
Az olyan nyelvi modellek, mint a Gemini, általában a világunkat egyetlen statikus pillanatban dolgozzák fel. Ebben hoz változást az Agentic Vision bevezetése a Gemini 3 Flash modell mellett, és a Google elmondása szerint ez jelentős javulást hozhat azokban a feladatokban, amik vizuális tartalommal kapcsolatosak.
Elmondta a keresőóriás, hogy az a gond a legtöbb nyelvi modellel, hogy ha egy vizuális feladat végrehajtása során valamilyen részletet hiányolnak, akkor arra kényszerülnek, hogy kitalálják azt, és egyebek mellett például emiatt is hallucinálhatnak. Az új Agentic Vision funkciónál már az elnevezésnek megfelelően ágens működésről beszélhetünk a vizuális érzékelésnél. Egy aktív vizsgálaton fognak átesni a promptban foglal képek kódvégrehajtással. A jövőben pedig egyéb eszközök is megjelenhetnek ennek keretében.
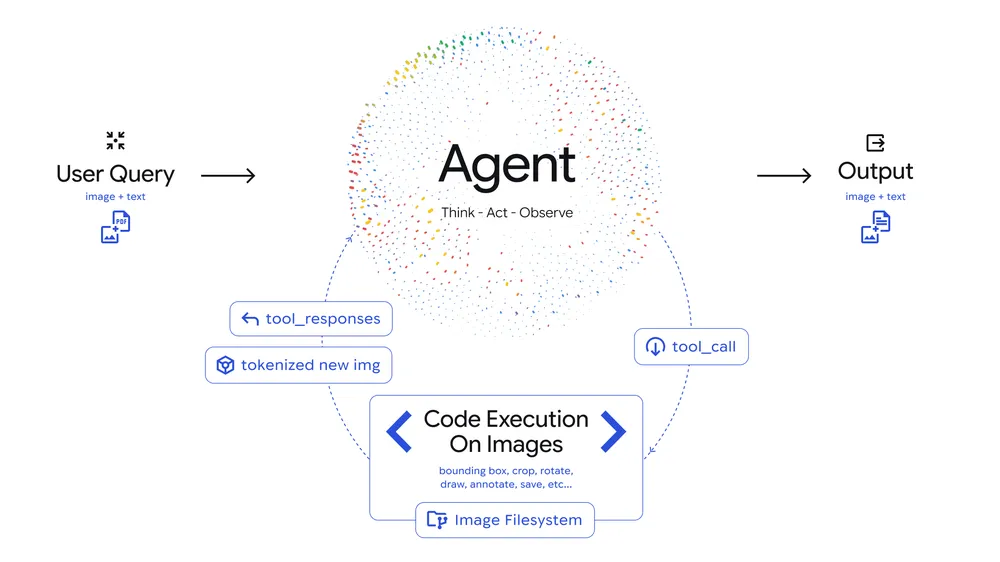
A Gemini 3 Flash és az Agentic Vision kombinációjával egy interaktív Think–Act–Observe folyamat indul majd el. Ez időigényes lesz, de adott esetben sokkal jobb, pontosabb válaszokat fog szülni.
Első lépésben (Think) az érvelés keretében értelmezi a modell a feladatot, és létrehoz egy többlépcsős végrehajtási tervet, a releváns vizuális információk megszerzésére. Második lépésben (Act) a modell létrehoz egy Python kódot, ami megoldja nagy pontossággal a képelemzést, -manipulációt. Harmadik lépésben (Observe) pedig visszakapja a szükséges részletet a modell, ami alapján képes válaszolni, ha pedig még több részletre van szüksége, indul újra a folyamat.
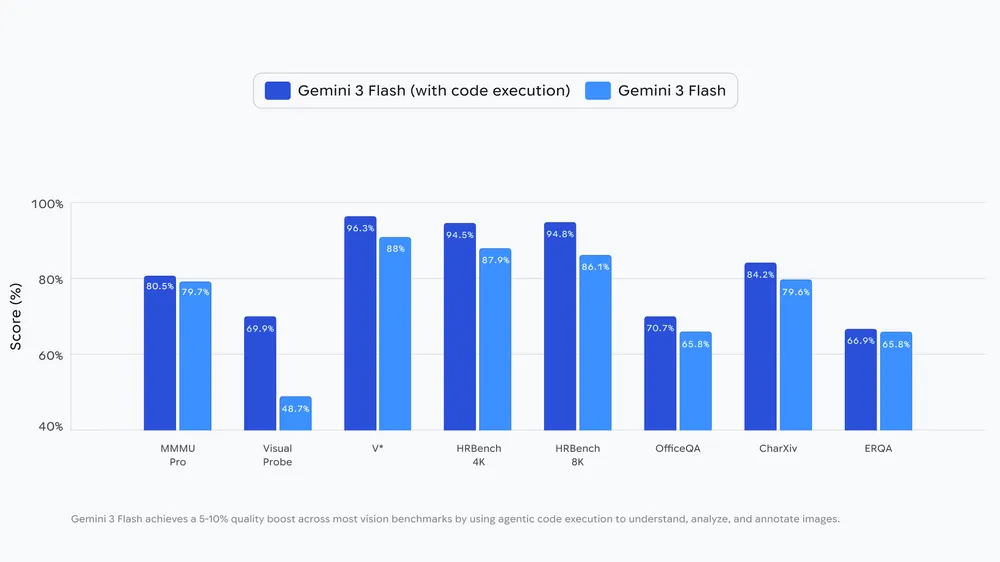
A Google mérései szerint a Gemini 3 Flash az Agentic Visionnel rengeteg helyzetben fog jobban teljesíteni, adott esetben akár egészen jelentős fejlődést is tapasztalhatnak majd a felhasználók. A Visual Probe tesztben 48,7 százalékról 69,9%-ra tudott előrelépni a modell, a HRBench 8K-ban pedig 86,1%-ról 94,8 százalékra javított. Minden helyzetben jobban teljesít majd az új feldolgozási módszerrel a rendszer, ha a bemeneti oldalon van vizuális tartalom.
A Google-nek már megvan a terve arra is, hogy fejlessze tovább a friss a rendszert a jövőben. Például egyre több képmanipulációs lehetőséget kap majd az Agentic Vision, ami jelenleg vágni, forgatni, megjegyzéseket felvenni, számolni képes. Új eszközök bevetésének lehetőségét is vizsgálja a vállalat, az Agentic Visiont pedig a Gemini 3 Flash után más modellekhez is szeretnék hozzáadni.
