
Az Nvidia az idei Graphics Technology Conference (GTC 2023) alkalmával nem mutatott be új GPU architektúra köré épülő gyorsítókártyákat, viszont egy különleges újítással mégis előrukkolt ezen a téren, ami a Hopper architektúrában rejlő lehetőségeket próbálja kamatoztatni. A két GPU-t tartalmazó, 3 darab NVLink kapcsolatot használó termék kifejezetten a mesterséges intelligenciával kapcsolatot feladatok gyorsítására készült, azon belül is a nagy nyelvi modellek kezelésére specializálódott (LLM), mint amilyen például a 175 milliárd paraméterből álló ChatGPT.
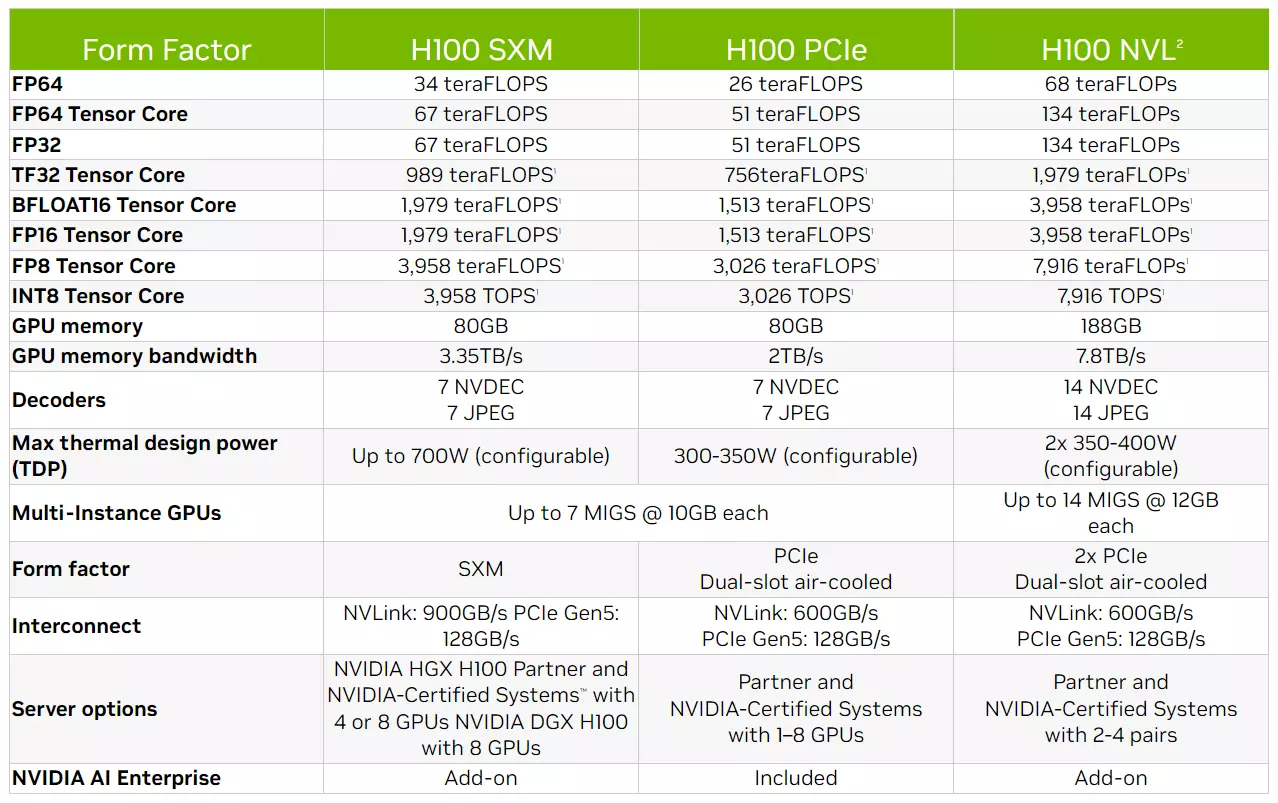
A H100-as GPU köré épített megoldás lényegében két összekapcsolt PCI Express bővítőkártya formájában érkezik és a H100 NVL nevet viseli, ahol az NVL az NVLink összekötőre utal. Míg a normál PCIe formátumú H100-as gyorístókártyáknál az elérhető fedélzeti memória kapacitása 80 GB, ami hamar elfogyhat az említett AI terhelésformák esetében, addig a friss H100 NVL már összesen 188 GB-nyi fedélzeti memóriával rendelkezhet, azaz egy GPU-ra 80 GB helyett immár 94 GB-nyi HBM3-as fedélzeti memória kapcsolódik.

Ennél a verziónál mind a hat HBM3-as lapkaszendvics elérhető, vagyis 6144-bites memória-adatsín használatára nyílik lehetőség, ami összesen 7,8 GB/s-os memória-sávszélességet eredményez – egy-egy GPU 3,9 GB/s-os memória-sávszélességgel rendelkezhet. A számítási teljesítmény egyszeres pontosság esetén 134 TFLOP/s, míg dupla pontosságnál 68 TFLOP/sps, FP16-os terhelésformáknál pedig3958 TFLOP/s-os értékre számíthatunk. Az újdonság a hivatalos adatok alapján az SXM modell számítási teljesítményének pontosan a dupláját tudja, ami arra utalhat, hogy két ilyen GPU került a fedélzetre, vagyis 2 x 16986 darab FP32-es CUDA maggal és 2 x 528 darab Tensor maggal rendelkezhet a GPU. A két PCI Express formátumú kártya között 18 linkből álló NVLink 4-es kapcsolat húzódik, ami 900 GB/s-os adatátviteli sávszélesség elérését teszi lehetővé, hála a három darab NVLink hídnak.
Az Nvidia szerint a H100 NVL óriási teljesítménynövekedést hoz például a GPT3-175B típusú nagy nyelvi modell esetében is – ez lényegében a most oly népszerű ChatGPT-t takarja. A HGX-A100-as rendszert alapul véve, ha 8 darab A100-as és 8 darab H100 NVL gyorsítókártya teljesítményét vetjük össze, azt láthatjuk, hogy a H100 NVL alapú rendszer 12x gyorsabb inferencia terén, mint A100 alapú társa. A H100 NVL lényegében egy igazi rétegtermék lesz, ami a leggyorsabb PCI Express formátumú H100-as opcióként érhető el, és ezzel egy időben a lehető legtöbb fedélzeti memóriával is rendelkezik az Nvidia kínálatán belül.
A H100 NVL gyorsítókártyák szállítása az év második felében indulhat meg, arról azonban még nem esett szó, hogy az újdonság mennyibe kerül majd. Mivel csúcskategóriás GH100-as GPU-t használnak a termékhez, ráadásul két GPU-s rendszerben, így egészen biztos, hogy rendkívül borsos ára lesz a gyorsítókártyának, főleg most, hogy az LLM „piacon” éppen hatalmas robbanás következik be, amelynek minden kisebb és nagyobb szereplő próbál minél előbb a részesévé válni.
