
A kínai nagy reménységnek tartott DeepSeek több csúszást követően tudta elindítani a legújabb modellcsaládját, a DeepSeek-V4-et, ami több különböző méretben lesz elérhető. Egy átfogó frissítésről beszélhetünk, ami szinte mindenre kiterjed, de a mostani generációváltás nem fogja megrengetni a világot.
A DeepSeek-V4 széria a továbbfejlesztett Mixture-of-Experts (MoE) technikát használja, és már kifejezetten jól fog teljesíteni hosszú kontextusok esetén, jelentős javulást mutat majd az érvelési képessége, és az ágens alapú feladatmegoldásban is jónak fog bizonyulni.
A vállalat két változatról beszél első körben, a DeepSeek-V4-Pro és a DeepSeek-V4-Flash modellek álltak a rajtvonalhoz. Kiemelte a cég, hogy itt már “úttörő 1 billió paraméteres MI modellről” beszélhetünk. Az új generációs MoE eljárás révén kiváló hatékonysággal fog üzemelni a rendszer, a közlemény szerint átlagosan csak 32-37 millió aktív paraméterre lesz szükség a kiemelkedő teljesítmény biztosításához ( maximum 49 millió paraméter lehet aktív).
A hivatalos adatok szerint a DeepSeek-V4-Pro 1,6 billió paraméterrel rendelkezhet, a DeepSeek-V4-Flash-nél pedig 284 milliárd paraméterről beszélhetünk. A szakértői feladatokban, kutatásokban a V4-Pro kerül bevetésre, az általános kérdéseket pedig a V4-Flash lesz hivatott gyorsan és hatékonyan megválaszolni. A vállalat az új generációt az eddigitől eltérő módszerekkel tréningezte (33 billió tokenen), új architektúrát használ, és rendszerszintű optimalizálások tömkelegét vetették be, hogy lefaragják a számítási kapacitás- és memóriahasználatot.

Natívan multimodális működésre tervezett modellel van dolgunk, amit az alapoktól kezdve arra készítettek fel a fejlesztői, hogy a szövegeket, képeket, videókat és hanganyagokat szimultán képes legyen kezelni a feladatok során. A DeepSeek-V4 önállóan tud “ügynökként” üzemelni, és kifejezetten erősnek ígérkezik programozási feladatokban. A kódolást minden techcég igyekszik nagy erővel fejleszteni, mert jelenleg ez a felhasználási terület termeli a legtöbb bevételt.
Nagy hangsúlyt helyezett a DeepSeek a bejelentésében arra, hogy a versenytársaihoz hasonlóan 1 millió tokenes kontextusablakot fog biztosítani a továbbiakban a nyílt modell. A Google Gemini volt az első nagyobb modell, ahol az 1 millió tokent elérték a fejlesztők, és ez szép lassan már iparági sztenderdnek tekinthető, amit innentől a DeepSeek minden újabb modellje tartani fog. Ennek köszönhetően a cég elmondása alapján kiváló pontossággal fog dolgozni a modell nagyobb mennyiségű ismeret, hosszú kódok esetén is.
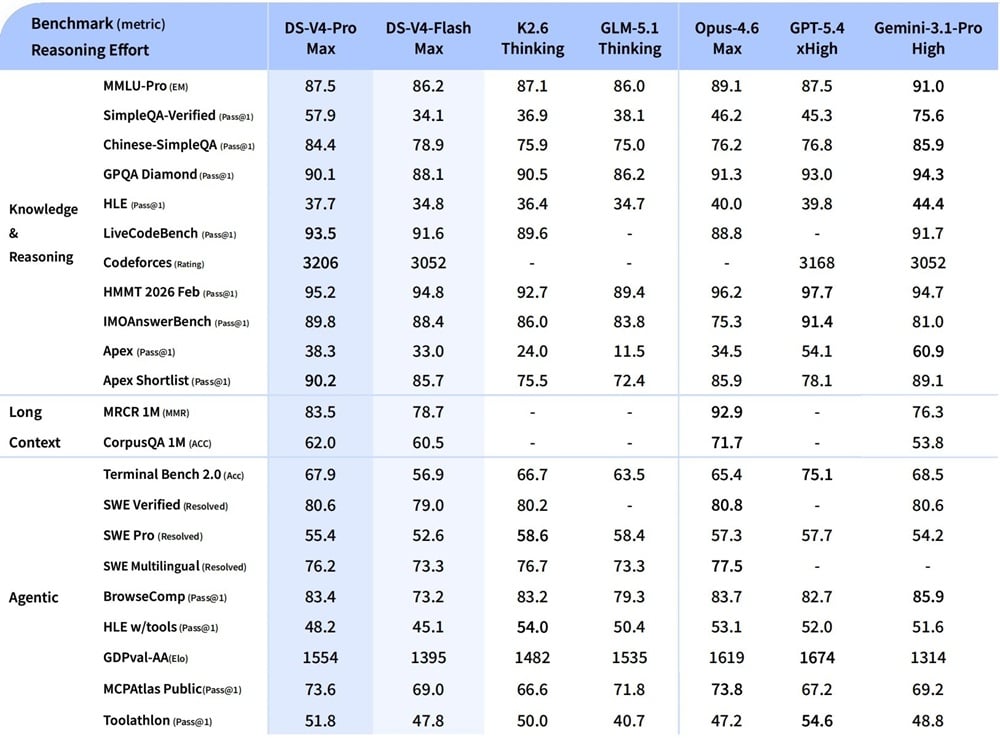
A felkapott Humanity's Last Exam tesztben a DeepSeek újdonsága nem szerepel túl jól, a Gemini 3.1, a GPT-5.5 és a Claude Opus 4.7 mögött bőven lemaradva, mindössze 35,9%-os eredményt tud felmutatni. Az élmenők már mind 40% körül, de inkább felette vannak kiegészítők nélkül is. Az ágensi működést felmérő SWE-Bench Pro tesztben GPT-5.5 már 58,6%-os performanszra képes, míg a Claude Opus 4.7 64,3%-ot tud villantani, az új DeepSeek-V4-Pro viszont csak 55,4%-ra képes. A vállalat a saját tesztjeiben előszeretettel mérte az újdonságot a korábbi riválisokhoz, hogy szebb legyen az új modellről alkotott kép.
Azt is megjegyezte a beszámolójában a DeepSeek, hogy az új V4 modellcsalád már nem az Nvidia GPU-kra lett optimalizálva, miközben persze azért a zöldek hardverein is el fog futni. A kínaiaknak az amerikai szankciók miatt már muszáj volt kínai hardveres megoldások felé fordulni, ezért az új mesterséges intelligencia eszköz esetén a Huawei lett az elsődleges partner. “Kifejezetten a Huawei Ascend 950PR és a Cambricon MLU chipekhez optimalizálva” a DeepSeek-V4.
A költségekben az új széria a felmenőihez hasonlóan nagyon jól teljesít, így ha a tesztekben nem is mutat forradalmi teljesítményt, a költséghatékonysága vitathatatlan. A DeepSeek-V4-Pro esetén 1 millió token bevitele legrosszabb esetben 1,74 dollár, de van input cache, amivel még ezt képes lejjebb faragni, a kimeneti oldalon pedig 3,48 dollárt kóstál ilyen adatmennyiség. A DeepSeek-V4-Flash-nél pedig csak 0,14 dollárba kerül 1 millió token feldolgozása, és 0,28 dollárból megúszható 1 millió token létrehozása.
