Az AMD két nagyon fontos terméket indított hódító útjára az Advancing AI névre keresztelt rendezvényen, ahol a nagyobb AI teljesítményt nyújtó RYZEN 8040-es sorozatú mobil APU egységek is bemutatkoztak. A két fontos termék nem más, mint az Instinct MI300-as sorozat két tagja, azaz az MI300X típusú GPU alapú gyorsító, míg az MI300A típusú APU egység, ami lényegében az első APU egységnek tekinthető az adatközpontok szegmensében.
Az alapok
Az MI300-as sorozat két tagja egyformán négy darab, 6 nm-es csíkszélességgel készülő I/O chipletre támaszkodik, amelyekre eltérő számú és típusú komponensek kerülnek. A négy I/O chiplet fedélzetén összesen 256 MB-nyi Infinity Cache, összesen 4x32 darab 16-bites memóriacsatornát kezelő HBM3 memóriavezérlő, valamint összesen 128 darab PCI Express 5.0-s sávot kínáló PCIe vezérlő található. Utóbbinál négy darab x16-os dedikált sávot kap az Infinity Fabric vezérlő.

Az I/O lapkákra kerülnek az 5 nm-es XCD és/vagy az 5 nm-es CCD lapkák, amelyek közül előbbiek CDNA3 alapú feldolgozókat tartalmaznak, míg utóbbiak ZEN 4 alapú processzormagokkal rendelkeznek. Egy-egy I/O lapka tetejére vagy két ilyen XCD, vagy pedig három darab CCD kerülhet, modelltől függően. Az XCD lapka fedélzetén a 40 CU-ból összesen 38 CU aktív, míg a CCD esetében 8 darab ZEN 4 alapú processzormagot tartalmaz a fejlesztés.
A GPU alapú gyorsító, az MI300X

Az MI300X típusú, GPU alapú gyorsítónál úgy néz ki a felépítés, hogy a fentebb említett komponensek közül a négy darab I/O lapka fölé összesen nyolc darab CDNA 3 alapú XCD lapka kerül, ami összesen 304 aktív CU tömb jelenlétét eredményezi. Ezek mellé összesen nyolc darab 12hi típusú, azaz lapkaszendvicsenként összesen 12 HBM 3-as lapkával ellátott HBM 3-as memóriachip társul, összesen 192 GB-nyi kapacitást kínálva, 5,3 TB/s-os memória-sávszélesség mellett.
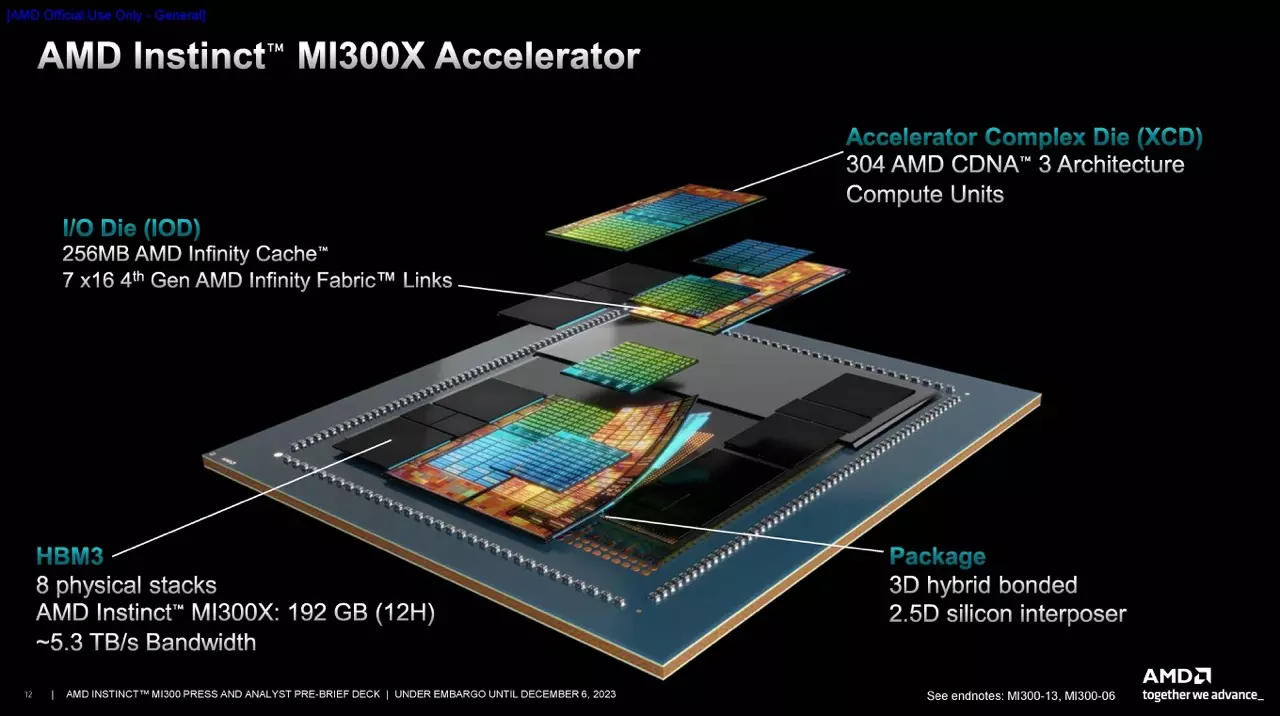
Az MI300X egy 750 W-os TDP kerettel rendelkező gyorsítókártya, amiből az AMD MI300X platformján belül összesen nyolc tud együtt dolgozni. Az egyes GPU-k között 896 GB/s-os adatátviteli sávszélességű Infinity Fabric összekötő teremt kapcsolatot, a rendszer kombinált számítási teljesítménye pedig a 10,4 PetaFLOP/s-os szintet is elérheti BF16/FP16 számítási módban. A teljes rendszer 1,5 TB-nyi HBM3-as fedélzeti memóriával rendelkezik.
A CPU és GPU magokkal egyaránt rendelkező MI300A, az első adatközpontokba szánt APU
Az MI300A már egy érdekesebb jövevény, ez ugyanis a CDNA 3-as GPU lapkákat és a ZEN4 alapú CCD lapkákat kombinálja, így APU formájában áll az adatközpontok rendelkezésére. Az újdonság lényegében olyan, mint az Nvidia Grace Hopper SuperChip sorozatú megoldásai, ám itt nem ARM, hanem x86 alapú processzormagokkal dolgozhatunk. Alapok terén ugyanazt az elvet követi ez a termék is, ami egyébként a világ első adatközpontokba szánt APU-ja, de itt már ZEN4 alapú processzormagok is jelen vannak a kínálatban. Utóbbiakból összesen három darabot tartalmaz a tokozás, ezek egyenként 8 processzormaggal rendelkeznek, vagyis az elméleti maximális magszám 24 lehet.

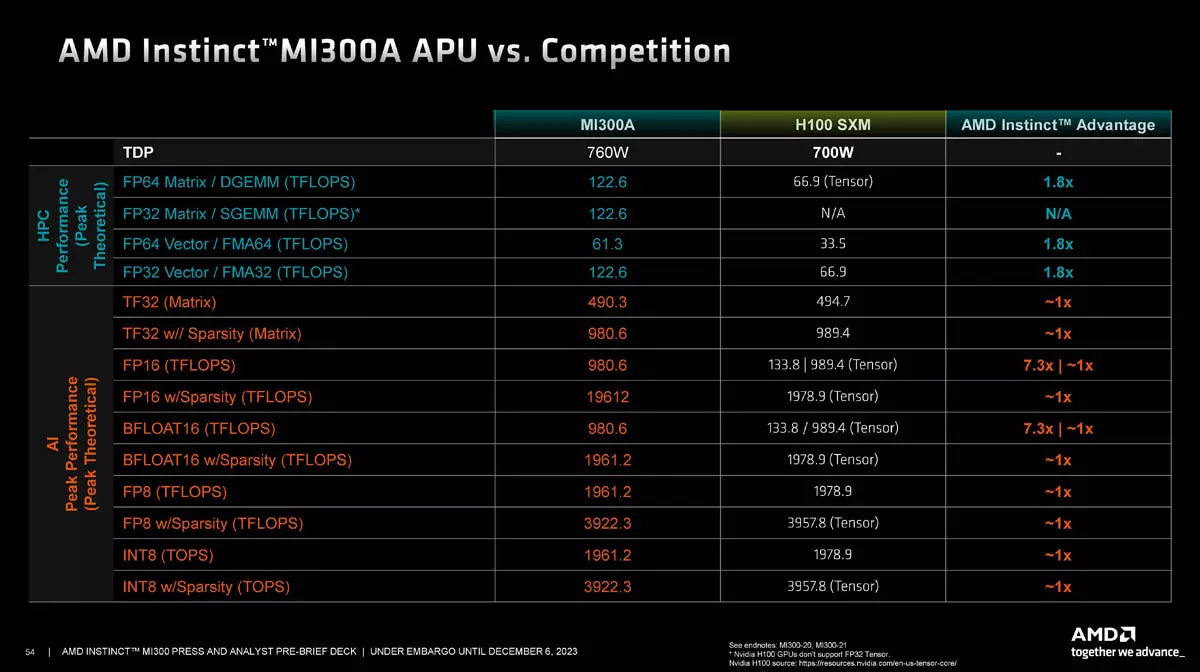
Mivel a CDD lapkák elveszik a helyet az XCD lapkáktól, így ezekből 8 helyett már csak 6 fogható munkára, ami 228 CU tömb jelenlétét eredményezi. Ez a fejlesztés kevesebb HBM3-as memóriát kapott, mint az MI300X: a 192 GB-nyi helyett „csak” 128 GB-nyi áll rendelkezésre, a memória-sávszélesség viszont ugyanúgy 5,3 TB/s maradt. Az AMD szerint ez a kapacitáscsökkenés nem azért következett be, mert a hőtermelés és a fogyasztás miatt muszáj lett volna meglépni, hanem azért, mert a terméket az adott célszegmensben jelentkező HPC és AI munkafolyamatokhoz optimalizálták. Noha a memória-kapacitás csökkent, az Nvidia H100 SXM GPU-jához képest még mindig 1,6x magasabb memória-kapacitás és memória-sávszélesség áll rendelkezésre, ami nem hangzik rosszul egy API-nál.

Az SH5-ös tokozású MI300A típusú APU egység alap esetben 360 W-os TDP kerettel rendelkezik, ám ez konfigurálható egészen 760 W-it. Az AMD a CPU és a GPU chipletek esetében dinamikus teljesítmény-elosztást alkalmaz, ami az aktuális terheléstől függően biztosít több TDP keretet az egyik vagy másik részleg számára. Az SH5 tokozás ugyanúgy LGA6096-os kiépítéssel dolgozik, mint az EPYC sorozat SP5-ös megoldása, viszont a kettő között nincs átjárás, lábkiosztás terén eltérőek.
Teljesítmény a gyártó szerint
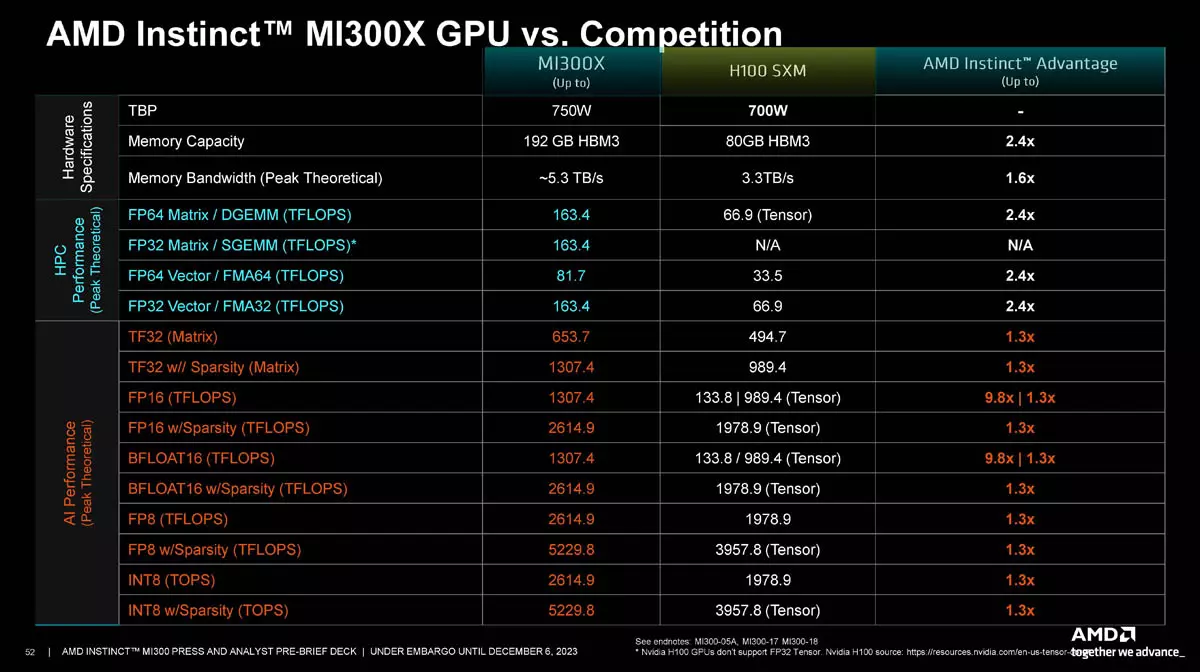
Az MI300X gyorsítókból álló MI300X platformot természetesen az Nvidia H100 HGX platformjával mérték össze, ugyanis mindkettő nyolc-nyolc darab gyorsítóból áll és azonos piaci szegmenseket vesznek célba. Nyers számítási teljesítmény terén az AMD szerint az MI300X platform 2,4x jobb FP32-es és FP64-es műveletek esetén, mint az Nvidia megoldása, míg az AI terhelésformákhoz passzoló INT8, FP8, BF16, FP16, illetve TF32 terhelésformák esetén akár 1,3x-os előnyt tudhat magáénak az MI300X platform.

Az AMD szerint az új platform 2,4x több memóriakapacitást kínál, ami igencsak jól jön, hiszen az extra memóriakapacitás miatt kétszer nagyobb neurális hálózatot tud kezelni a rendszer: tréning esetében 70 milliárd, dedukció esetében pedig 290 milliárd paraméterből álló modellek kaphatnak helyet a platformon, az Nvidia H100 HGX ennek a felét tudja. Teljesítmény terén egy 30 milliárd paraméterből álló MPT tréning terhelésforma esetén persze hasonlóan teljesített a két platform, ami mindenképpen jó hír lehet a piac számára, hiszen így az Nvidia GPU hiányos környezetben már az AMD termékei felé is érdemes lehet fordulni.

Az MI300A, vagyis az APU típusú gyorsító az AMD belsős tesztjei szerint 4X gyorsabb az OpenFoam HPC motorteszt alatt, mint a H100, ami igazából nagyon jól hangzik, de az összehasonlítás egy kicsit sántít: almát mérnek körtéhez. Ez a teszt igazából nagyon sokat profitál a CPU és GPU alapú számításból, illetve a megosztott memóriaterület nyújtotta előnyökből, plusz a terhelésforma jellege miatt is előnyben van az AMD újdonsága.
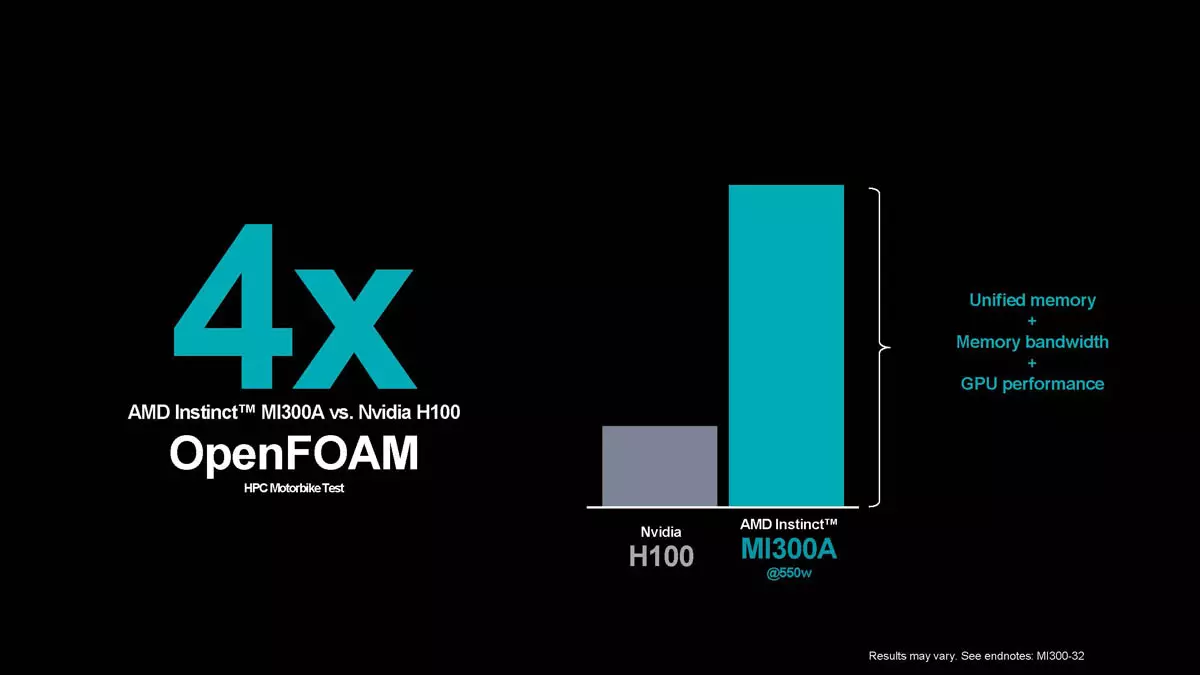
Sokkal pontosabb képet mutatna, ha a Grace Hopper GH200-as SuperChip eredményeit állítanák az MI300A teljesítménye mellé, akkor ugyanis egyenlőbbek lennének az esélyek, hiszen mindkét termék ötvözi a CPU és a GPU magokat. Az AMD szakemberei ilyen tesztet nem tudtak végezni és nem is találtak GH200 OpenFoam teszteredményeket sem. Később remélhetőleg ezzel is kiegészítik majd az összehasonlítást.
A végén következzenek a nyers teljesítményt összehasonlító diák, amelyek az alábbi galériában találhatóak.
Az Instinct MI300-as sorozat kellően versenyképesnek tűnik

Ez az AMD számára kifejezetten jó hír, hiszen az új termékekkel valamelyest csökkentheti az Nvidia egyeduralmát az AI és a HPC piacon, már amennyiben szélesebb körben is bizalmat szavaz nekik az iparág. Mivel az Nvidia GPU-k nem állnak rendelkezésre kellő mennyiségben, könnyen lehet, hogy az MI300-as sorozatú gyorsítókat hamarabb és nagyobb lendülettel kapja fel a piac, mint normál esetben, vagyis gyorsan növekedhet az AMD piaci részesedése, már amennyiben minden optimálisan zajlik. Az MI300-as sorozatú gyorsítók sorozatgyártása már javában tart, és a termékeket szállítja is partnereinek a vállalat.

{kind=link}