
Az MI verseny élmenői mellett sokan fejlesztenek már saját modelleket, és a Xiaomi egyre jobb pozícióba kerül ezen a területen (is). A cég legújabb nyílt MiMo-V2.5 modellje már nagyon hasonló szinten mozog, mint az ugyancsak néhány napja bejelentett DeepSeek-V4. Ráadásul a Xiaomi megoldása még a kínai vetélytársánál is olcsóbb.
A MiMo-V2.5 egy Sparse Mixture-of-Experts (MoE) architektúrájú modell, elsősorban ennek köszönhetően lesz rendkívül hatékony. Összesen 310 milliárd paraméterrel rendelkezik, ám ezekből legfeljebb 15 milliárd lehet aktív. Elérhető ennek a Pro variánsa is, ahol már azért a jobb teljesítményre nagyobb hangsúly kerül, az a modell 1,02 billió paraméterrel rendelkezik MoE felépítés mellett, és 42 milliárd aktív paraméterrel dolgozhat.

A Xiaomi lehetőséget nyújt a partnereknek a modellek finomhangolására, utólagos tréningezésére egyedi adatok alapján, hogy a különböző területeken jobban teljesíthessenek. A MiMo-V2.5-Pro már a kifejezetten komplex ágens feladatok megoldására lett kihegyezve, jó lesz érvelésben nagy mennyiségű adat feldolgozása mellett, és a programozási feladatokat is hatékonyan láthatja el. Az újdonságok egyaránt 1 millió tokenes kontextusablakkal üzemelnek.
A fejlesztők natív multimodális működésre összpontosítva alkották meg a MiMo-V2.5-öt. Ez azt jelenti, hogy zökkenőmentesen fogja feldolgozni a szöveges utasításokkal párhuzamosan a képeket, videókat és hanganyagokat egyaránt. Ennek köszönhetően is hatékonyabban érvelhet, pontosabban válaszolhat és az ágens feladatok végrehajtásában is rugalmasnak bizonyulhat. Hangsúlyozta a cég, hogy hatalmas adatmennyiséggel, 48 billió tokennel történt az alapmodell tréningezése.
A MiMo-V2.5 a leghatékonyabb “claw” ágens feladatok megoldására alkalmas modell jelenleg a piacon – emelte ki a Xiaomi.
Az OpenClaw, NanoClaw és hasonló szolgáltatások meghajtására kiváló megoldást jelent az új eszköz, ami mindenképpen jól hangzik annak tükrében, hogy ezek elképesztő népszerűségnek örvendnek napjainkban. A ClawEval tesztben csak a Claude modellek előzik meg a MiMo-V2.5-öt, de a hatékonyságban nem versenyképesek.
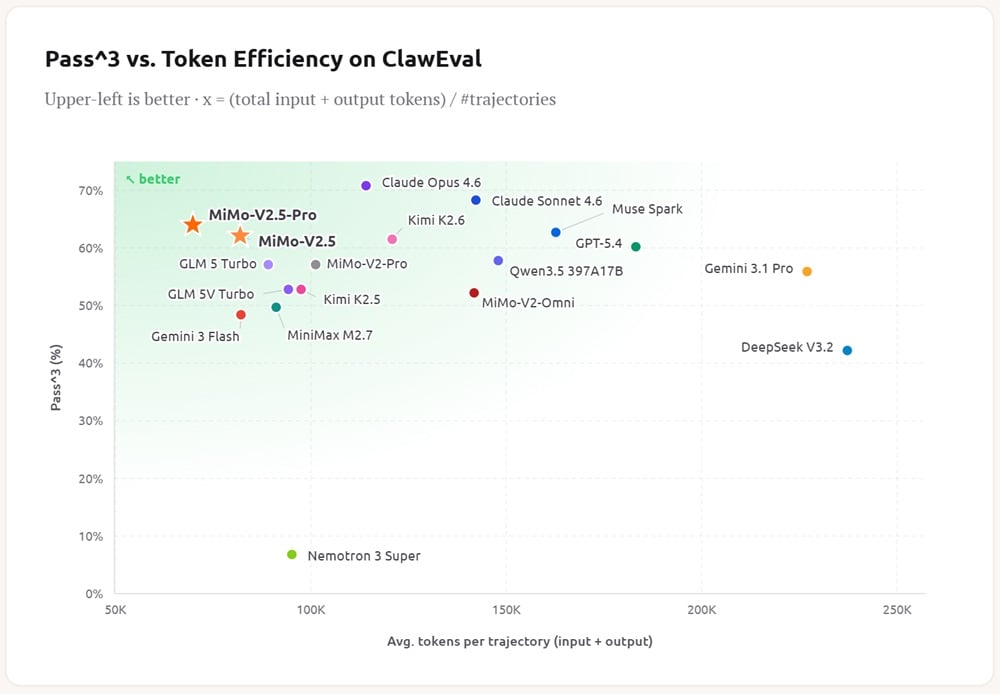
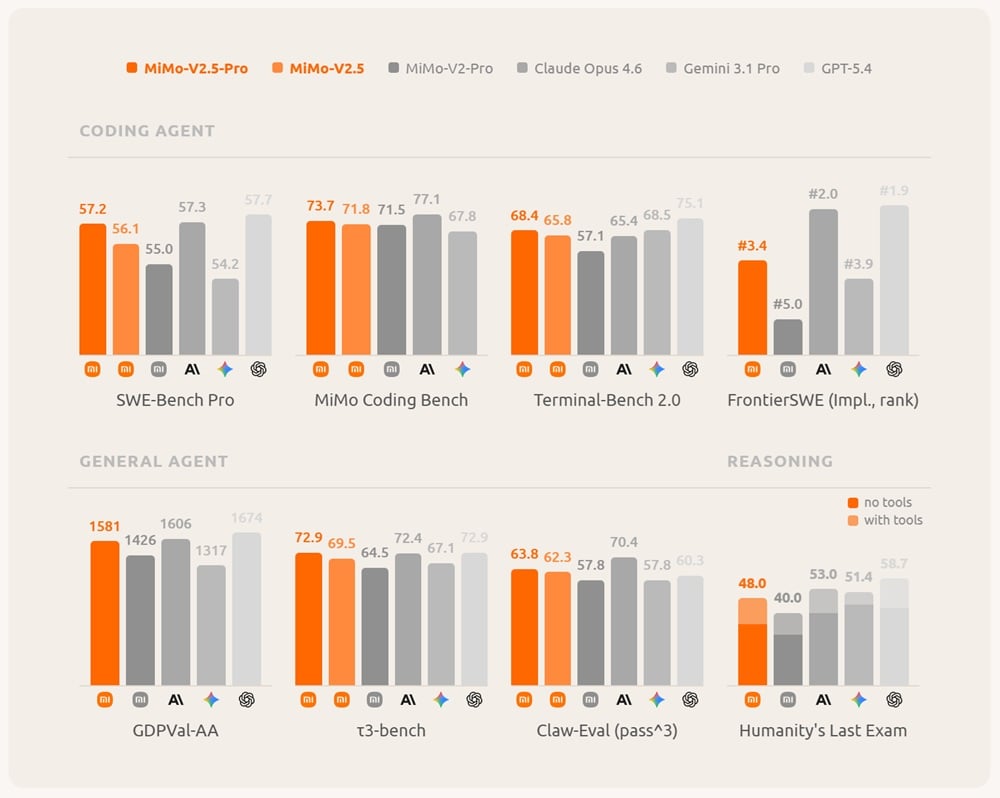
Saját méréseiben a Xiaomi trükkösen a korábbi Opus és GPT modellekhez mérte még a MiMo-V2.5-öt, de a legújabb eszközökhöz képest sem teljesít nagyon rosszul az újdonsága. A MiMo-V2.5-Pro az SWE-Bench Pro alatt 57,2%-ot ért el, miközben a GPT-5.5 ebben 58,6%-ot tud felmutatni a Claude Opus 4.7 pedig 64,3%-ra képes. A Humanity's Last Exam keretében pedig “segítség” nélkül 34%-ot tud felmutatni a GPT-5.5 Pro 43,1%-os eredményével szemben. Nagyjából 1,5 generációs lemaradása van a Xiaominak, de azt észben kell tartani, hogy sokkal kevesebb erőforrásból üzemel, mint az említett ellenfelei.
A DeepSeek azzal robbant be a köztudatba korábban, hogy mennyire költséghatékonyan üzemel, töredéke áron képes nagyon hasonló teljesítményre, mint a nyugati riválisai. Nos, a Xiaomi is hasonló irányból közelíti meg a nyelvi modelleket, és ennek eredményeként a MiMo-V2.5 még költséghatékonyabb, mint a DeepSeek-V4. A MiMo-V2.5-Pro mindössze egy dollárból oldja meg 1 millió token feldolgozását, és 3 dollárba kerül ugyanennyi tartalom generálása. A MiMo-V2.5 esetén pedig már csak 0,4 és 2 dolláros költségekről beszélhetünk 1 millió token feldolgozása és előállítása esetén.
A Xiaomi dolgozik a MiMo-V2.5-Flash modellen is, ami a tervek szerint az ismertebb nyelvi modellek körében a legolcsóbban üzemelő megoldás lesz, még a jelenlegi legolcsóbb Grok 4.1 Flashhez képest is nagyjából féláron lesz alkalmazható. 0,1 dollárba fog kerülni 1 millió token a bemeneti oldalon, a kimeneti oldalon pedig 0,3 dolláros költségvonzata lesz ennek.
A MiMo-V2.5 modellek “teljesen” open-source megoldások, és elérhetők a nagyközönség számára akár még kereskedelmi felhasználási lehetőségre is. A Xiaomi olyan szabadságot ad, amit nem sokan nyújtanak ezen a téren, az egyedi adatokkal finomhangolt modellek utólagos hitelesítését sem írja elő a partnerek számára.
