2023-ban hotra létre Elon Musk az xAI-t, a Grok nyelvi modellt fejlesztő vállalkozást, és mostanra elérte azt, hogy a nyelvi modellje tényleg a csúcsteljesítményt képes nyújtani. Nemcsak az xAI beszél nagyon pozitívan az új LLM eszköz eredményeiről, hanem a független elemzők is arra jutottak, hogy valóban példás produkcióval szolgál a Grok 4.
A bemutató során Elon Musk arról beszélt, hogy az új nyelvi modellre épülő generatív mesterséges intelligencia már az összes diplomás diáknál okosabb minden tudományos ágazatot egybe véve. Ez persze azért elég erős kijelentés, de megszokhattuk már az üzletembertől, hogy szeret erősen fogalmazni. Azt is elmondta, hogy véleménye szerint a Grok már kellően potens ahhoz, hogy tudományos felfedezéseket tegyen.
„Néha talán hiányzik belőle a józan ész, és még nem talált fel új technológiákat vagy fedezett fel új fizikát, de ez csak idő kérdése.” – mondta Musk, finoman utalva azért arra is, hogy ez elmúlt napokban volt gond a chatbottal bőven. Az xAI-nak váratlan munkát okozott a szolgáltatás azzal, hogy antiszemita „egyéniséget” öltött magára, és emiatt számos megszólalását utólag törölni kellett.
Két verzióban lesz elérhető a Grok új generációja, az alap a Grok 4, és a nagyobb számítási kapacitást igénylő, több paraméterrel dolgozó pedig a Grok 4 Heavy. Ez utóbbira az xAI már úgy hivatkozik, hogy az több MI ügynök szerepét is betölteni képes verzió lesz. Nagyon érdekesen hangzik ez, a gyakorlatban elvileg arra lesz képes a Grok 4 Heavy, hogy párhuzamosan több generatív MI ügynököt ereszt rá egy adott feladatra, és a végén ezek eredményeit összefésüli. Olyan ez, mint amikor egy munkacsoport egy problémán közösen dolgozik a legjobb válaszokért.
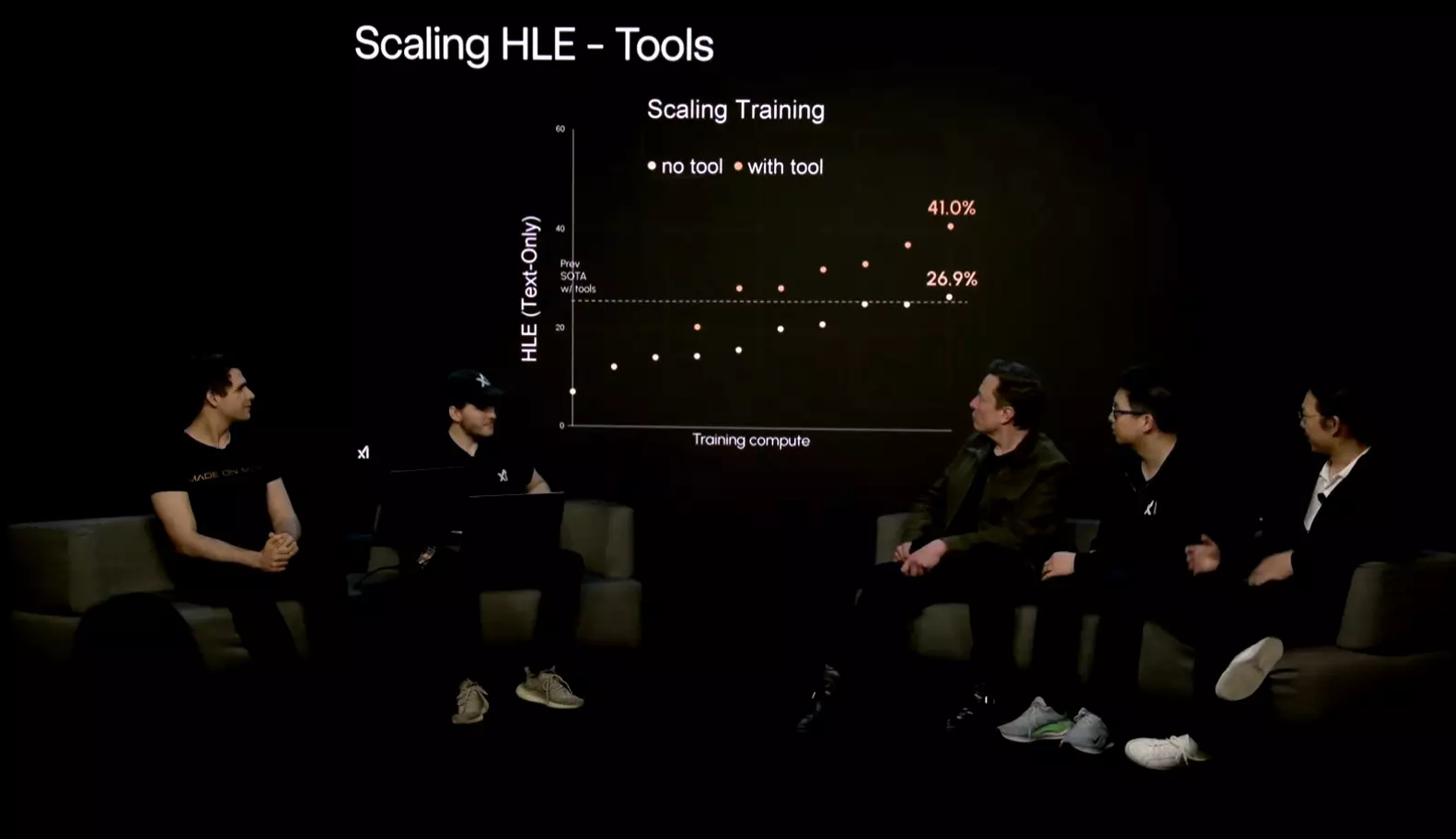
Ma már számtalan MI teszt van a modellek megmérettetésére és pontozására. Ezek között az egyik legnagyobb kihívást jelentő a „Humanity’s Last Exam”, melyben több mint 2500 kérdésre kell szövegesen válaszolnia a chatbotoknak. Ebben a legtöbb nyelvi modell 10% alatti pontossággot bír elérni, maroknyi opció tud 10-15% között teljesíteni, és csak a legjobbak vannak 20% körül. Hivatalosan a csúcsot a Gemini 2.5 Pro jelenti 21,6%-kal, amit az o3 (OpenAI) követ 20,3%-os teljesítménnyel.
Ezekhez képest a Grok 4 már képes 25,4 százalékos pontosságot felmutatni. Ez igazán jól mutat az újdonság neve mellett, noha annyit azért hozzá kell tenni, hogy az OpenAI a Deep Research eszközt is bevetve korábban már összehozott egyszer 26,6%-ot.
Az xAI a Grok fejlesztéséhez és futtatásához már 200 ezer GPU-t felvonultató adatközpontot üzemeltet. A Colossus (Memphis Supercluster) névre hallgató hely kapcsán legutóbb arról szóltak a hírek, hogy egyre nehezebben tudja a vállalat megoldani az áramellátást, ahogy a számítási kapacitást folyamatosan emelik. Elon Musk végső célja az lenne, hogy egymilliós „GPU-hadsereget” állítson fel egyetlen óriási adatközpontban.
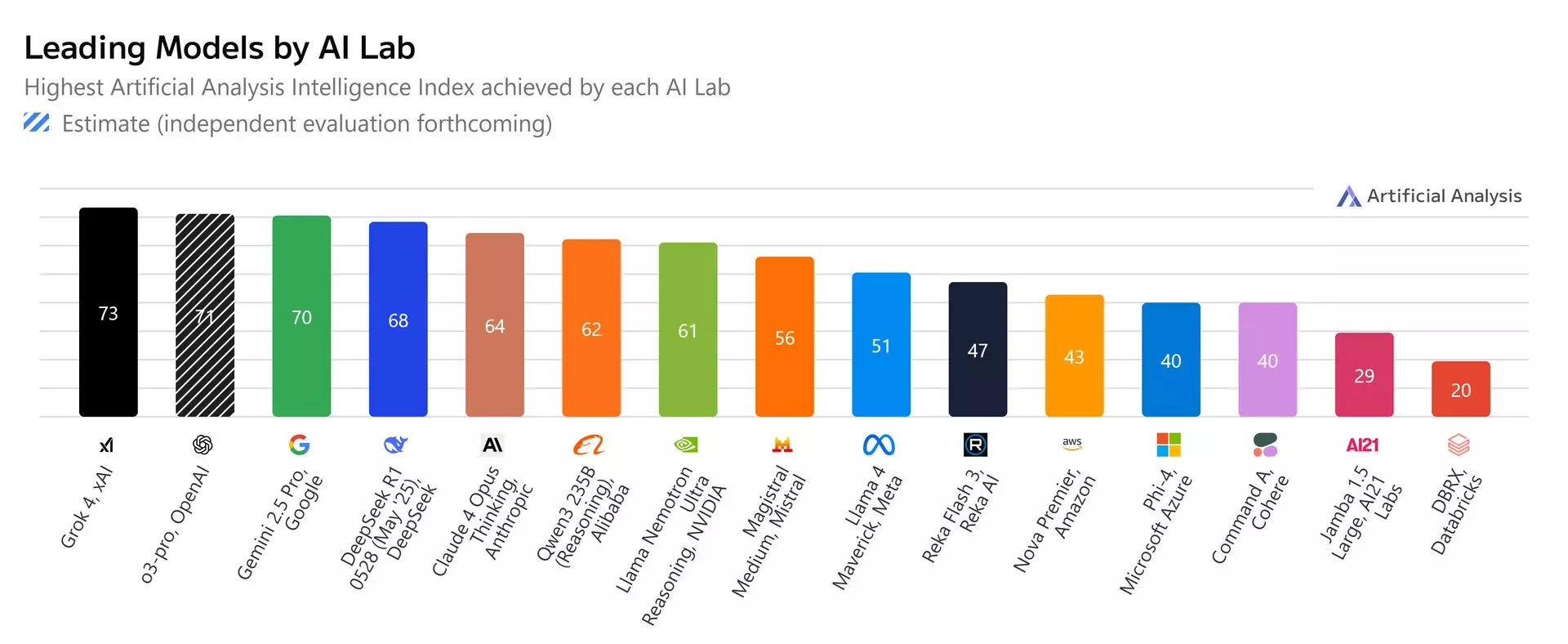
Az első független elemzések is azt erősítették meg, hogy rendkívül potens eszközzel van dolgunk. Az MI modellek tesztelésében jártas Artificial Analysis saját komplex tesztjében minden eddiginél magasabb pontszámot tudott felmutatni a Grok. 73 pontot ért el a teljes tesztcsomag lefuttatását követően, miközben eddig a rangsorban az OpenAI által fejlesztett o3-pro modell vezetett 71 ponttal, és eléggé szoros a mezőny eleje. Az éllovasokat 70 ponttal követi a Gemini 2.5 Pro, és a dobogóról éppen lecsúszott DeepSeek R1 68 ponttal büszkélkedik. A Claude 4 Opus már csak 64 pontot ért el, de a Meta áll ebben igazán rosszul a Llama 4-gyel produkált 51 pontjával.
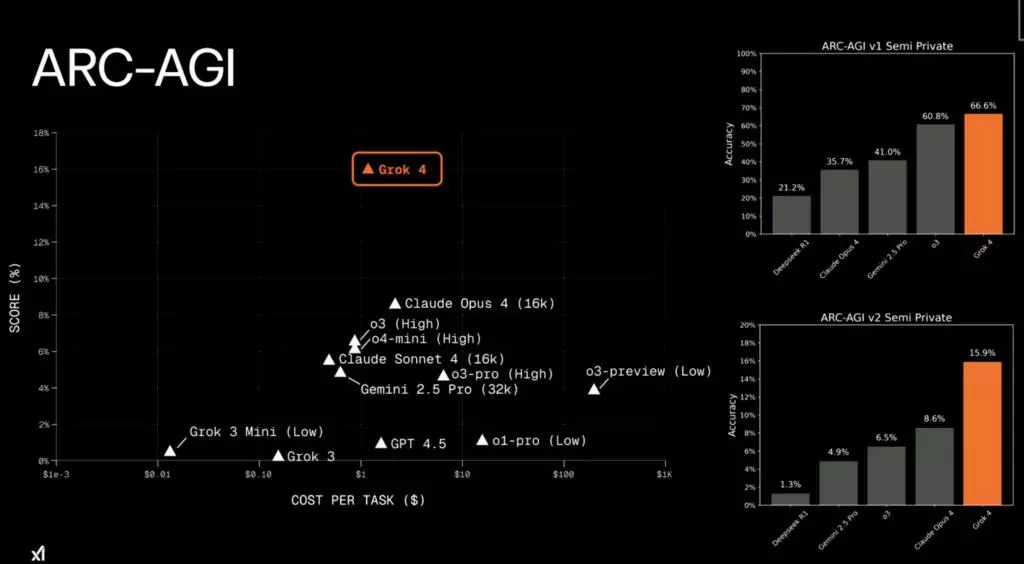
A non-profit ARC Prize független tesztjében a Grok 4 teljesen új szintet ért el. A rendkívül nagy kihívást jelentő ARC-AGI v2 teszt keretében eddig a legjobb a Claude 4 Opus modell volt az elérhető megoldások közül, és az csak 8% körüli teljesítményt volt képes összehozni. Minden modell 10% alatt maradt egészen mostanáig, a Grok 4 ugyanis 15,9%-ot ért el, áttörve ezzel egy olyan határt, amit eddig még egyetlen nyelvi modellnek sem sikerült.
A Grok 4 bemutatóján technikai részletekről nem nagyon volt szó, de mostanra kiderült, hogy a nyelvi modell 256 ezres kontextusablakot használ, ami a mai mezőnyben már nem kiemelkedő, de nagyobb mozgásteret ad az eddigi kereteknél. Szöveget és képet egyaránt fel tud dolgozni, de a multimodális lehetőségein még dolgoznia kell a fejlesztőcsapatnak. Egyelőre viszonylag költséges az üzemeltetése a Grok 4-nek (grok-4-07-09), 3-6 dollárba került 1 millió token feldolgozása, és 15-30 dollár ugyanennyi információ generálása.
Az xAI részben ezért nem méri olcsón a mesterséges intelligenciát. A Grok 4 egyszerű eléréséhez havi 30 dollárt kell kifizetnie az érdeklődőknek, ami éppenséggel még nem kiemelkedően sok a mezőnyben, a legtöbb chatbotnál 20-30 dolláros opciók vannak alapjáraton. Viszont a 300 dolláros SuperGrok Heavy fantázianévre keresztelt csomag már igencsak meredeken hangzik. A SuperGrok Heavy előfizetők elsőként vehetik használatba a Grok 4 Heavy modellt, és a jövőben bevezetésre kerülő újításokat, kísérleti funkciókat is a leghamarabb tesztelhetik.
