióval ellátott INT32-es egységek munkáját segítse a gyártó, a regiszterek méretét ugyan nem növelte, de az első szintű gyorsítótár (L1 Cache) sávszélességét duplájára emelték, így az órajelenként 128 bájtnyi adat feldolgozására képes. A Turing esetében az L1 Cache 64 KB-os volt, az GeForce sorozatú Ampere grafikus processzoroknál már 128 KB-os kapacitással bír, míg a gyorsítókártyák piacára szánt GA100-as GPU esetében ennél is nagyobb, 192 KB-os L1 Cache áll rendelkezésre.
Az újítások hatására a GeForce RTX 3080-ban lényegében háromszor több FP32 számítás potenciál rejlik, másfélszer több INT számítási potenciállal rendelkezik, valamint 1,53x nagyobb memória-sávszélesség elérésére képes, ám a háromszoros teljesítményt biztosan nem látjuk viszont valós feladatok alkalmával, pont a fentiek miatt, még akkor sem, ha javult a memória-tömörítés hatásfoka, ami az effektív memória-sávszélesség tényleges kihasználtságát növelni tudja. A háromszoros előnyt csak és kizárólag akkor lehetne lemérni, ha csak és kizárólag FP32-es számításokkal operáló teszttel próbálkozunk, ami az elméleti maximális FP32-es számítási teljesítmény elérésére koncentrál, a valós teljesítmény szemszögéből azonban ennek nincs sok értelme.
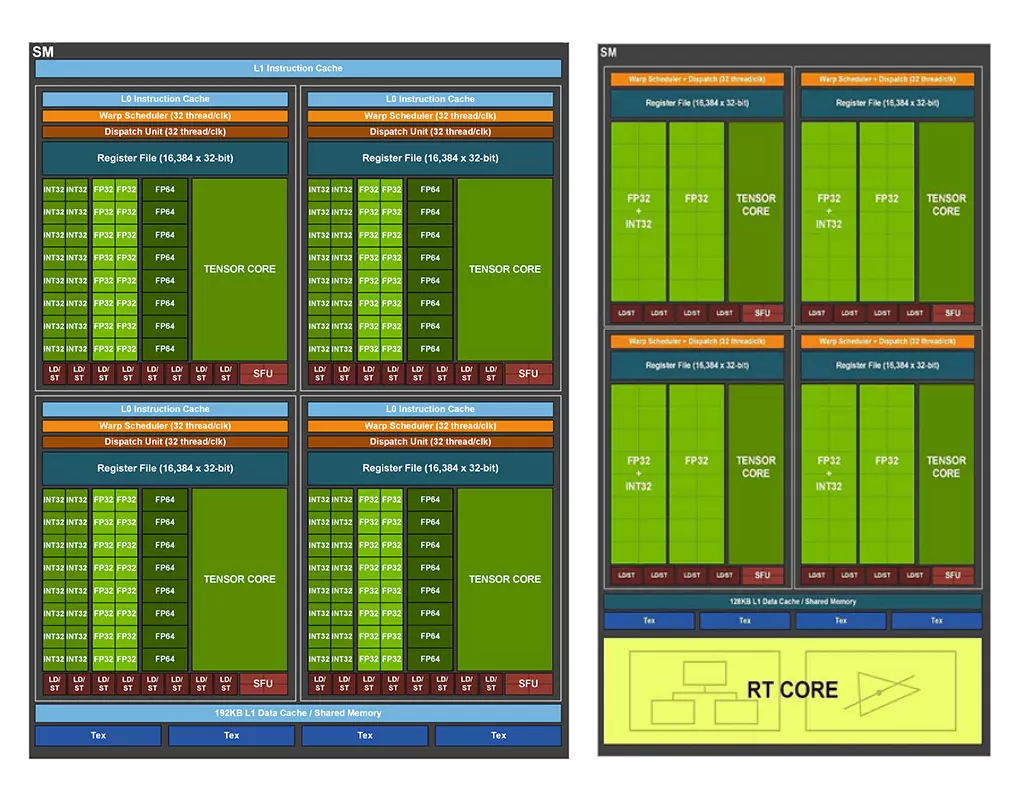
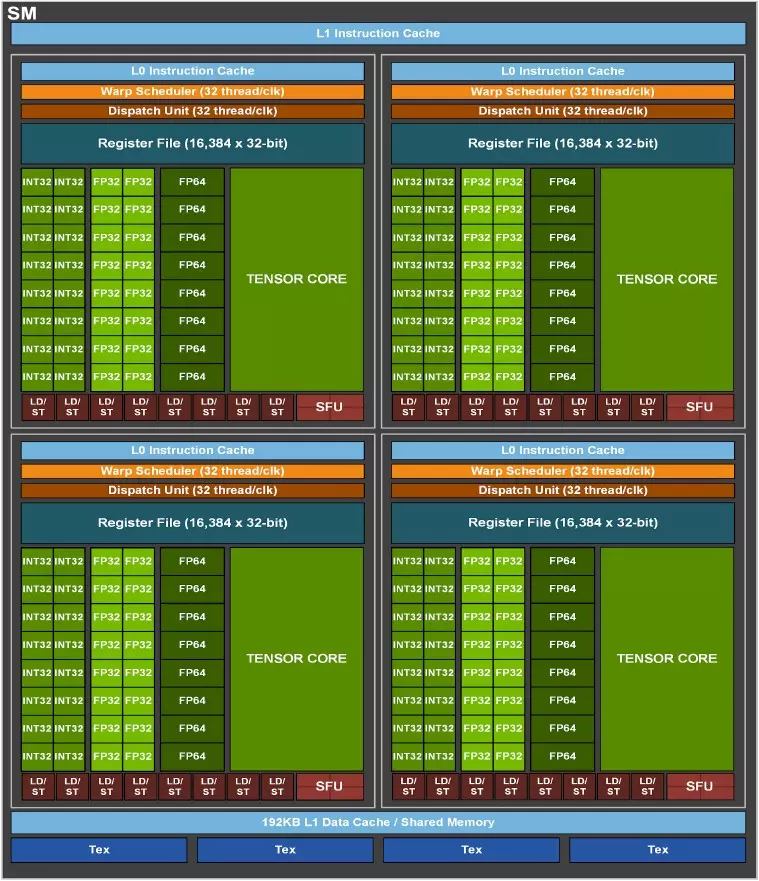
A gamer videokártyákba szánt Ampere SM tömbjére pillantva azt láthatjuk, hogy az SM tömbben a megduplázott számítási kapacitás ellenére még mindig négy warp ütemező foglal helyet, ám az egyes alegységek már 32 FP32-es CUDA maggal rendelkeznek, amelyek közül 16 képes FP32+INT32 matematikai műveletek végrehajtására – természetesen vagy-vagy alapon, nem egyszerre. Az általános számítási feladatok és az AI gyorsításra szolgáló GA100-as Ampere esetében egy ilyen SM tömb úgy nézett ki, hogy egyenkét 16 darab FP32-es és INT32-es egységet tartalmazott, plusz ezek mellett még nyolc darab FP64-es, azaz dupla pontosságú számításokra kihegyezett egység is jelen volt a tömbben, ahogy az a mellékelt blokkdiagramon is látszik.
Visszakanyarodva a GeForce sorozatba szánt Ampere SM tömbre, azt láthatjuk, hogy az SM tömbben található minden egyes alegység tartalmaz még egy harmadik generációs Tensor magot, négy darab Load-Store egységet, valamint egy regisztert is. Négy ilyen alegység alkot 128 FP32-es egységet, amelyek közül 64 képes FP32+INT32 műveletek elvégzésére, a másik 64 csak FP32-es műveleteket tud végrehajtani. Minden egyes SM tömb kapott egy második generációs RT magot is, ami a sugárkövetésért felel, valamint van még a tömbben 128 KB-nyi első szintű gyorsítótár és négy textúrázó egység is.
Az SM tömbök első szintű gyorsítótára konfigurálható, azaz egy része lehet L1 Cache, míg egy másik része megosztott memória: például 64 KB-nyi L1 Cache és 64 KB-nyi megosztott memóriaként is működhet, öt egyéb beállítási lehetőség mellett, ami a compute mode esetében sok előnnyel járhat. Az RTX 3090 fedélzetén 10496 KB-nyi aktív L1 Cache dolgozik (82 x 128 KB), míg az RTX 3080 esetében ez a szám 8704 KB (68 x 128 KB). A Turinghoz képest tehát nagyjából 33%-kal nőtt az L1 Cache és a megosztott memória kapacitása, ami segíthet a késleltetések csökkentésében.
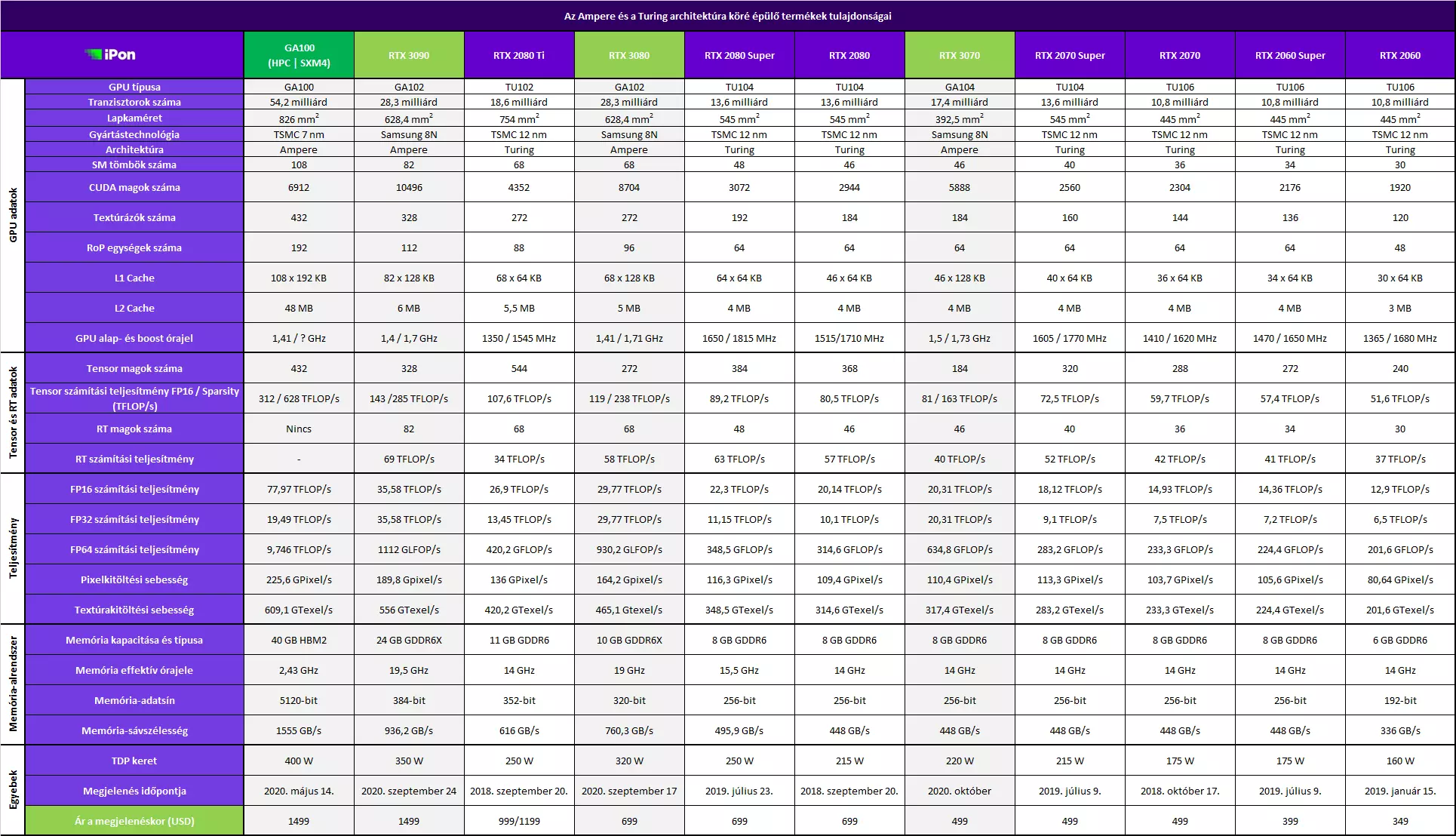
Az SM tömbök kettesével alkotnak egy textúrafeldolgozó egységet (TPC), amelyekből a GeForce RTX 3080 esetében 34 áll rendelkezésre, azaz 68 aktív SM tömbről beszélhetünk, amelyek 6 grafikai feldolgozó fürtöt (GPC) alkotnak. A GPC tömbök között a GigaThread Engine osztja el a feladatokat, ami a PCI Express 4.0 x16-os csatolóval van kapcsolatban. Ezeken felül némi L2 cache is rendelkezésre áll a GPC fürtök számára, valamint a memória-adatsín is szerepel a képletben, ami a GeForce RTX 3080 esetében 320-bites, vagyis 10 darab 32-bites csatornával dolgozik a rendszer.
Fontos kiemelni, hogy az RTX 3080 esetében nincs NVLink támogatás, míg a GeForce RTX 3090 már ezzel a Multi-GPU csatlakozóval is fel lett vértezve. A GeForce RTX 3090 egyébként 82 SM tömbbel, azaz 41 TPC-vel rendelkezik, míg a memória-adatsín 384-bites, ám itt egy 32-bites csatornára két memórialapka kapcsolódik, azaz 16-16-bites sávot használhatnak, hiszen a 12 csatornára 24 lapka jut a 24 GB-os kapacitás miatt Ezt persze 12 lapkával is meg lehetne oldani, ha lennének már 16 Gb-es, azaz 2 GB-os GDDR6X memóriachipek. Az SM tömbök számának köszönhetően itt már 10490 CUDA mag áll rendelkezésre. Az L2 Cache egyébként memória-vezérlőnként 512 KB-os kapacitással bír, ami a GeForce 3080 esetében 5120 KB-ot, a GeForce RTX 3090 esetében pedig 6144 KB-ot jelent.
A GPU kapcsán említést érdemel még az RT és a Tensor magok fejlődése is. Az RT magok esetében a háromszög-kereszteződések vizsgálata kétszeres sebességgel történik, mint az első generációnál, a Tensor magok pedig kétszer nagyobb matematikai számítási teljesítményre képesek, ami részben a High Sparsity támogatás bevezetésének köszönhető. Erről a két témakörről még később említést teszünk, most azonban beszéljünk egy kicsit a GDDR6X fedélzeti memóriáról – egy nagyon rövid kitérő után.
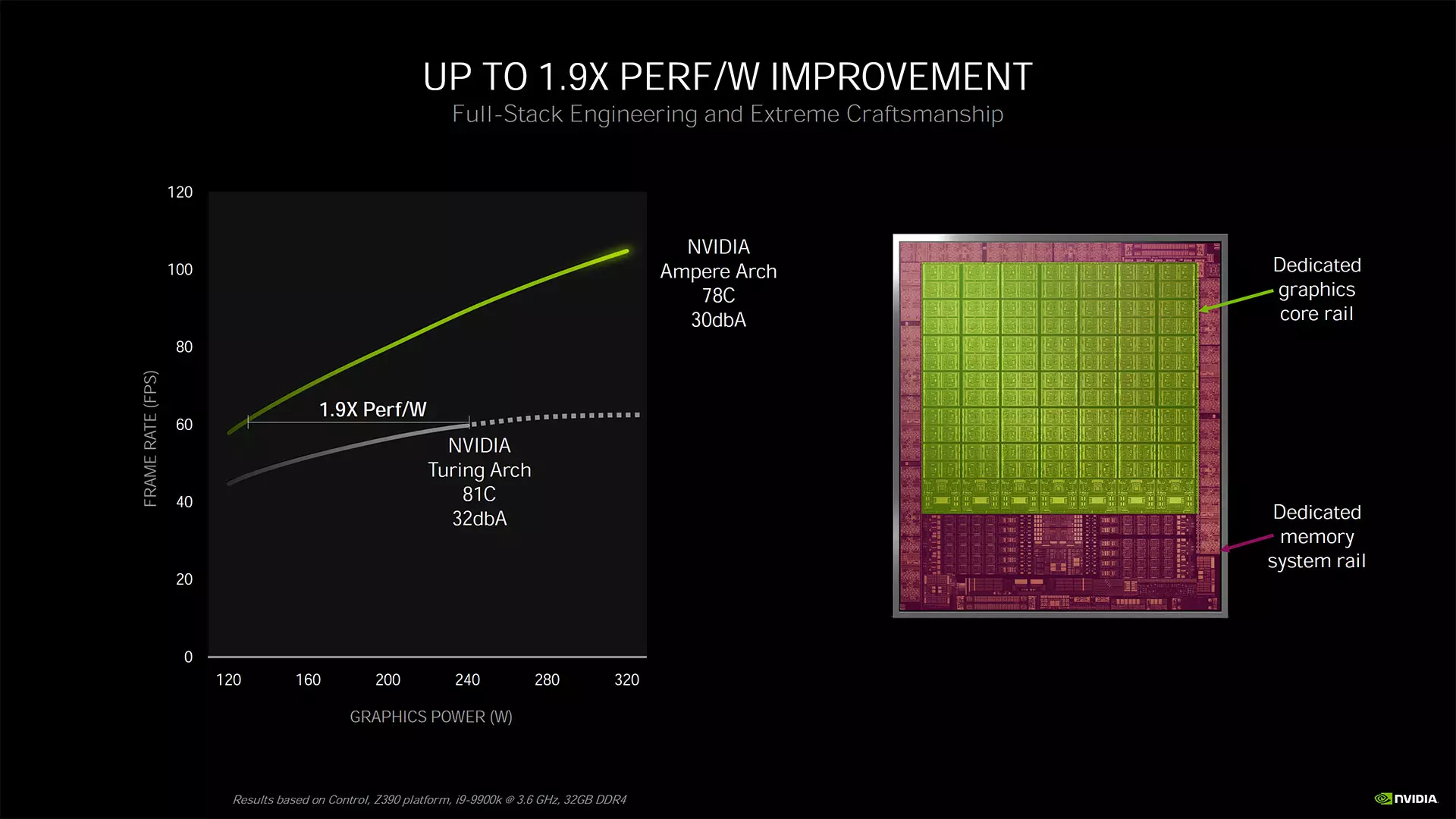
Érdekesség még is, hogy az Ampere architektúra köré épülő GeForce videokártyák esetében 1,9x-es előrelépésről beszélt az Nvidia energiahatékonyság terén, amit úgy kell érteni, hogy ha 60 FPS-re korlátoznak egy Ampere és egy Turing GPU-t, akkor az Ampere ugyanazt a teljesítményt az Nvidia szerint 47%-kal alacsonyabb fogyasztás mellett tudja elérni.
GDDR6X, a Micron és az Nvidia együttműködésének gyümölcse
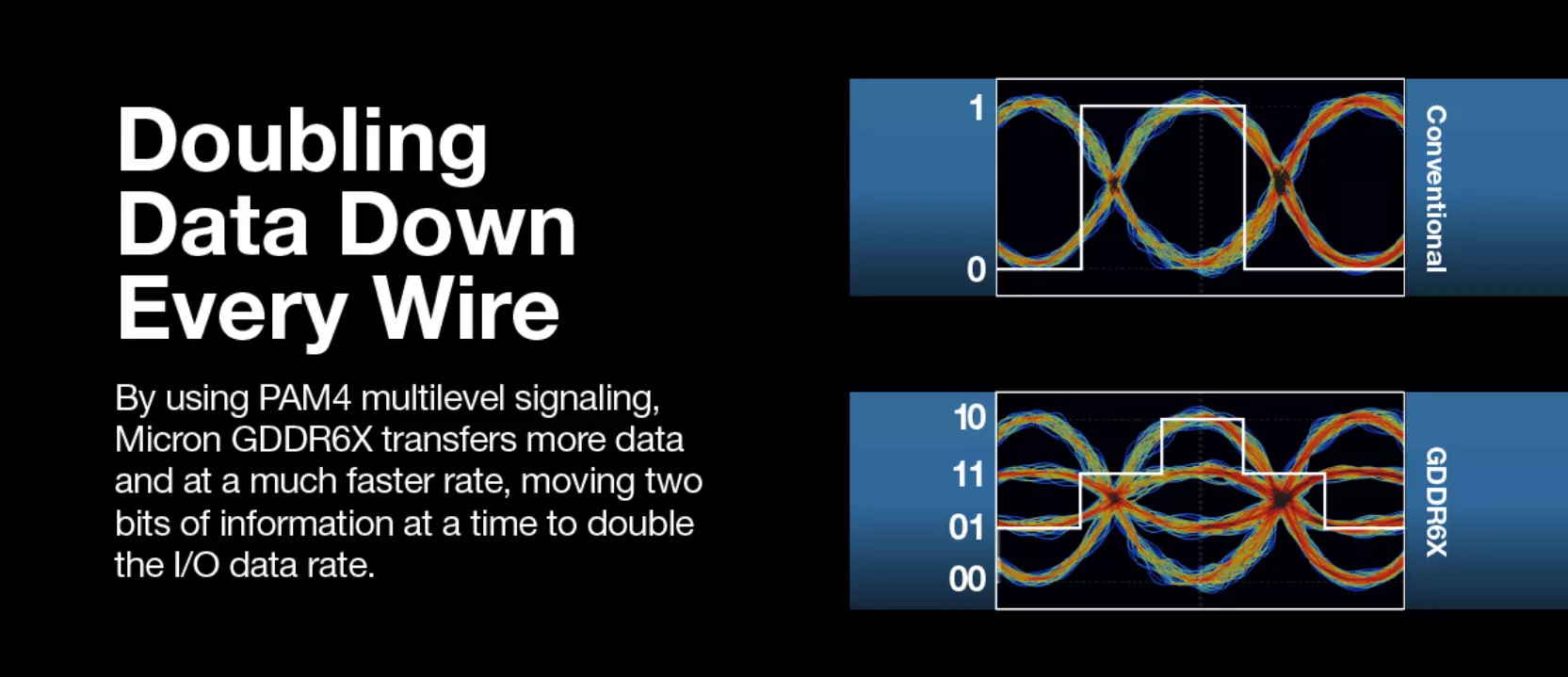
Ez az új memória-technológia lényegében a GDDR6-os szabvány kiegészítésének tekinthető, hiszen arra alapoz, viszont nem egy szabványos megoldás, legalábbis a JEDEC egyelőre nem szabványosította, így csak az Nvidia számára érhető el a Micronnal való együttműködés részeként. A GDDR6 esetében egy órajel alatt lényegében két érték továbbítására volt lehetőség (0/1), ám a GDDR6X esetében a több jelszintet használó PAM4 technológiának köszönhetően négy érték is továbbítható egy órajel alatt (00,01,10,11), vagyis ugyanakkora adatsín mellett kétszer több adat vándorolhat egyik helyről a másikba az NZR kódoláshoz képest.
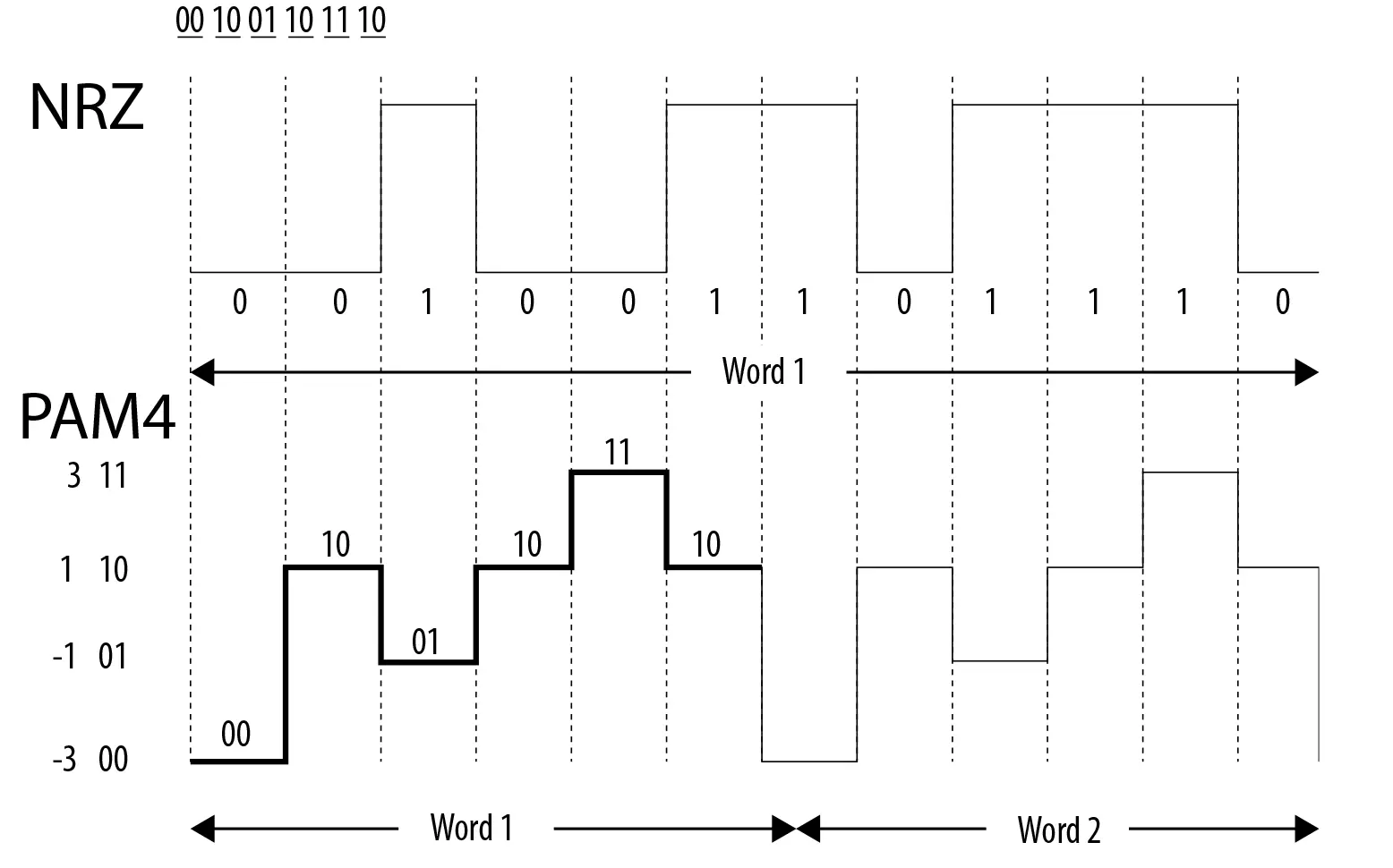
A Pulse-Amplitude Modulation 4 nem egy új technológia, de eddig lényegében csak a hálózatok szegmensében használták, ám a PCI-SIG is felfigyelt rá nemrégiben, így a PCI Express 6.0-s szabvány részeként is találkozhatunk majd vele. A PAM4 tehát összességében elég komoly előrelépést hoz az eddigi NZR-hez képest, igaz, működéséhez nagyon tiszta és erős jelre van szükség, de ez igazából nem probléma, hiszen a GDDR6 esetében a magas buszsebesség miatt eddig is komoly követelményeket támasztottak a jeltovábbítás minőségével, jel/zaj arányával és stabilitásával szemben.
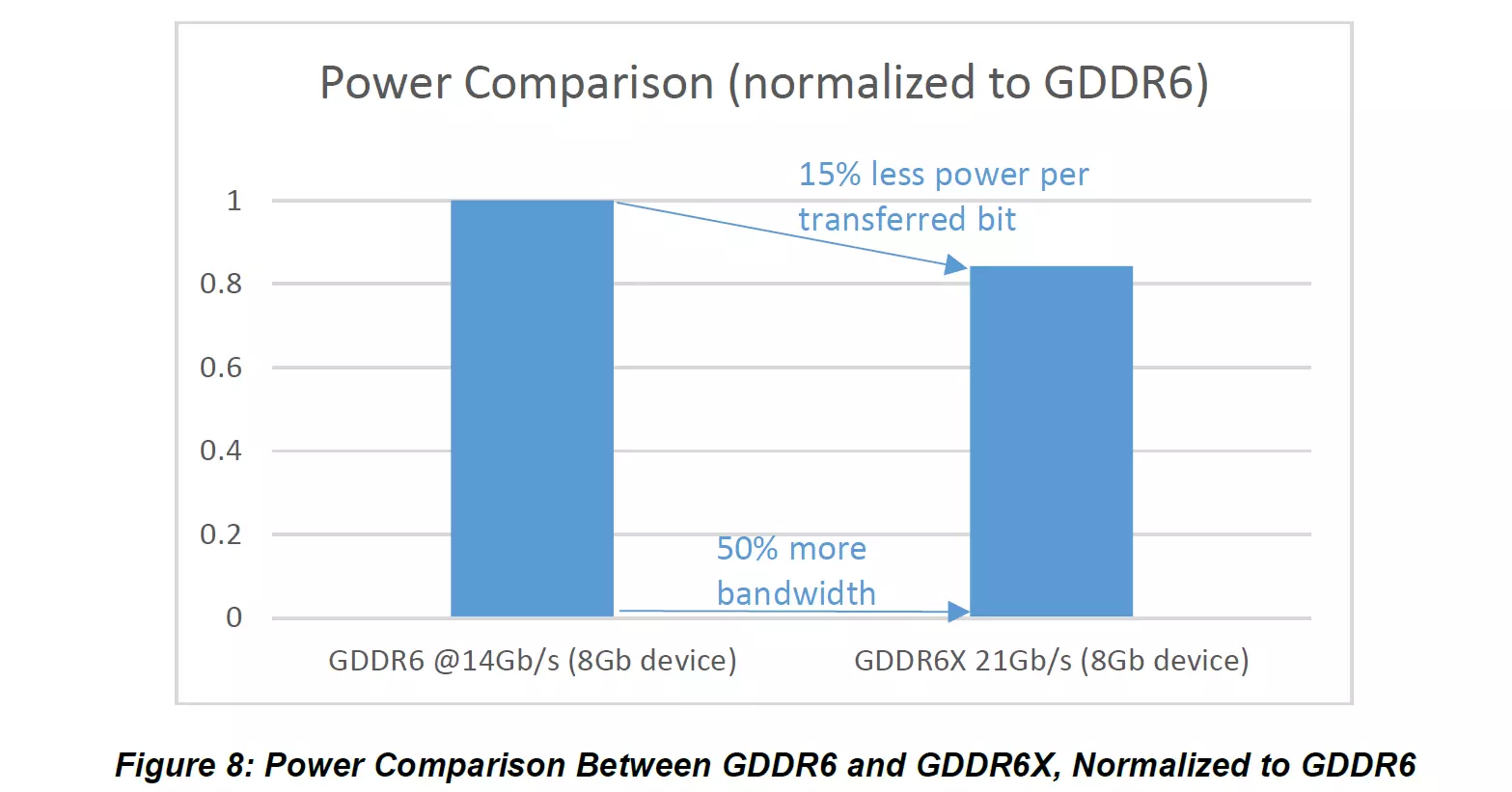
Érdekesség egyébként, hogy a GDDR6X memóriát használó GeForce-ok üresjáratban képesek visszaváltani NZR kódolásra annak érdekében, hogy fogyasztást spóroljanak. És a memória-vezérlő is meglehetősen okos, ugyanis EDR (Error Detection and Replay) támogatással látták el, vagyis ha a memória-alrendszer hibát észlel a jeltovábbítás során, ismét próbálkozni fog, egészen addig, míg a továbbítás hibátlan és sikeres nem lesz. Ez a funkció például a tuning alkalmával jöhet jól, ám egyben azt is jelenti, hogy a tuning alkalmával nem feltétlenül emelkedik majd a teljesítmény a sorozatos korrekció miatt.
Megemelt órajel alkalmával ugyanis az EDR szükség esetén működésbe léphet és megóvhatja a GPU-t a memória-hibákból eredő összeomlásoktól, ám ez a teljesítmény csökkenését is eredményezi. Hogy ennek mértéke mekkora lesz? A tesztekből mindenképpen kiderülhet. A memória vezérlő egyébként tréning-algoritmust is kapott, ami természetesen átesett némi fejlesztésen. Az algoritmus most már bizonyos időközönként tréninget hajt végre, így alkalmazkodni tud a környezet változásaihoz, mint például az elektromágneses interferenciához és a hőmérséklet-változásokhoz is.
Az újítások hatására, valamint az órajel-emeléseknek köszönhetően a 19,5 Gbps-os GDDR6X memórialapkákat használó RTX 3090, amely 384-bites memória-adatsínt kapott, közel 940 GB/s-os memória-sávszélességre képes, ami már nincs messze a jóval drágább HBM2-es memórialapkákkal elérhető memória-sávszélességtől – utóbbi esetben 4096-bites adatsín képezte az összehasonlítás alapját.
A második generációs RT és a harmadik generációs Tensor magok előnyei
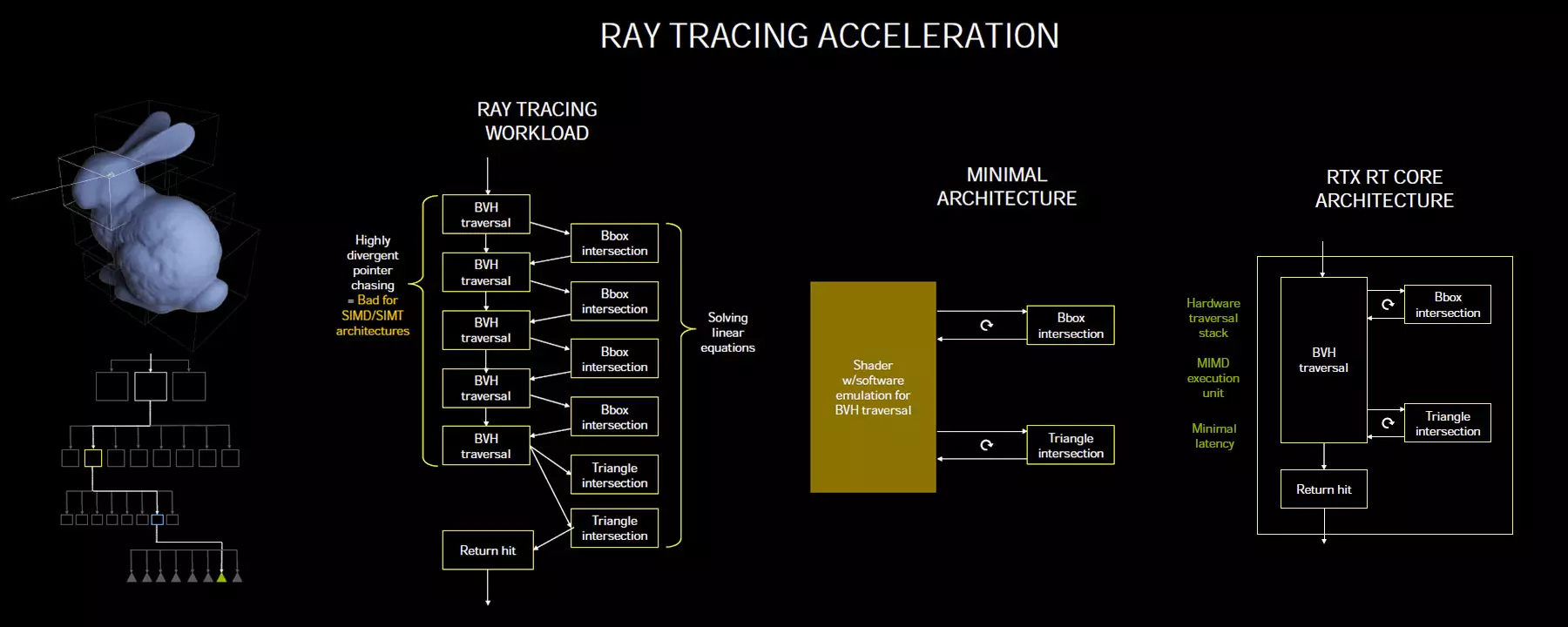
Az Nvidia a Turing generációval mutatta be a Ray Tracing magokat, amelyek lényegében fixfunkciós hardverként foghatóak fel, speciálisan arra kifejlesztve, hogy gyorsítsák a sugárkövetéssel kapcsolatos számításokat. A sugárkövetés kapcsán leegyszerűsítve azt vizsgálja a rendszer, hogy egy adott pontból, a színpad egy adott fényforrásából érkező fénysugár merre halad, hol metszi az adott „dobozokat”, azaz poligoncsoportokat, majd az utat tovább követve további vizsgálatokat végez, míg el nem jut addig a pontig, amíg érdemes követni az utat.
Ezt a koncepciót egy korábbi World of Tanks hírünkben már felvázoltuk, viszonylag jól érthető ábrákkal és magyarázattal, amikor a Ray Tracing funkció bevetéséről esett szó. A sugárkövetés gyorsítására az Nvidia szerint nem jók az SIMD, azaz a stream processzorokra támaszkodó megoldások, ugyanis elég látványos teljesítményhátrányt okozhat ez a fajta megoldás – itt valószínűleg az AMD-re és az RDNA2-re utaltak. Szerintük az RT magok, ahol hardveres BCH Traversal Stack, illetve célhardverként funkcionáló MIMD végrehajtóegység is rendelkezésre áll, valamint a késleltetés is alacsonyabb, sokkal jobban megfelelnek a feladatnak – végső soron jobb teljesítményre képes velük a rendszer.
Hogy az Nvidia megoldása tényleg jobb-e, mint az érkező RDNA 2 architektúra sugárkövetéssel kapcsolatos technológiája? Ez majd csak akkor derül ki, ha az új AMD videokártyák megjelentek, és az első független tesztek keretén belül sor került a szükséges összehasonlítások elvégzésére.
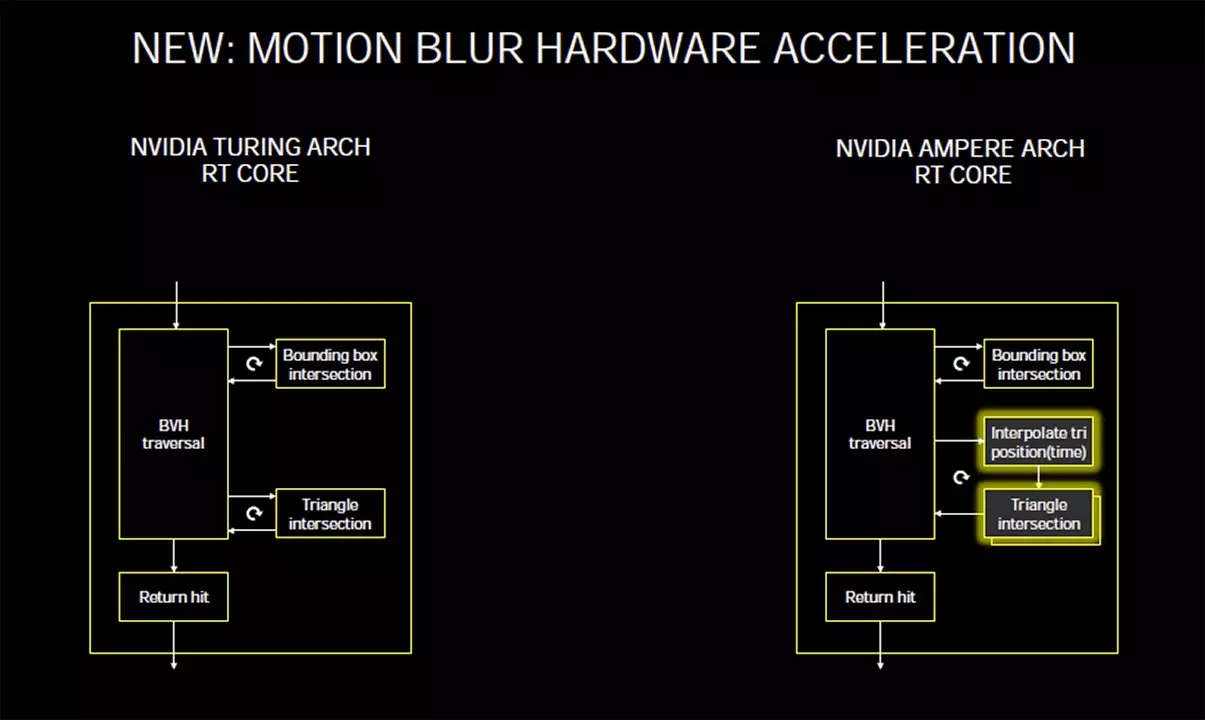
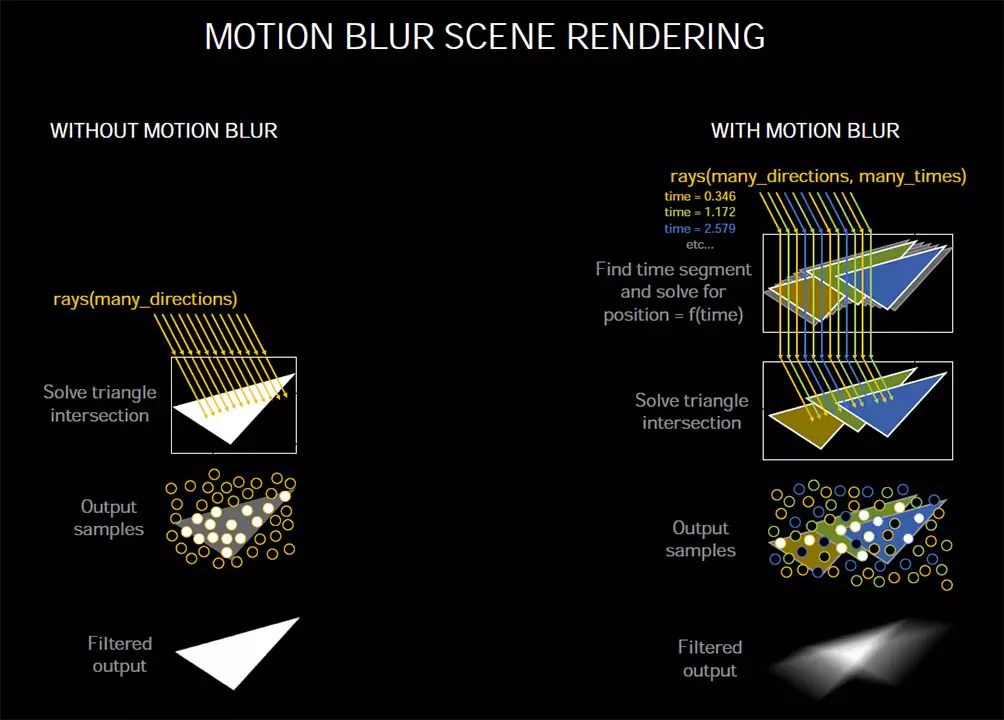
Az Ampere esetében az RT magok kibővültek egy új logikai blokkal is, ami képes interpolálni a háromszögek pozícióit egy idővonal mentén, a háromszög-metszést vizsgáló egységgel összehangolva. Ez az Nvidia szerint kifejezetten jól jön a Motion Blur, vagyis elmosódottságot generáló effekteknél a valós idejű sugárkövetés alkalmával, ám nem csak ez az előnye van a technológiának. Jó eséllyel teljesítmény-optimalizációként is funkciónál, ugyanis két képkocka között általában kevés változás tapasztalható, így nincs szükség mindig minden eredmény újraszámolására a következő képkocka elkészítéséhez, ha az aktuálisban már szinte minden számítás adott.
A feltételezések szerint éppen ezért mozgás-becslő algoritmus is került a fedélzetre, amelynek köszönhetően elég csak a ténylegesen megváltozó objektum-pozíciókat újraszámolni a képkockák között, ugyanis a rendszer „emlékszik” az előző kereszteződésekre, amelyeket, illetve közvetlen környezetüket újra ellenőrizve hamarabb eredményre juthat a tesztelés, ha a játékos mozog vagy nézetet vált, így végső erőforrás takarítható meg. Hogy ez a gyakorlatban pontosan mit jelent majd, szintén a tesztek fogják megmutatni.

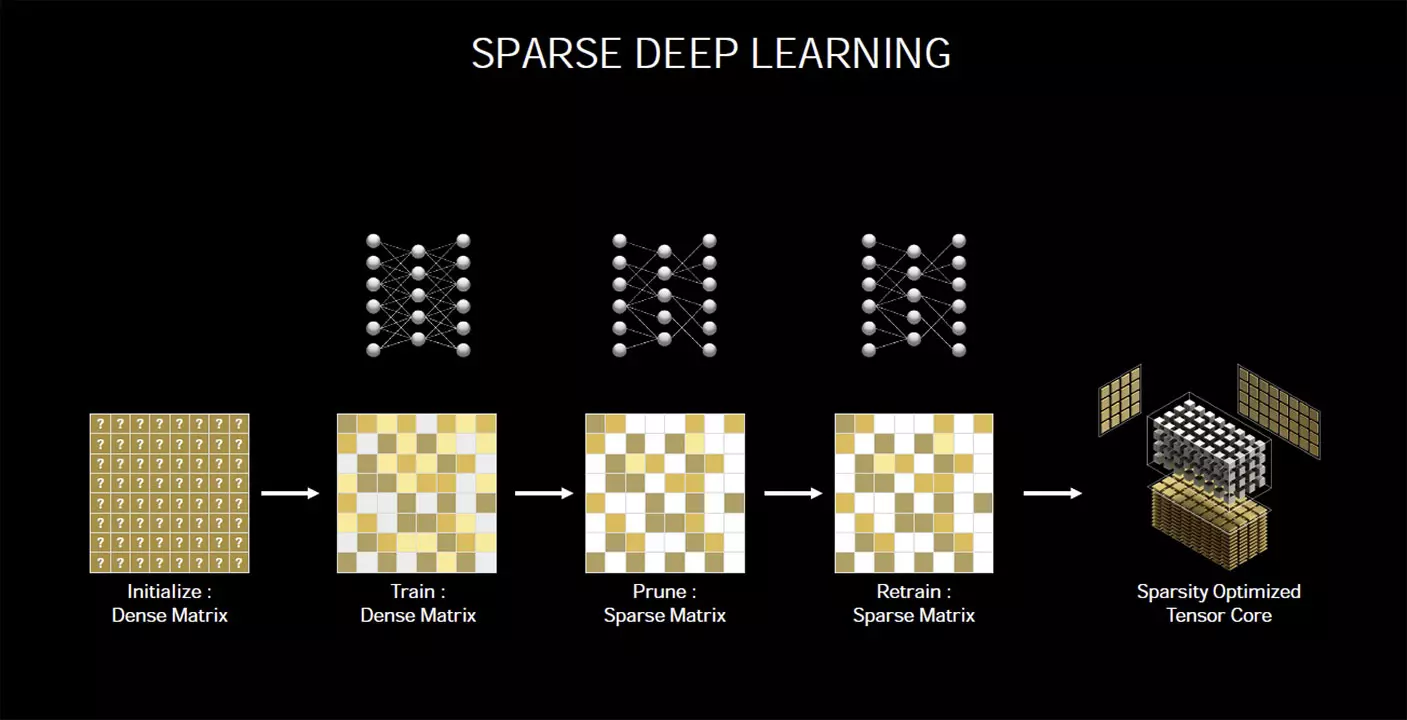
Az RT magok mellett egyébként a Tensor magok is fejlődtek, így azok most már a harmadik generációnál tartanak. Ugyanezek a magok dolgoznak a tavasszal bemutatott GA100-as GPU fedélzetén is, amelyek kifejezetten mesterséges intelligenciával kapcsolatos feladatok gyorsítására születtek. Az új magok most már Sparsity funkciót is kaptak, ami nagy vonalakban annyit jelent, hogy egy sűrű mátrixot lényegében úgy lehet megvágni, hogy a pontosság nem szenved csorbát, így az AI dedukció teljesítménye egy nagyságrenddel nagyobb lehet, mint normál esetben, ez pedig abszolút nem nevezhető elhanyagolható előnynek.
RTX IO – Jelentősen felgyorsul a tömörített eszközökkel való munka
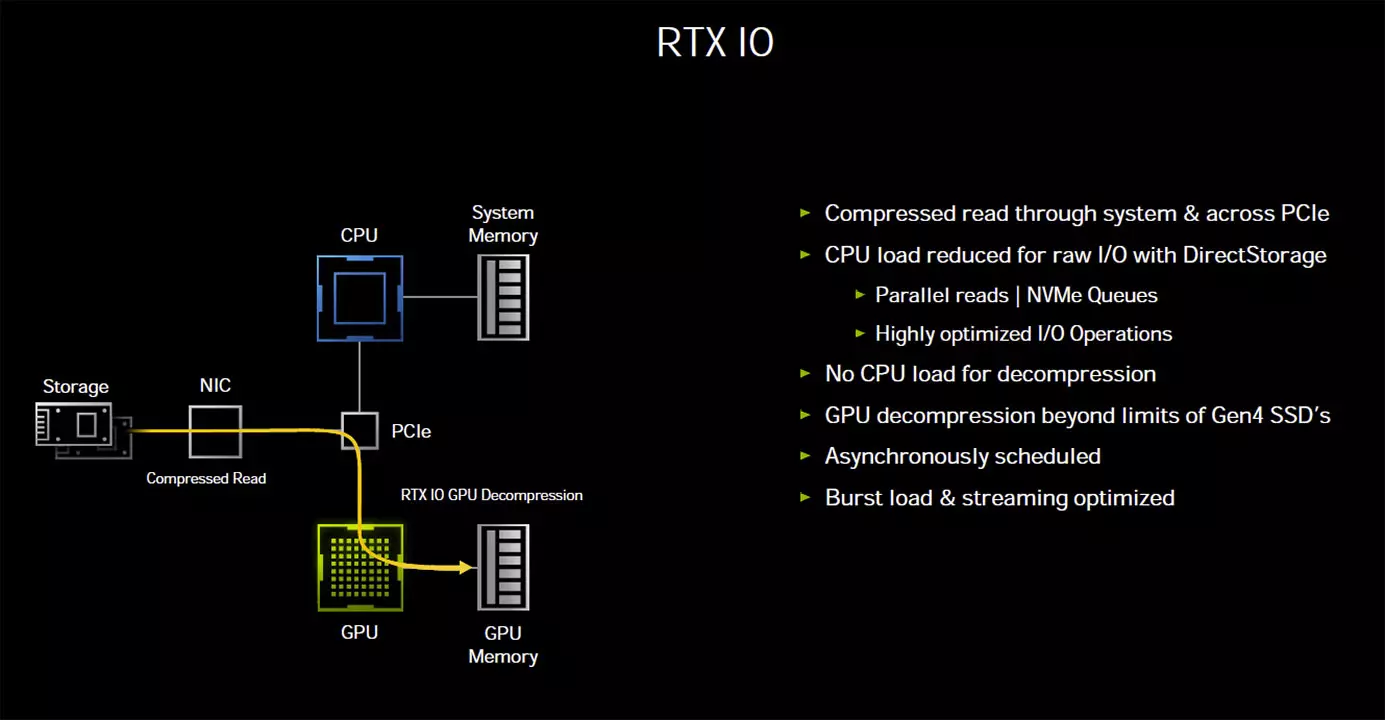
A modern játékok esetében óriási méretű tömörített eszközállományt kell kezelnie a rendszernek, ami elég nagy plusz terhet jelent a processzor számára. A tömörítetlen állományokkal való munka az Nvidia tesztjei szerint 7 GB/s-os adatátviteli tempót feltételezve egy PCI Express 4.0 x4-es SSD-vel karöltve nagyjából annyi I/O feladatot ad a rendszer számára, ami két processzormagot teljesen lefoglalna, ám az operációs rendszer jellemzően felosztja ezt a feladatot a rendelkezésre álló magok és szállak, vagy ha úgy tetszik, logikai processzorok között.
Amennyiben tömörített állományokkal kell dolgozni, a helyzet sokkal tovább romolhat, ugyanis a 7 GB/s-os adatfolyam a kitömörítés során – legjobb tömörítési hatásfok esetén – akár 14 GB/s-os terhelést is jelenthet a processzor számára, és ehhez még hozzájönnek az I/O kérések saját extra terhelései is (overhead). Ha a processzorra bízzuk az adatmozgatás és a kitömörítés minden járulékos terhét, akkor az Nvidia szerint akár 24 mag teljes terhelésére is szükség lehet a munkafolyamat elvégzéséhez, ami rengeteg.
Éppen ezért lépett be a képbe az RTX IO, ami a gyakorlatban annyit tesz, hogy a tömörített adatokat egyenesen a GPU-nak továbbítja, ami közvetlen módon végzi el a kitömörítést, így lényegében minimálisra csökken a processzor ezzel kapcsolatos terhelése – nagyjából fél magnyira, ugyanis csak a streamet kell elindítani a GPU felé, a többit már a GPU megoldja. Az RTX IO tulajdonképpen a Microsoft DirectStorage API-ját használja, ami pont azért készült, hogy az említett tömörítési feladatokat a GPU-ra lehessen bízni.
Az RTX IO ennek az API-nak a koncentrikus külső rétegének tekinthető, amit a játékokhoz és az Nvidia GPU architektúrájához optimalizáltak. Az Nvidia szerint ez az újítás kétszeresére növeli az IO teljesítményt, valamint akkora kitömörítési teljesítményt kínál, amivel az aktuális PCI Express 4.0-s SSD-k sem tudnak lépést tartani, pontosabban nem tudják csúcsra járatni.
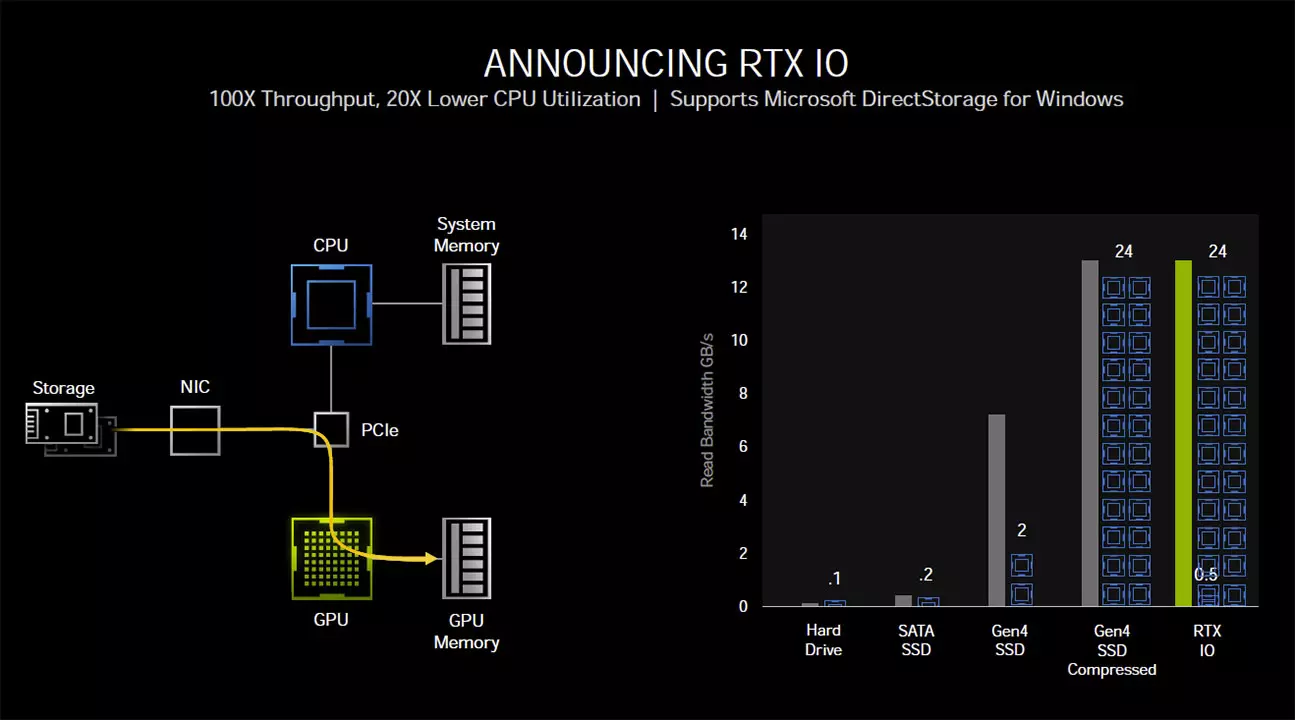
Azt viszont még érdemes megemlíteni, hogy a hivatalos tájékoztatás szerint az RTX IO implementálására játékok szintjén is külön-külön szükség van, így ha az adott játék fejlesztője ezt nem a funkciót tartja fontosnak, bizony nem lehet kiaknázni a technológiában rejlő lehetőségeket. És az RTX IO minden bizonnyal csak az Nvidia grafikus processzoraival működik, így az AMD megoldásainál más implementációra lehet szükség – természetesen továbbra is a Direct Storage API használatával, de olyan módon, ami az AMD architektúráival optimálisan és hatékonyan működik.
Az persze egyelőre nem világos, hogy SATA 6 Gbps-os és PCI Express 3.0-s SSD-kártyákkal, illetve SSD meghajtókkal mekkora előnyre tehet szert a rendszer, ugyanis a gyártói példák kifejezetten a leggyorsabb, PCI Express 4.0 x4-es csatolófelületet alkalmazó SSD kártyákkal elérhető adatátviteli sávszélességre hivatkoztak.
Nvidia Reflex és Reflex Latency Analyzer
Igazi újítás lesz a Reflex funkció, ami segít abban, hogy a bemeneti késleltetés csökkenjen a versenysportban használatos e-sport címeknél, vagyis egy egérkattintást követően gyorsabban hajtsa végre a rendszer a játékos által kívánt feladatot. A funkciót a népszerű e-sport címek egy-egy frissítés keretén belül kapják meg, az Nvidia ígérete szerint még ebben a hónapban, ezek között pedig jelen lesz a Valorant, az Apex Legends és a Fortnite is. Ezzel együtt persze a legfrissebb GeForce driverre, valamint egy GeForce 900-as sorozatú, vagy ennél újabb videokártyára is szükség lesz ahhoz, hogy a Reflexben rejlő lehetőségeket maradéktalanul kamatoztatni lehessen.
Az aktuális információk alapján az újítás lényegében a GeForce driveren keresztül működik, amely a kompatibilis játékmotorral együttműködve optimalizálja a 3D-s renderelő futószalagot annak érdekében, hogy a renderelési sort dinamikusan csökkentse, így kevesebb képkocka torlódik fel a GPU számára.

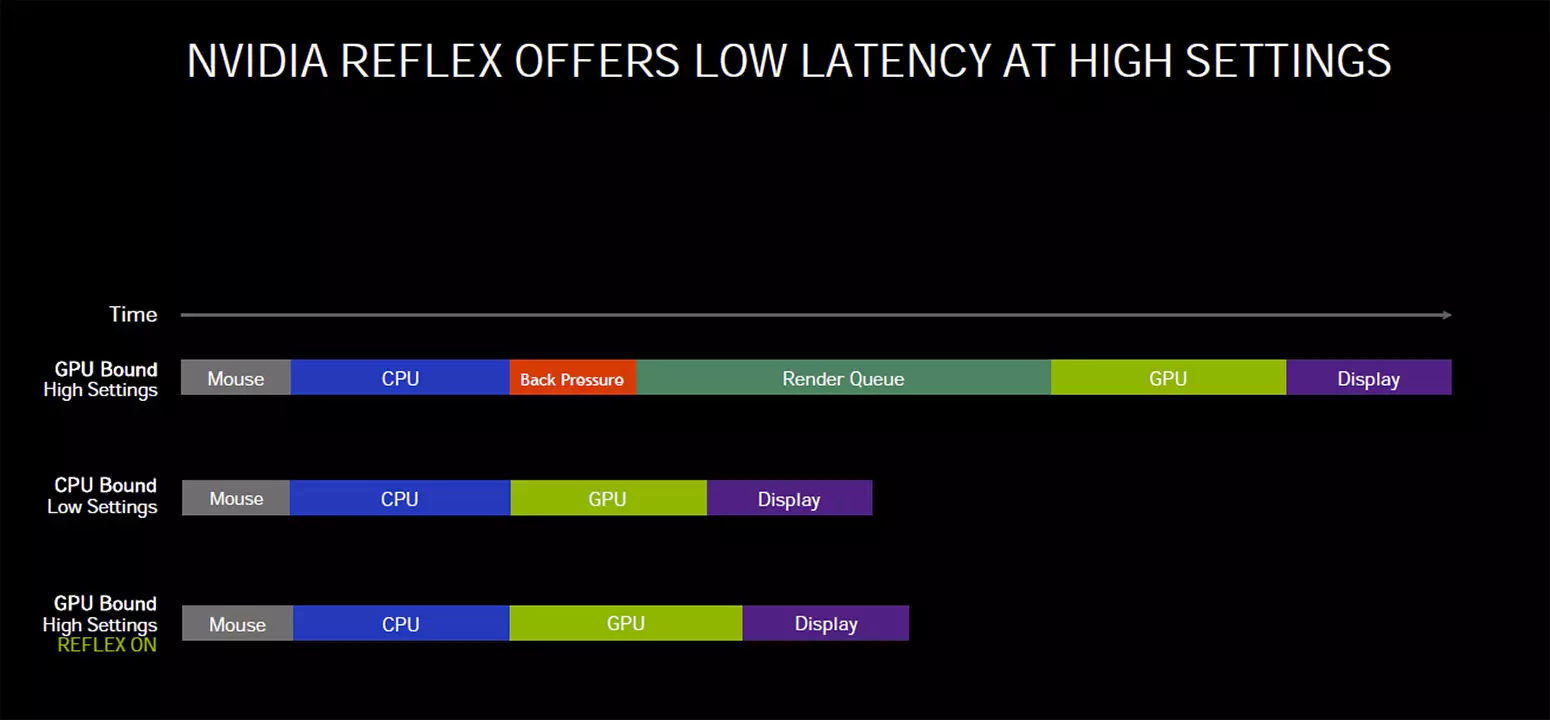
Ennek lényege, hogy a beavatkozás hatására szinkronba kerülhet a CPU és a GPU, így a GPU-n lévő teher csökkenhet, vagyis az egérbevitelt a lehető legkésőbbi időpontban ellenőrizheti a játék, ami végső soron a bemeneti késleltetés csökkenését eredményezi, hiszen hamarabb végre tudja hajtani a rendszer a játékos utasítását, ahogy az a lenti folyamatábrán is látszik.
A Reflex alkalmazását a Reflex SDK segíti, amely lehetőséget ad a technológia ki- és bekapcsolására, valamint különböző mérések eredményeinek megjelenítésére is – erre van szükség az adott játékon belüli implementációra is.

És itt jut szerephez a Reflex Latency Analyzer funkció, ami a G-Sync támogatással ellátott e-Sport 360 gamer monitorok saját szolgáltatása lesz. Ezek a monitorok mindannyian 360 Hz-es képfrissítési rátával dolgoznak, ám nem TN+Film, hanem IPS panelt használnak, méghozzá két meghajtó áramkörrel. Az új monitorok fedélzetén helyet kap egy kétportos USB 3.0-s hub, amelyet a kompatibilis rendszerhez kell csatlakoztatni – fentebb részleteztük a Reflex követelményeit –, a monitorhoz pedig egy Nvidia tanúsítvánnyal rendelkező ASUS, Logitech, vagy éppen Razer egérnek kell csatlakoznia.
A rendszer minden egyes egérkattintás alkalmával képes megmérni, mennyi idő telt el a kattintás és a fegyver elsütéséről árulkodó pixelek megjelenése között, magát a szolgáltatást pedig az adott monitor OSD menüjében lehet aktiválni. Ezzel a módszerrel a bemeneti késleltetés precízen és pontosan lemérhető, valamint a mérés optimalizálására is van mód, hiszen megadható, mely képterületet figyelje a rendszer, hol kell megjelennie a lövés effektjeinek.
DLSS 2.1

Az Nvidia a Turing architektúra debütálása óta folyamatosan fejleszti a Deep Learning Supe-Sampling technológiát, ami egy igen speciális megoldás: lényegében annyit csinál, hogy a GPU által alacsonyabb felbontásban lerenderelt tartalmakat az előre tréningezett neurális hálózat segítségével képes felskálázni a kijelző natív felbontására, így összességében kisebb erőforrás-igénnyel lehet tartalommal megtölteni a monitort, mint ha eleve natív felbontásban rendereltük volna a képkockákat.
A DLSS nagy általánosságban jó képminőséget kínál, de azért a képhibáktól nem mentes, ám ezek nagy részét a pörgősebb játékmenetek alkalmával nem igazán lehet kiszúrni, azaz nem feltétlenül zavaróak. Azaz a technológia nem tökéletes, de így is nagy segítség, ugyanis sok esetben játszhatóvá tud tenni egy olyan játékot a monitor natív felbontását használva, amihez a natív felbontáson történő renderelés mellett már nem lenne elég szufla a videokártyában.

Most, hogy az Ampere sorozatú GeForce-ok HDMI 2.1-es támogatást kapnak, vagyis képesek lesznek egyetlen HDMI kábelen keresztül akár 8K-s felbontás és 60 Hz-es képfrissítési ráta egyidejű kiszolgálására, nagyobb és fontosabb szerephez juthat a DLSS. Az Nvidia újításként elérhetővé tette a 9x-es skálázást, vagyis a GPU ekkor 1440p-s tartalmat renderel natívan, amit a DLSS 2.1 keretén belül képes akár 8K-ra is felskálázni a rendszer.
Ez nagy előrelépés, mert eddig a 4x-es skálázás jelentette a maximumot, vagyis Full HD-ről 4K-ra, valamint 4K-ról 8K-ra lehetett lépegetni. Hogy az új videokártyák milyen teljesítmény-előnyökhöz jutnak az új DLSS segítségével, illetve mekkora mértékben javul a képminőség az előző generációs DLSS-hez képest? A tesztek erre is rámutatnak majd, de már az Nvidia belsős mérései alapján is ígéretesnek tűnik az újítás.
Nagyon fontos és kifejezetten hasznos újítás még az is, hogy a DLSS immár a VR tartalmakat is támogatni fogja, ami óriási segítség lehet, hiszen azon a területen különösen fontos a folyékony, akadásmentes képi megjelenítés, ami az erőforrás-takarékosabb DLSS segítségével könnyebb lesz. Ráadásul a DLSS immár dinamikus skálázásra is képes lesz, vagyis nem lesz feltétlenül muszáj egy fix, rögzített felbontásról végeznie a felskálázást, időközben változtathat az alapfelbontáson, amivel a képkockák készülnek, amennyiben erre bármi miatt szükség van.
Végszó
Dióhéjban ennyi újítással érkeznek a GeForce RTX 3000-es sorozatú videokártyák, ám a lényeg talán nem is igazán ez, hanem az, hogy milyen teljesítményt nyújtanak játék alatt egymáshoz, illetve előző generációs társaikhoz képest. A nagy kérdés persze az lesz, hogy az Ampere alapú felhozatal teljesítménye mire lesz elég az AMD rövidesen megjelenő Big Navi videokártyáival szemben, amelyek RDNA 2 architektúra köré épülnek. Utóbbi területet majd csak később, október végén vagy november elején tudjuk megvizsgálni, ám a GeForce RTX 3080 teljesítményéről néhány óra múlva lerántjuk a leplet. Hogy mi minden lesz a tesztben? Ez legyen meglepetés.
