Az Intel a Computex 2024-hez kapcsolódó előadásán legújabb nagy dobásáról, a Lunar Lake sorozatú mobil processzorokról rántotta le a leplet, amelyek a Meteor Lake sorozat alacsony fogyasztású példányait váltják a piacon, méghozzá a közeljövőben. Az új processzorok csak és kizárólag mobil kivitelben érkeznek majd, asztali formában maximum kompakt asztali számítógépek fedélzetén találkozhatunk velük, például akár NUC sorozatú termékeken, és egyéb hasonló méretű megoldásokon.

A gyártó illetékesei elárulták, mit érdemes tudni a Lunar Lake névre keresztelt lapkával kapcsolatban, már ami a felépítést illeti, illetve azt is elárulták, nagyjából mekkora gyorsulást hozhat az új lapka az egyes területeken a Meteor Lake-hez képest. Sajnos konkrét modellekről egyelőre még nem esett szó, valamint azt sem részletezték, a rivális mobil processzorokhoz képest hol helyezkedik el a Lunar Lake teljesítménye, de később erre is egészen biztosan kitérnek majd, ahogy közeledik a piacra dobás tervezett időpontja.
A Lunar Lake lapka felépítése nagy vonalakban

A Meteor Lake sorozathoz hasonlóan ezek a SoC egységek is csempékből állnak majd, viszont a felépítés változott, ugyanis a processzormagokat tartalmazó Compute Tile, az iGPU-t rejtő Graphics Tile, valamint a SoC Tile is egyetlen lapkára került, ami a Compute Tile nevet viseli, rajta kívül egy Platform Controller Tile is rendelkezésre áll, ami az I/O részleghez tartozó komponenseket fogja össze. Érdekesség, hogy az említett csempék közül egyetlen egyet sem gyárt az Intel, ezúttal mindegyiket kiszervezték a TSMC-hez: a Compute Tile a TSMC 3 nm-es osztályú N3B csíkszélességével készül, míg az Platform Controller Tile a TSMC 6 nm-es N6 gyártástechnológiájával jön létre.
Ezek a csempék a Base Tile névre keresztelt lapkán foglalnak helyet, ami biztosítja köztük a kommunikációt a Foveros segítségével, valamint a rendszerrel történő kommunikáció is ezen keresztül zajlik. A Base Tile már az Intel üzemében készül, méghozzá 22 nm-es csíkszélesség alkalmazása mellett. A Base Tile közvetlenül a tokozáson foglal helyet, és felette egy új komponens is megjelent, ami nem más, mint a rendszermemória.

Ezt a dizájnt Meteor Lake sorozat egyik tesztpéldányán, a Meteor Lake-MX lapkán már láthattuk, a koncepció azonban csak most ért meg arra, hogy kereskedelmi forgalomba szánt SoC fedélzetére is felkerülhessen. Mivel mobil megoldásról van szó, így LPDDR5X típusú fedélzeti memória kerül a tokozásra, ami LPDDR5X-8500 MHz-es effektív órajelen ketyeghet. A fedélzeti memória maximum 32 GB lehet és összesen két chipből tevődik össze, így kiaknázható a 2 x 64-bites memóriatámogatásban rejlő lehetőség, ami igazából 4 x 16-bitnyi memóriacsatornát takar.
Az új dizájnnal 40%-kal kompaktabb dizájn érhető el a memória-alrendszer esetében, mintha azt So-DIMM memóriamodulokkal vagy az új LPCAMM2 memóriamodullal oldanák meg. Hátrány viszont, hogy míg utóbbiak lehetővé teszik a fedélzeti memória bővítését, addig a tokozásra integrált fedélzeti memória esetében ilyesmire nincs lehetőség, és a memóriachipek utólagos cseréje is nehezebb lesz a hozzáértő szakemberek számára.
Változik a CPU részleg felépítése, elvész a Hyper-Threading támogatás

A Lunar Lake esetében a lapka maximum 8 darab processzormaggal és 8 szállal rendelkezhet, ugyanis ennél a fejlesztésnél már nem áll rendelkezésre Hyper-Threading támogatás a P-Core részleg esetében sem. A 8 processzormag egyébként négy darab Lion Cove és négy darab Skymont magból áll, amelyek közül előbbiek a P-Core, utóbbiak pedig az E-Core részleget erősítik. Nagyon fontos változás, hogy a 4-4 processzormag esetében a harmadszintű megosztott gyorsítótár már nem úgy fogható munkára mint eddig: nem kaptak egységes megosztott harmadszintű gyorsítótárat, helyette az E-Core részleg és a P-Core részleg is saját utolsó szintű gyorsítótár birtokában dolgozhat, ezek között a lapka belső, magas sávszélességű összekötőjén keresztül zajlik a kommunikáció, nincs klasszikus ringbus alapú összeköttetés köztük. A négy darab P-Core összesen maximum 12 MB-nyi L3 Cache-hez fér hozzá, az E-Core részleghez viszont nem tartozik L3 Cache, a processzormagok csak másodszintű gyorsítótárral gazdálkodhatnak, ami a négy Skymont processzormag között meg van osztva, ennek kapacitása összesen 4 MB.
A Lion Cove processzormagok, azaz a P-Core részleg
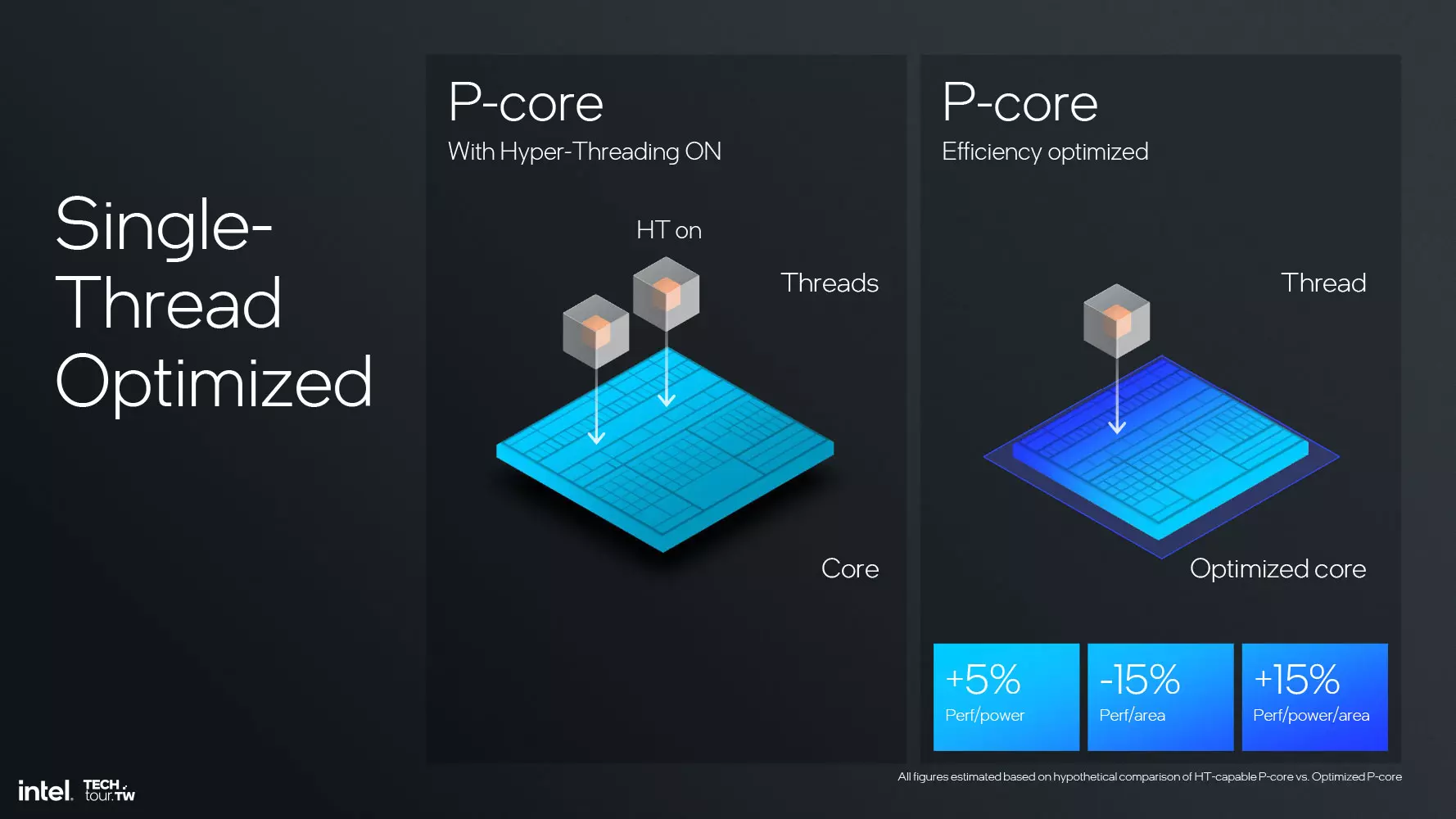
Az összesen maximum 4 processzormaggal rendelkező tömb esetében az Intel szakított a Hyper-Threading támogatással, ugyanis arra a hibrid felépítésű processzoroknál egyre kevésbé van szükség, és eddig amúgy sem volt túl hatékony a Hyper-Threading kihasználtsága, hiszen azt többnyire már csak akkor vette igénybe a rendszer, ha az E-Core és a P-Core részleg teljesen le volt terhelve, ez pedig nem jelent optimális működést, legalábbis a gyártó szerint – és ez így is lehet.
A Hyper-Threading támogatás eltávolításával a második szál működését irányító hardverkomponensek is eltávolíthatóvá váltak, az így felszabaduló helyet pedig a teljesítmény/watt hányados javítására használhatják, hiszen így növelhetik a többi komponens kapacitását, valamint az órajelet is emelni lehet a felszabaduló fogyasztáskeret jóvoltából. Az Intel csapatának számításai szerint a Hyper-Threading kigyomlálásával a Lion Cove processzormagok esetében 15%-kal javult az adott területen elérhető teljesítmény/watt arány, valamint 5%-kal jobb lett a teljesítmény/fogyasztás arány, illetve 15%-nyi lapkaterület megspórolására nyílt lehetőség.
A felszabaduló terület jóvoltából átalakították a magok felépítését, így például a Front-end 8x nagyobb elágazás-becslő blokkal rendelkezik, de ezzel együtt a Fetch egység is szélesebbé vált, nőtt a dekódoló sávszélesség, illetve a micro-op cache kapacitását is növelték. Nagyon érdekes változás, hogy ezzel együtt egy új kategóriát is bevezettek, ami a „Nano-Ops” nevet viseli, ez lényegében tovább bontott micro-op műveleteket jelent, amelyeket hasonlóságaik okán hatékonyan lehet egymással párhuzamosan elvégezni, ezáltal növekszik a teljesítmény.
Felbontották az Out Of Order Engine esetében az Int és a Vec doméneket, amelyeknél immár egymástól független átnevezők és ütemezők működhetnek, ezáltal a domén-specifikus munkafolyamatok alkalmával energiamegtakarításra nyílik mód. A két domén tagjai egymástól függetlenül is hozzáférnek a micro-op sorhoz, egymástól független ütemezőkkel, ami mindenképpen segít a teljesítmény növelésében. Az Out of Order Engine több területen is nőtt, a végrehajtó portok száma 12-ről 18-ra emelkedett a Deep Instruction Window kapacitása 512-ről 576-ra nőtt.
A Retirement Queue szélességét 50%-kal növelték, valamint az Alloc/Rename szélessége is nőtt 6-wide értékről 8-wide értékre. További fontos változás, hogy az Integer ALU egységek számát 5-ről 6-ra növelték, 2 helyett immár 3 Jump Unit és 2 helyett 3 Shift Unit dolgozik a fedélzeten, és Mul Unit-ból 1 helyett már 3-at rejt a dizájn. A változások közé tartozik még a vektor végrehajtó motor bővítése, ami már nem 3, hanem 4 SIMD ALU segítségével dolgozhat. FMA-ból kettőt kapunk, ezek 4 ciklusos késleltetéssel dolgoznak, az FP Divider részleg pedig 1-ről 2-re nőtt, közben pedig csökkent a késleltetés és nőtt a teljesítmény.
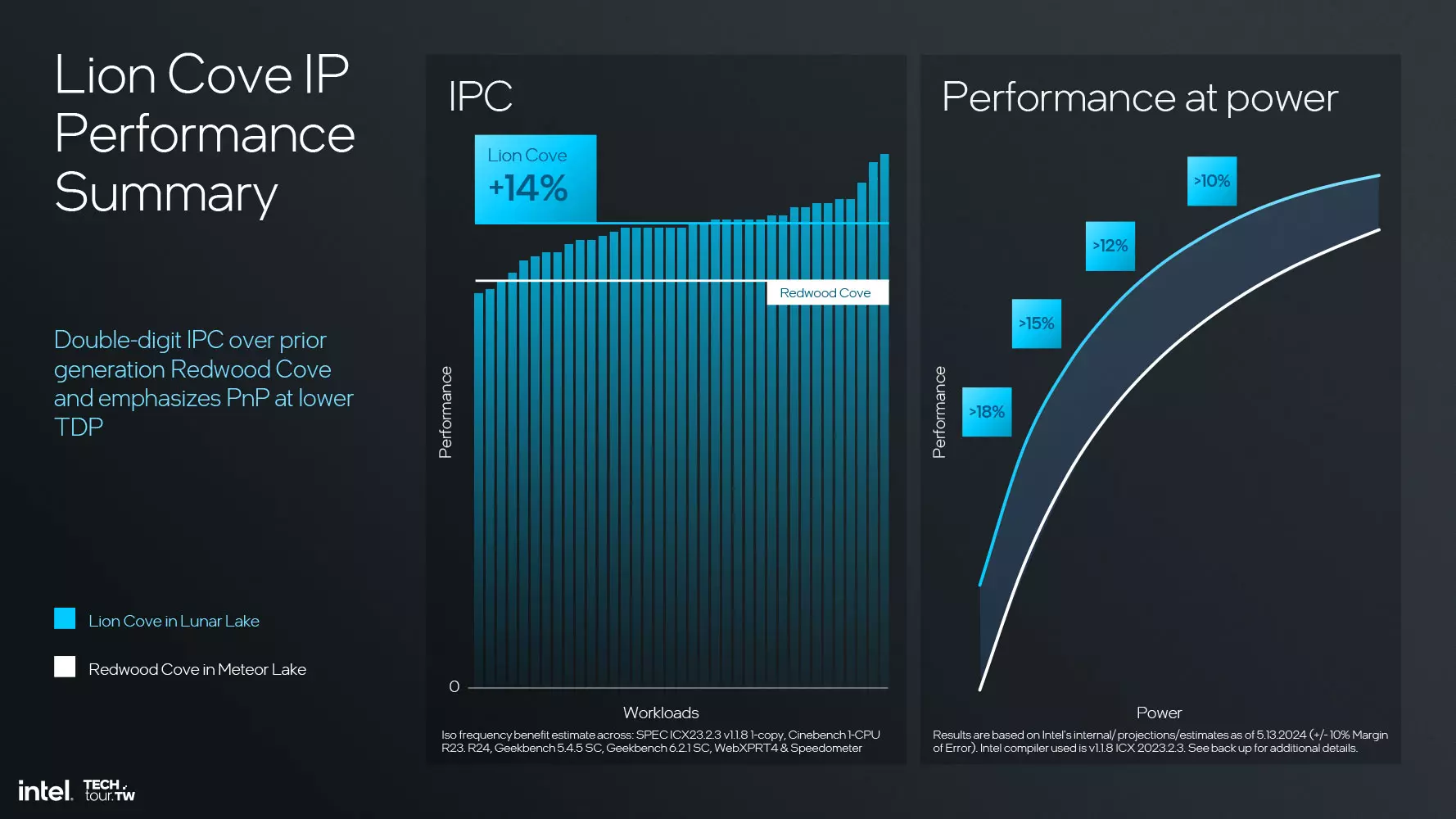
A Load-Store alrendszerben szintén történt némi változás, ugyanis a DTLB nem 96,hanem 128 lapos kapacitással dolgozhat az STA AGU esetében pedig a korábbi 2-ről 3-ra váltottak. Az Intel szerint a Lunar Lake fedélzetén dolgozó Lion Cove processzormagok 14%-kal több műveletet tudnak végrehajtani órajelenként, mit a Meteor Lake processzoroknál használt Redwood Cove processzormagok, de esetenként akár 18%-os növekmény is elérhető.

Változott a memória-alrendszer is, ugyanis a Lion Cove processzormagoknál a korábbi L1D Cache az L0D Cache szerepet kapta, ami immár 192 KB-nyi L1 C-Cache-hez kapcsolódhat. Az L2 Cache kapacitása a Lunar Lake modelleknél 2,5 MB lesz magonként, míg az Arrow Lake processzoroknál, amelyek ugyanúgy Lion Cove processzormagokat használnak, már 3 MB-nyi L2 Cache jut egy magra. Ahogy azt fentebb említettük, a négy P-Core ezúttal saját harmadszintű megosztott gyorsítótárat kap, ami nem osztozik az E-Core részleggel, kapacitása maximális kiépítés esetén 12 MB lesz.
Az E-Core részleg is combosodik

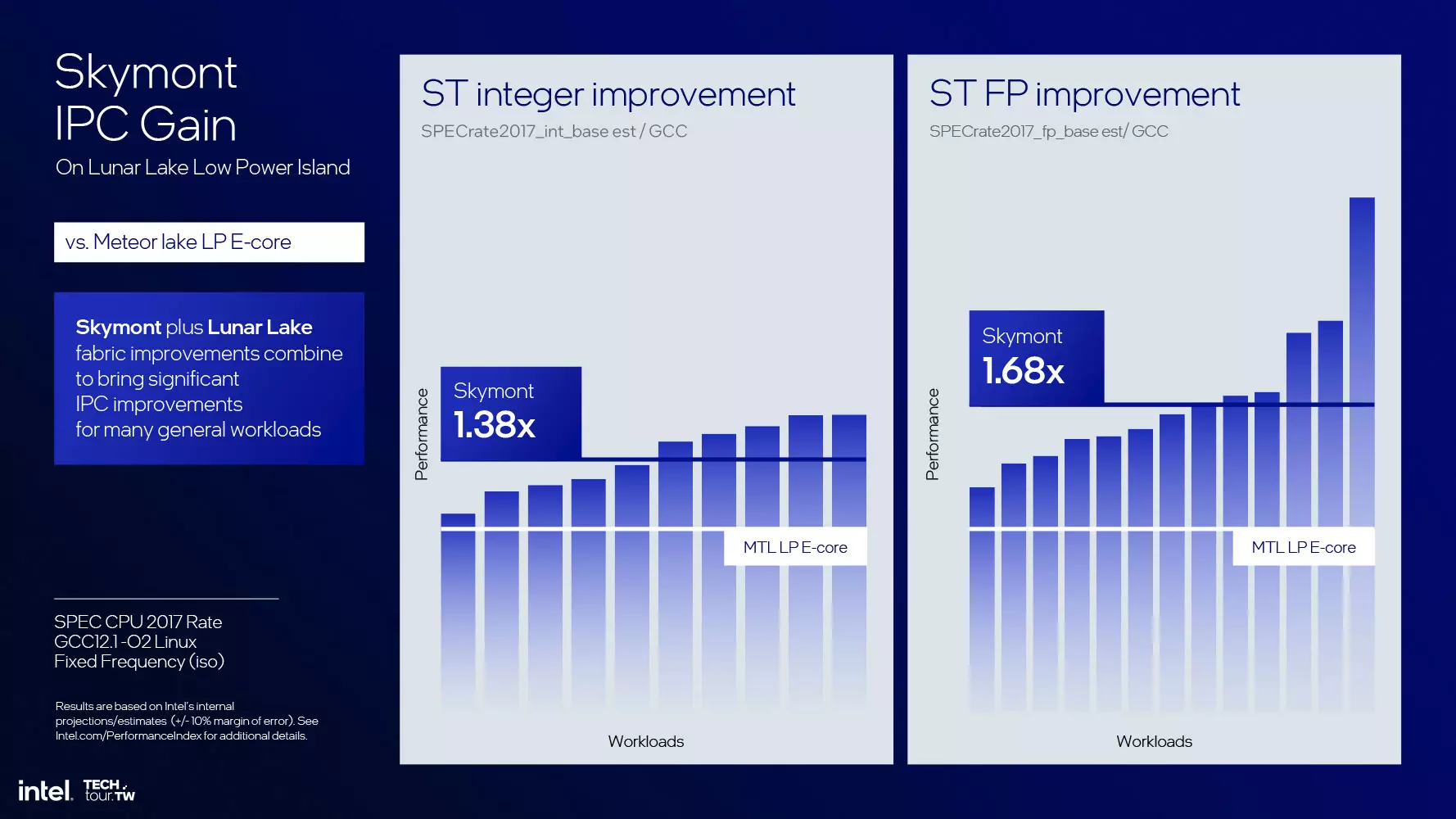
A Lunar Lake esetében a korábbi Crestmont processzormagok helyett immár Skymont processzormagok dolgoznak, amelyek az Intel szerint 68%-is IPC növekedést hoznak, ami igencsak komoly előrelépést jelent. Azt persze hozzá kell tenni, hogy ez az összehasonlítás a Meteor Lake SoC Tile-ján található E-Core részlegre vonatkozik, ami azért lehet korrekt, mert ott a két Crestmont LP Core nem kapcsolódik a P-Core és az E-Core részleg által használt ringbusra, mint ahogy itt sem a Skymont magok. Az energiahatékonyság terén elért előrelépés (teljesítmény/watt arány) 300%-kal javult, míg ha ugyanazt a fogyasztást vesszük alapul, akkor 2,9x jobb teljesítményt kapunk. Ha csúcsra járatják a Lunar Lake lapka Skymont magjait, akkor a Crestmont LP magokhoz képest akár négyszer jobb teljesítmény is elérhető, ami igencsak komoly eredmény.
Lényegében a fentieknek köszönhető, hogy az Intelnél úgy gondolták, átalakítják a processzormagok elrendezését, a P-Core részlegnél elhagyják a Hyper-Threading támogatást, a felszabaduló részt pedig az E-Core és a P-Core részleg kigyúrására használják fel. A jelentősen ütőképesebbé váló E-Core részleg és a megerősített P-Core részleg összességében helyettesíthetik a Hyper-Threading támogatást, sőt, nélküle is jelentős gyorsulást hozhatnak.
Változott a Fetch és a Branch Prediction Unit, ugyanis előbbinél egyszerre akár 96 utasítást lehet felhasználni párhuzamos módon, az elágazóbecslés pedig 128 bájttal előre tud nézni az esetleges elágazások keresésekor, ami szintén javítja a teljesítmény. A Front End részleg itt is változott, a 6-wide dekódoló egység immár 9-wide rendszerben működik, valamint itt is megjelent a Lion Cove processzormagoknál emlegetett Nano-Core támogatás, ami a hasonló mikroműveletek párosítását és párhuzamos elvégzésüket teszi lehetővé.
Jelentős változás az is, hogy a Micro-Op Cache kapacitása 96 bejegyzésre nőtt a korábbi 64 helyett. Változott az Out of Order Engine felépítése is, ami 6-wide helyett 8-wide felépítést használ, a Retire Queue pedig 8-wide helyett immár 16-wide felépítéssel rendelkezik, azaz dupla szélességgel dolgozhat. A késleltetés csökkentéséről a Depedency Breaking funkció gondoskodik. Az Out of Order ablakot jelentősen kiszélesítették, így az 256 helyett immár 416 bejegyzést kezelhet, nőttek a fizikai regiszterek, mélyebb lett az Int, Mem és Vector Reservation Station, valamint mélyebb lett a Load és a Store bufferelés is.
A végrehajtó motor immár 26 Dispatch porttal dolgozhat, így 8 Integer Alu és 3 Jump Port alkotja a dizájnt, órajelenként pedig 3 betöltést lehet végrehajtani, ami 50%-os előrelépést eredményez. A Vector Engine is változott, négy darab 128-bites FPU alkotja, így a GFLOp/s érték duplázódott. Csökkent az FMUL, az FMA és a FADD késleltetés, az lebegőpontos kerekítés pedig natív hardveres gyorsítás mellett futhat majd. Nőtt továbbá az AI teljesítmény is, hála az extra feldolgozó egységeknek.

Az E-Core részlegnél a maximum négy darab processzormag összesen 4 MB-nyi másodszintű gyorsítótárhoz fér hozzá, ám ebben az esetben nőtt az L2 Cache sávszélessége, egy órajelciklus alatt 64 B helyett 128 B fér át, valamint a magok közötti L1-L1 sávszélesség is nőtt, ami gyorsabb kommunikációt eredményez. A belsős tesztek alapján az IPC 38%-kal nőtt, a lebegőpontos teljesítmény pedig 68%-kal magasabb, mint a Crestmont LP magoknál, amelyek a Meteor Lake modelleknél a SoC Tile fedélzetén teljesítettek szolgálatot, a többi magtól elszigetelten.
Továbbfejlesztették a Thread Directort

Ez a speciális rendszerkomponens arról gondoskodik, hogy a különböző terhelésformákat a legmegfelelőbb processzormagra vagy processzormagokra irányítsa a rendszer, így optimális teljesítmény érhető el. Az új verzió intelligensebben osztja el a feladatokat, ezzel együtt javult az operációs rendszerrel és az OEM rendszerrel történő együttműködés, amelynek köszönhetően még pontosabban és hatékonyabban lehet irányítani az ütemezést.
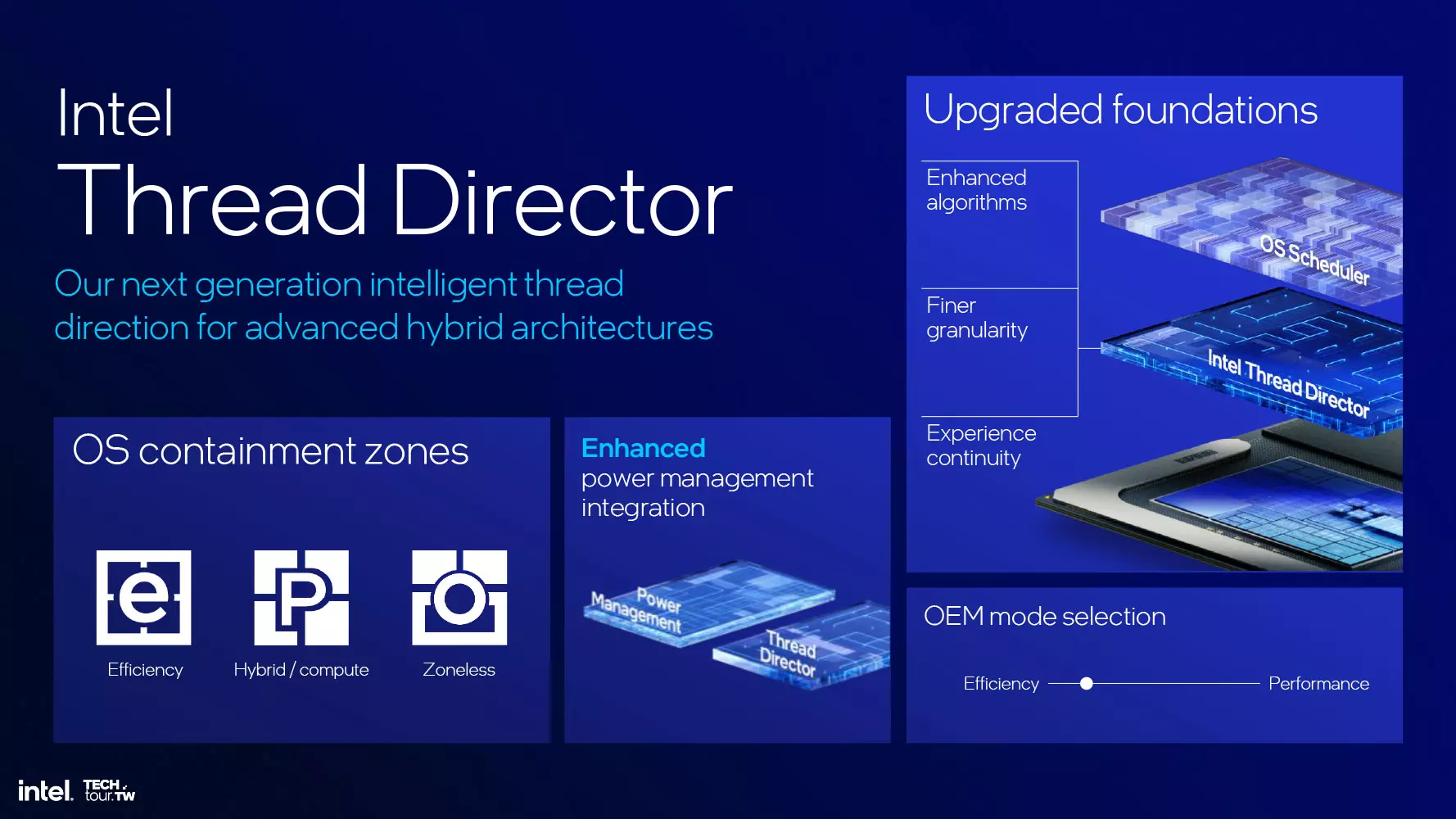
Bővítették az energiahatékonyságot célzó képességeket is, amelynek köszönhetően növekedhet az akkumulátoros üzemidő. A dinamikus ütemezés keretén belül elsőként egy E-Core kerül lefoglalásra, ha a terhelésforma jellege ehhez megfelelő, majd az E-Core részleg további magjait terheli a rendszer. Szükség esetén a P-Core részleg is munkát kap, ha ezt a terhelés jellege igényli. Ez az alapértelmezett működési forma.

Az új Thread Director esetében meg lehet majd mondani, mely szoftverek mely magtípusokon fussanak, ezeket korlátozhatjuk csak az E-Core, vagy csak a P-Core magokra, de arra is van lehetőség, hogy „zóna nélküli” módban fusson az alkalmazás, azaz ne legyen korlátozva egyik részlegre se.
Debütál az Xe2 architektúra, jelentősen gyorsul az iGPU is

A Lunar Lake SoC egységek nemcsak processzormagok terén hoznak előrelépést, hanem iGPU tekintetében is, méghozzá elég jelentőset, ugyanis az Intel szerint a Meteor Lake fedélzetén található, Xe-LPG alapú iGPU-hoz képest az Xe2 architektúra köré épített új iGPU 50%-kal jobb teljesítményt nyújt majd játékok alatt. Az új iGPU alapját továbbra is az Xe magok adják, ám ezekből itt már a második generációt foghatjuk munkára. Ennél a dizájnál összesen 8 darab 512-bites vektormotor, 8 darab 2048-bites XMX mátrix matematikai motor, a 64-bites atomikus műveletek támogatása, valamint 192 KB-ra hizlalt megosztott L1 Cache található a szettben.

A legnagyobb újítást az Alchemist sorozatú iGPU dizájnhoz képest az, hogy itt már megjelenik az XMX motor. Az iGPU a 8 darab Xe2 maggal 1024 shadert tartalmaz, amelyek az XMX egységekkel karöltve összesen 67 TOPs-os teljesítményt tudnak felmutatni az AI jellegű terhelésformák esetében, a Ray-Tracing feladatokat pedig 8 darab RT egység tartja kézben.

A következő a sorban a médiamotor, ami továbbra is kínál hardveres gyorsítást az AV1-es tartalmak kódolásához és dekódolásához, valamint újításként bevezeti a VVC formátum dekódolásának hardveres gyorsítású támogatását, ami lényegében a H.266-os kodeket takarja. Ez az AV1-hez képest azonos minőség mellett csak 10%-kal kisebb fájlméretet hoz, cserébe viszont támogatja a 360 fokos videókat, a panorámanézetet, illetve az adaptív felbontást is.
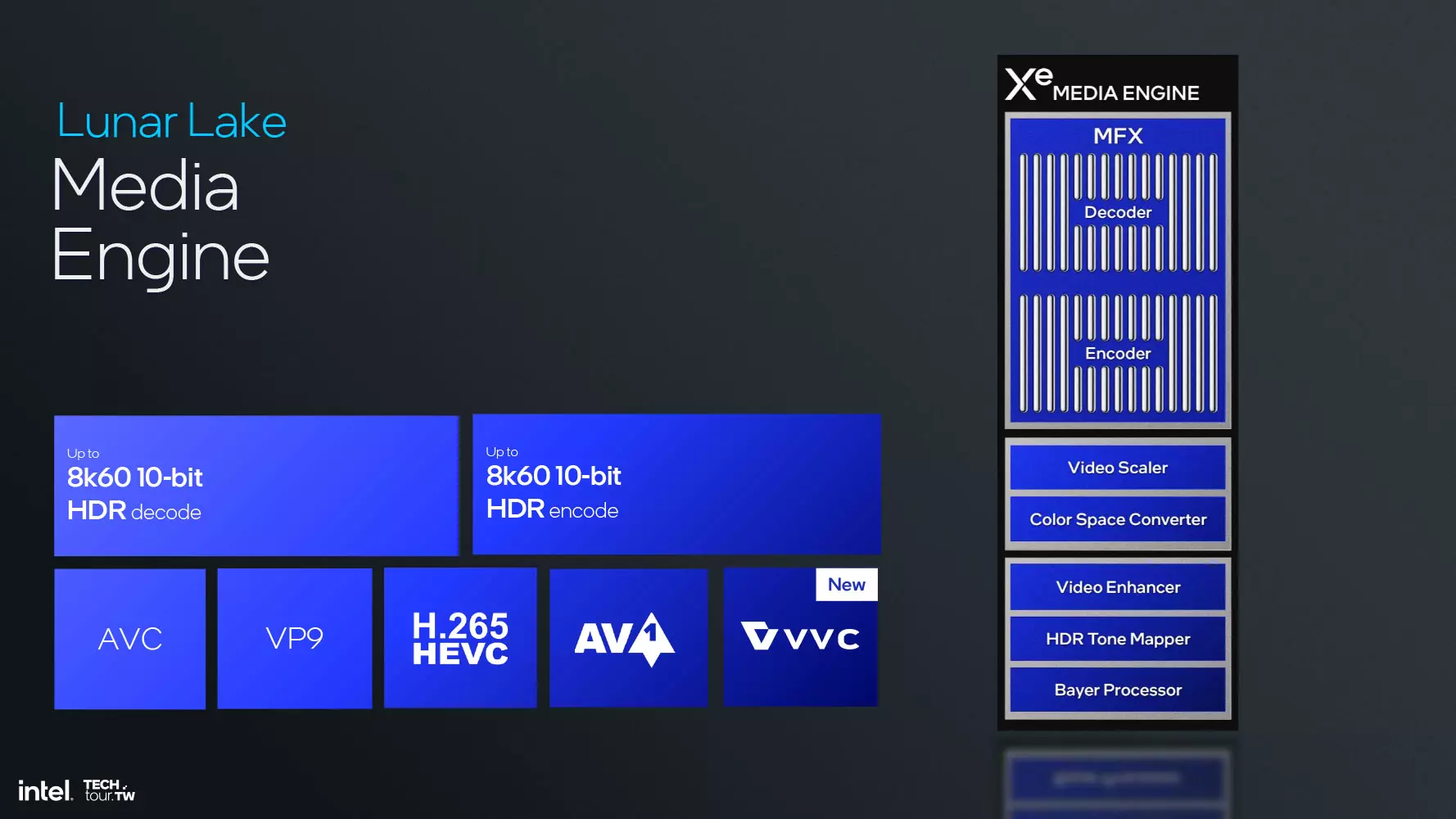
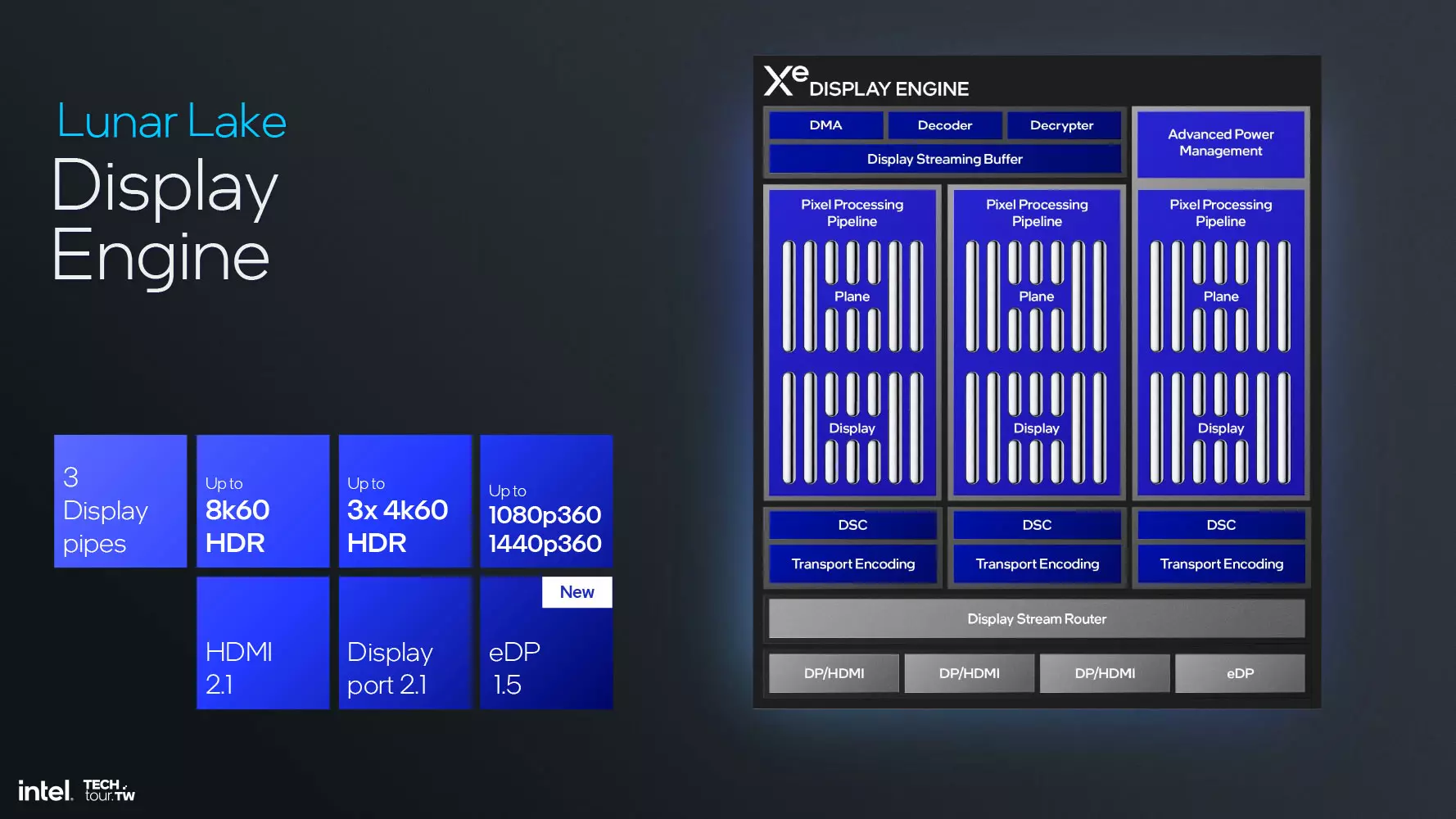
A kijelzőmotor immár eDisplayPort 1.5 támogatással érkezik, de ezzel együtt a HDMI 2.1-es és a DisplayPort 2.1-es szabványt is támogatja. Az eDP esetében a panel-önfrissítés, a szelektív frissítés, illetve az Adaptive Sync funkció egyaránt rendelkezésre áll, valamint Panel Replay funkciót is kapunk. Ezek együttesen segítenek abban, hogy csökkenjen a noteszgép fogyasztása, ugyanis csak a kijelzőnek azt a részeit frissíti a rendszer, ahol ténylegesen változás történt, vagyis, amit ténylegesen kell, nem az egész kijelzőt. Ezek persze nemcsak az energiahatékonyság miatt jöhetnek jól, hanem azért is, mert jobb vizuális élményt eredményeznek, hiszen általuk csökkenhet a kijelző késleltetése, illetve növekedhet a szinkronizálás pontossága is, és a folyékony képi megjelenítés is biztosítható.
Nagyot fejlődött az NPU

Mivel manapság a csapból is az AI folyik, illetve a Microsoft is megköveteli, hogy ütőképes NPU-t alkalmazzanak az egyes SoC egységek annak érdekében, hogy a Copilot+ PC kategóriába beférjenek, az Intel csapatának sem nagyon volt más választása, jelentősen növelniük kellett az NPU teljesítményét. A negyedik generációs NPU immár 48 TOPs-os maximális számítási teljesítményre képes INT8-as feladatok alatt, ami a harmadik generációs megoldáshoz képest, ami a Meteor Lake SoC egységek fedélzetén dolgozik, jelentős gyorsulásnak tekinthető. Utóbbi még csak 12 TOPs teljesítményt tudott felmutatni, vagyis ezen a téren négyszeres előrelépés mutatkozik, ami már elég ahhoz, hogy a Lunar Lake beférjen a Copilot+ PC kategóriába.
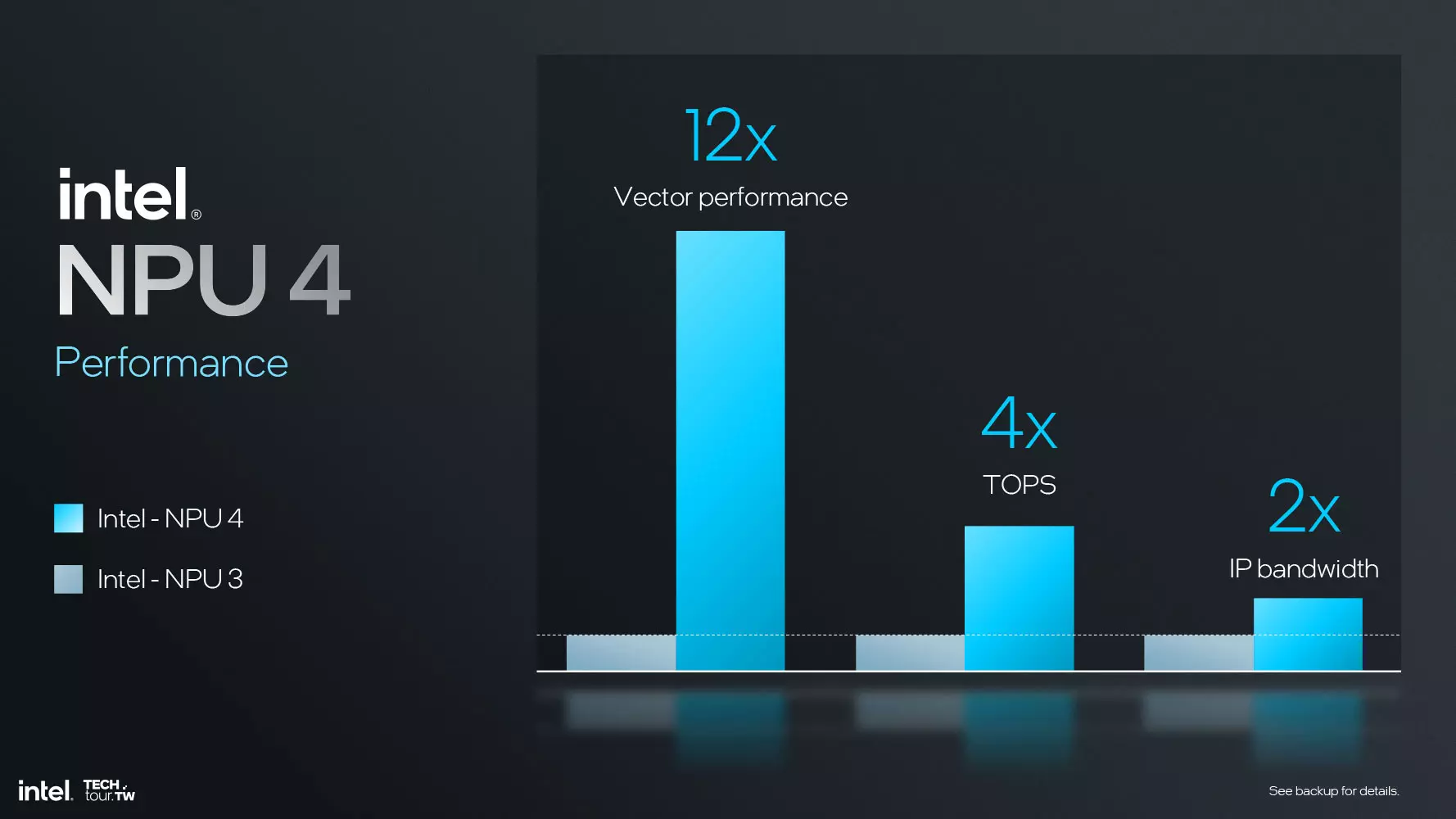
A gyorsulás részben annak köszönhető, hogy jelentősen fejlesztették az NPU architektúrát, például a Neural Compute Engine számát is növelték, méghozzá 2-ről egészen 6-ra, de ezzel egy időben az energiahatékonyság is nagyot lépett előre. A teljesítmény növeléséhez a DMA sávszélességet, illetve az L2 Cache kapacitását is növelni kellett, csak úgy, ahogy az órajelet is. Az energiahatékonyságot kétszeresére tudták növelni, hála az új gyártástechnológiának és a háttérben eszközölt egyéb változtatásoknak.
Az új MAC tömb esetében fejlett adatkonverziós képességek is rendelkezésre állnak, így valós időben, chipen belül lehet adattípusokat konvertálni, összevonhatóak különböző műveletek, valamint lehet módosítani a kimeneti adat szerkezetét is, ezáltal optimalizálható az adatfolyam és a késleltetés sem növekszik jelentősebb mértékben.
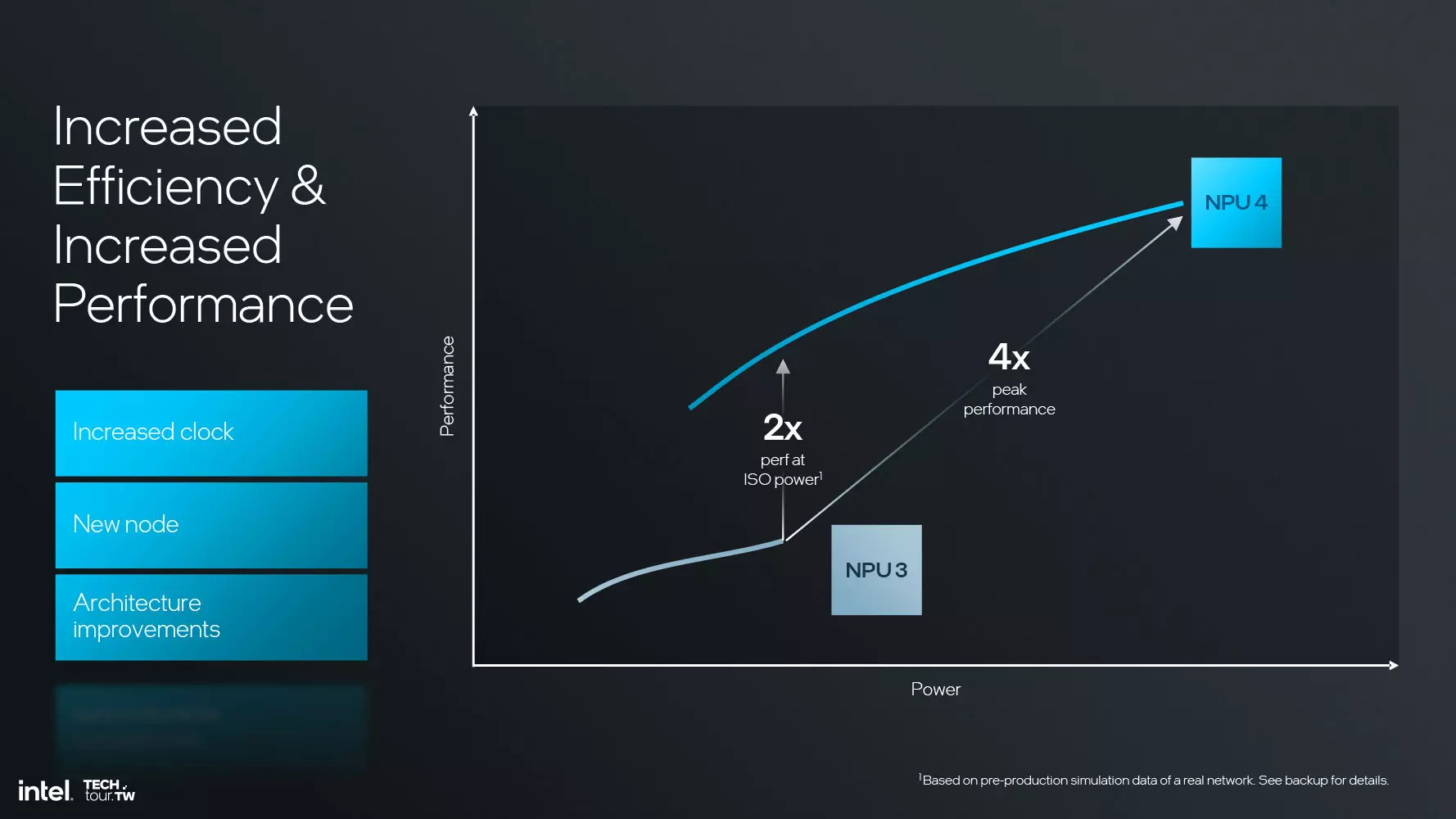
Összességében az NPU 4 esetében 12x nagyobb nyers vektorteljesítmény érhető el az NPU 3-hoz képest, az AI TOPS teljesítmény négyszeresére nőtt, az NPU és az összekötő közötti sávszélességet pedig kétszeresére emelték. Érdekes adalék, hogy az Intel szerint az AI teljesítmény 120 TOPs szintre növekszik a Lunar Lake érkezésével, ebben benne van az NPU, az iGPU és a CPU részleg teljesítménye.
Célkeresztben a Platform Controller Tile

Az I/O részleget kézben tartó csempe, ami a TSMC 6 nm-es csíkszélességével készült, számos újítást vonultat fel. A lapka tartalmaz Wi-Fi 7 vezérlőt, ami összesen maximum 5,8 Gbps-os vezeték nélküli sávszélesség elérésére ad lehetőséget, de ezzel együtt Bluetooth 5.4 támogatást is kínál.
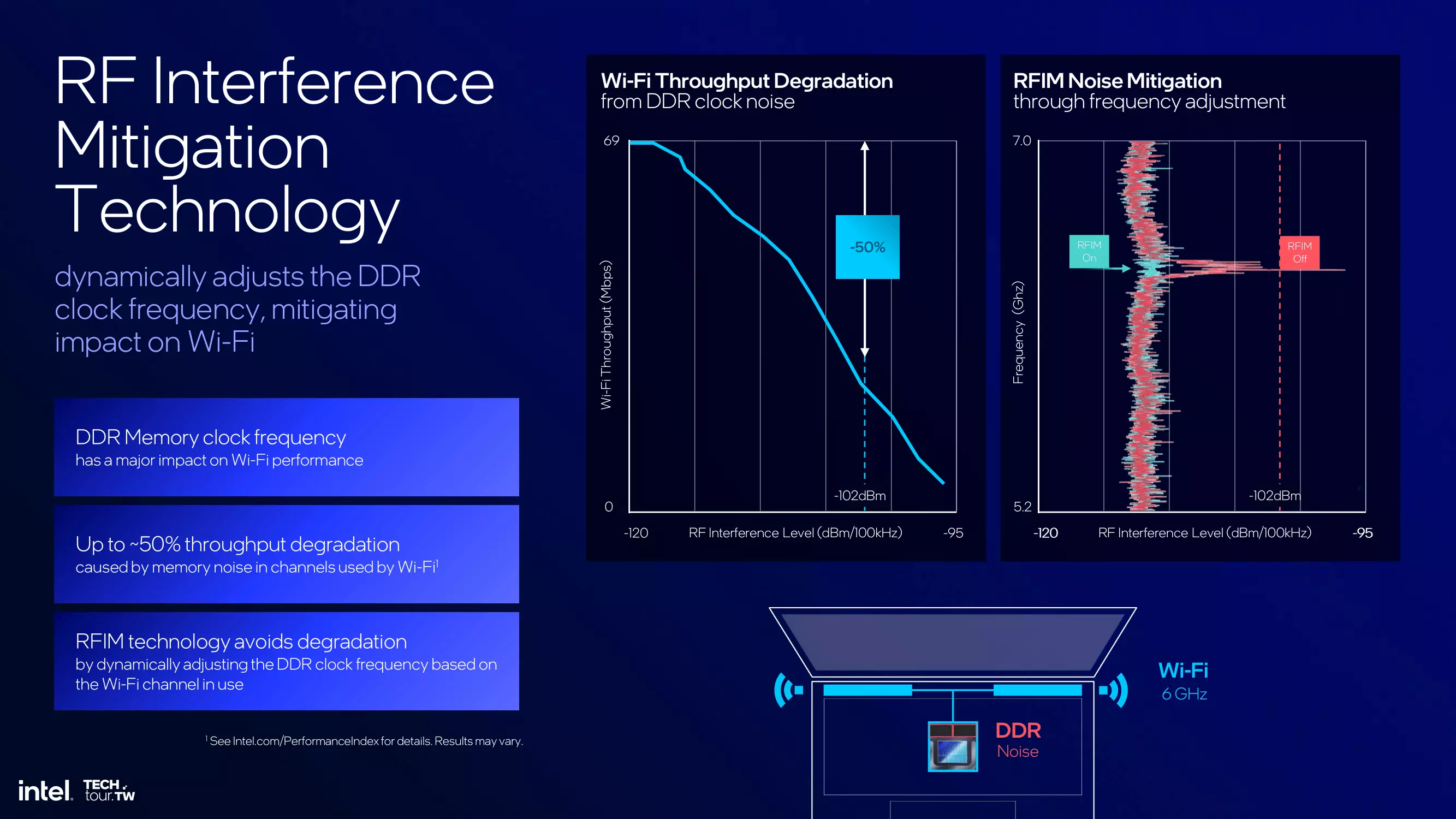
Hasznos újítás az RF Interference Mitigation Technology névre keresztelt eljárás, ami segít abban, hogy a Wi-Fi jelek még stabilabbak lehessenek, ezt pedig úgy éri el, hogy a DDR memória órajelét automatikusan módosítja a rendszer, hogy a Wi-Fi jelekkel ne alakuljon ki interferencia. Az újítás a memóriazajból eredő sávszélesség-csökkenés 50%-át tudja megakadályozni, vagyis összességében nagyobb vezeték nélküli teljesítményt lehet majd elérni, és a stabilitás is jobban alakulhat.
Nem hiányzik a fedélzetről továbbá a Thunderbolt 4 vezérlő sem, ami összesen maximum 3 darab 40 Gbps-os sávszélességű portot kezelhet. A lapka tartalmaz USB vezérlőket is, amelyek 5 Gbps-os és 10 Gbps-os USB 3.2-es portokat, illetve USB 2.0-s portokat kezelhet, ám mivel vékony és könnyű noteszgépekről van szó, ezekből nem sok áll majd rendelkezésre.
Ez a részleg tartalmazza a PCI Express vezérlőt is, ami összesen nyolc darab PCI Express sávval rendelkezik, ezek közül négy a 4.0-s, a másik négy pedig az 5.0-s szabvány köré épül. Hogy miért ennyire kevés a PCIe sávok száma? A Lunar Lake SoC egységek kifejezetten a vékony és könnyű noteszgépeket veszik célba, ahol erősen limitált a rendelkezésre álló hely, éppen ezért PCIe alapú eszközökből sem sokat kell kiszolgálni, hiszen egy dGPU alkalmazása eleve szóba sem jöhet. A négy darab 4.0-s sávot általános platformigényekre lehet felhasználni, a négy darab 5.0-s sáv pedig a gyors SSD kártyák kiszolgálását segítheti.
Amennyiben mégis szükségünk van videokártyára, azt a Thunderbolt 4-es porton keresztül külső videokártya ház segítségével csatlakoztathatjuk a rendszerhez, de akár zsebre vágható külső videokártyát is használhatunk. Az új processzorokhoz a korábban bemutatott Thunderbolt Share támogatás is jár, ami jelentősen javíthatja az együttműködést az irodában, de átlagfelhasználók számára is új lehetőségeket kínál, ahogy azt korábbi hírünkben már megírtuk.
Megjelenés
Az Intel csapata jelenleg úgy tervezi, a Lunar Lake mobil processzorok valamikor az év harmadik negyedévében debütálhatnak, ám azt egyelőre nem árulták el, pontosan mikor.
