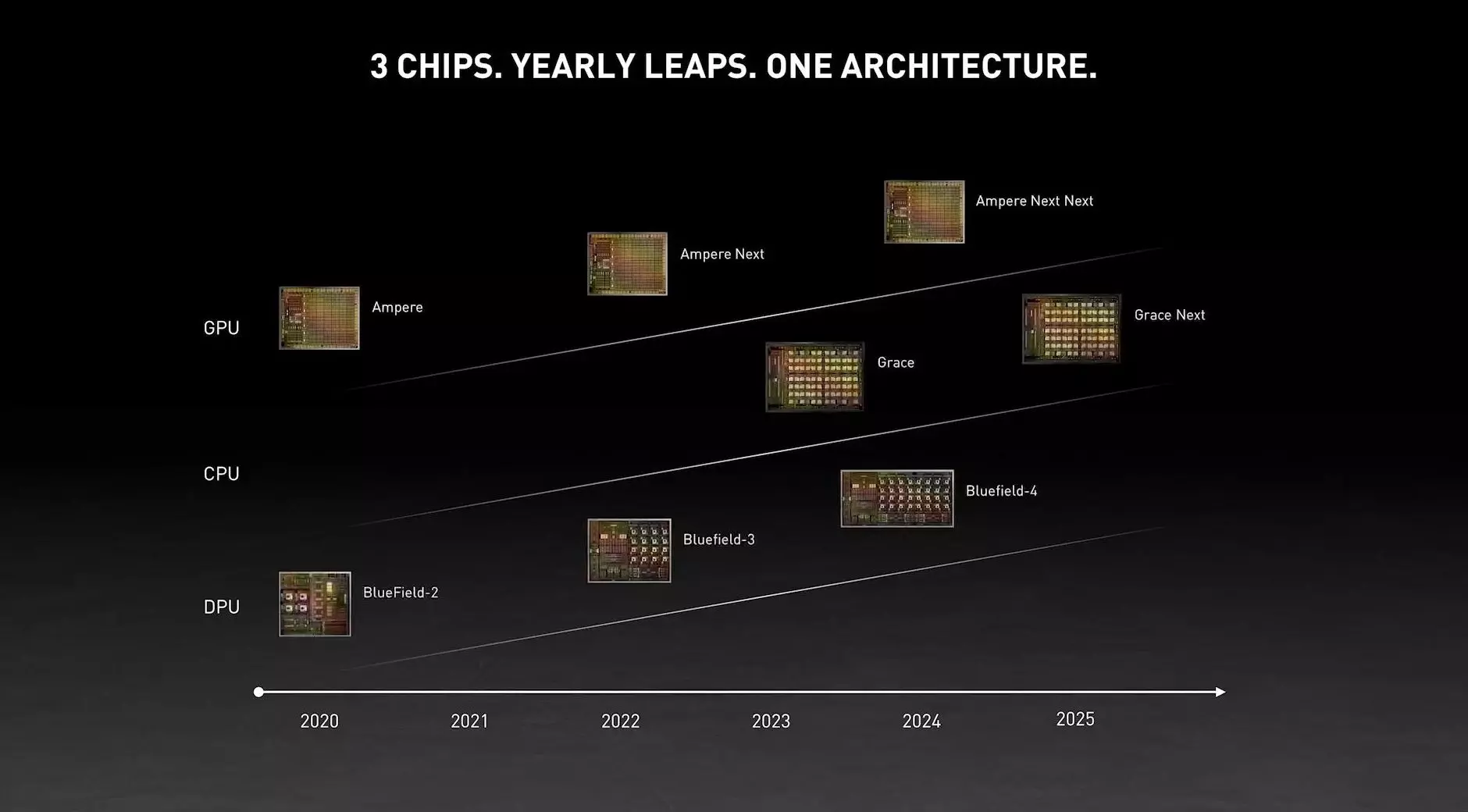
Az Nvidia a GTC 2021 alkalmával több érdekes termékről is hírt adott, amelyek közül a legérdekesebb egy szerveripari fejlesztés, ami nem más, mint egy új, ARM alapokon nyugvó SoC egység, a Grace. Az ARM alapú processzormagokkal ellátott újdonság Grace Hopper után kapta a nevét, aki úttörő szerepet töltött be a számítógép-programozás terén, valamint az amerikai haditengerészet ellentengernagyaként is számon tartották.
A Grace lényegében az Nvidia második próbálkozása az adatközpontok szegmenségben, ugyanis egy saját fejlesztésű, ARM alapokon nyugvó processzorral már előrukkoltak nagyjából egy évtizeddel ezelőtt a Project Denver keretén belül, ám ott az egyedi fejlesztésű processzormagok nem voltak elég ütőképesek a szerverpiaci sikerhez, sosem tudtak igazán kitörni a mobil SoC egységek világából. A második próbálkozás alkalmával már biztosra próbálnak menni, ugyanis a Grace nem egy saját fejlesztés, hanem az ARM Neoverse következő generációs verziója köré épül, vagyis saját fejlesztése helyett meglévő technológiát licencel majd a gyártó, ezek a processzormagok pedig számos egyéb vállalat által is használatban lesznek, azaz elterjedtebb megoldásokról lehet szó.

Hogy miért is van szükség egy saját SoC egységre a szerverek szegmensében? Gyakorlatilag azért, mert az Nvidia jelenleg nem tud kellően gyors kapcsolatot biztosítani az aktuális processzorok és az aktuális GPU-k között, hiszen sem az Intel, sem az AMD platformjai nem rendelkeznek NVLINK támogatással, a PCI Express alapú kapcsolatok pedig erősen behatárolják a lehetőségeket, ezeken keresztül ugyanis lényesen lassabb kommunikáció valósítható meg a GPU, a CPU és a RAM között. A vállalat az OpenPOWER alapítvány keretén belül már megpróbálkozott az NVLINK terjesztésével, amelynek keretén belül NVLINK támogatással ellátott POWER9-es rendszerek készülhettek volna, ám ez a kapcsolat nem váltotta be a hozzá fűzött reményeket, így saját kezébe vette az irányítást a vállalat.
A Grace segítségével persze nem az Intel Xeon és az AMD EPYC szerverprocesszoroknak akar közvetlen konkurenciát állítani az Nvidia, sokkal inkább arról van szó, hogy egy speciális platformot akar alkotni, ami kifejezetten előnyös választás lehet bizonyos terhelésformákhoz, főként a mesterséges intelligenciára támaszkodó feladatokhoz.

Az új SoC egységgel kapcsolatban egyelőre túl sok információt nem osztott meg a vállalat, ugyanis a főként nagy neurális hálózatok kiszolgálásához készülő termék majd csak 2023 folyamán debütálhat. A Grace feladata lesz, hogy betöltse azt az űrt, ami a szerverpiacon tátong az Nvidia háza táján: segít az NVLINK-ben rejlő lehetőségek kiaknázásában, ugyanis mind a GPU-k közötti, mind pedig a CPU és a GPU közötti kommunikáció esetén elérhetővé teszi az NVLINK támogatást. A SOC egységek között várhatóan 600 GB/s-os NVLINK 4 kapcsolat húzódik, míg a GPU és a CPU közötti kapcsolatot 900 GB/s-os NVLINK 4-es összekötő biztosíthatja. Maga a SoC várhatóan LPDDR5X fedélzeti memóriát használhat, természetesen ECC támogatással karöltve, legalább 500 GB/s-os memória-sávszélesség mellett. A Grace SoC mellé ráadásul egy Nvidia GPU is kerül majd, ami teljes sávszélességgel érheti el a rendszermemóriát, valamint a teljes rendszer egy egységes megosztott memória címteret használhat.
Teljesítmény terén egyelőre úgy tűnik, a Grace processzormagokkal ellátott SoC 300 pont felett teljesíthet a SPECrate2017_int_base_throughput tesztben, vagyis nagyjából a második generációs AMD EPYC processzorokkal lehet egy szinten. Arról persze nem esett szó, a processzormagok pontosan milyen felépítéssel rendelkeznek, valamint a neurális feldolgozást segítő optimalizációkról sem esett szó, így ezen a téren egyelőre nem túl tiszt a kép.
Az Nvidia azt is megemlítette, hogy az a célja, hogy az 1 billió paramétert tartalmazó modelleknél 10x magasabb teljesítményt érjenek el, mint a mai rendszerek, ami azt jelenti, hogy egy 64 modulból álló Grace SoC egységgel és A100-as GPU-val felszerelt rendszer, ami elméletben már NVLINK 4 támogatást használ, az említett modell tréningezéséhez szükséges időt 1 hónapról mindössze 3 napra rövidíti le. Ez azt is jelenti, hogy egy 500 milliárd paraméterrel rendelkező modell esetében valós időben folyhat a dedukció egy nyolcmodulos rendszerben, ami elég impresszíven hangzik.
Ezek a Grace modulok várhatóan elérhetőek lesznek HGX alaplapok és DGX rendszerek formájában, valamint minden egyéb olyan termékben, amelyek használják az említett lapokat. A jövőben a Grace elég nagy szerepet kap az Nvidia termékpalettáján, már ami a szerverekbe szánt megoldásokat illeti.
És az érkező fejlesztésre már a szuperszámítógép-fürtök szegmensében is van igény, hiába csak 2023-ban kezdődik meg a Grace modulok szállítása. Az egyik vevő a Swiss National Supercomputing Centre (CSCS), a másik pedig a Los Alamos National Laboratory lesz (LANL), amelyeknek a HPE Cray csoportja építi meg a kész rendszereket.
A CSCS esetében a Xeon processzorokkal és Nvidia P100-as gyorsítókártyákkal ellátott Piz Daint helyére kerül az új fejlesztés, amelynek neve Alps lesz. A cél a 20 ExaFLOP/s-os AI számítási teljesítmény elérése lesz, amit a processzor mellett a Cuda és a Tensor magok biztosítanak. A tervek szerint az Alps 2023-ban a világ leggyorsabb AI-központú szuperszámítógép-fürtje lehet.

A LANL esetében már nem derült ki, milyen teljesítményszintet vesznek célba, csak annyi biztos, hogy a piacvezető teljesítményosztály szerepel a célkeresztben, jelentsen ez bármit is. Az új szuperszámítógép-fürtöt egyebek mellett 3D szimulációk készítésére is használni fogják majd az AI-központú terhelésformák kiszolgálása mellett. Az amerikai megrendelők közül lényegében az LANL lesz az első, aki Grace alapú szuperszámítógép-fürtöt kaphat, ez a rendszer 2023-ban kerül leszállításra.
