
Az Nvidia rendkívül erős pozíciót képvisel az AI gyorsítók piacán, hála az Ampere és Hopper alapú GPU-t használó gyorsítóinak, amelyek óriási teljesítményt kínálnak és hatalmas népszerűségnek örvendenek, így a vállalat lényegében egyeduralkodóvá nőtte ki magát ebben a szegmensben. Korábban már volt szó arról, hogy rövidesen érkezhetnek a Blackwell architektúra köré épülő AI gyorsítók, amelyek óriási teljesítményt kínálhatnak majd, ezek a tegnapi GTC 2024 alkalmával be is mutatkoztak, igaz, csak részben, ugyanis formális bemutatón nem lőtte el a gyártó az összes puskaport, bőven maradtak még megválaszolásra váró kérdések.

Az már nem titok, hogy a Blackwell architektúra köré két fontos termék épül, az egyik a B200-as GPU, míg a másik a GB200-as Superchip, ami két darab B200-as GPU-val és egy ARM alapú Nvidia Grace processzorral rendelkezik. A B200 a jelenlegi Hopper H100-hoz képest, ami az Nvidia AI piaci kínálatának csúcsát képviseli, akár ötször gyorsabb is lehet dedukciós feladatok alkalmával, ami nem kis előrelépés. Ezzel egy időben a GPU mellé négyszer több memória is kapcsolódik, ami szintén örömteli hír lehet a partnerek számára.
A B200-as GPU gyakorlatilag két chipletből áll, amelyek igencsak sok, darabonként 104 milliárd tranzisztorból állnak, és ezen a téren jelenleg a legnagyobbaknak számítanak. A B200-as GPU két chipletjét a TSMC legmodernebb és legnagyobb teljesítményű 4N osztályú gyártástechnológiájával gyártották le, ami nem más, mint a 4NP. Az összesen 208 milliárd tranzisztorból felépített GPU esetében a két chiplet között egy egyedi, rendkívül nagy adatátviteli sávszélességgel dolgozó összekötő teremt kapcsolatot, ami 10 TB/s-os adatátviteli sávszélességet biztosít. Ennek a hatalmas adatátviteli sávszélességnek köszönhetően kellően gyorsan, eléggé alacsony késleltetés mellett zajlik a kommunikáció a chipletek között, vagyis megvalósul a gyorsítótár-koherencia is, azaz olyan sebesség mellett érhetik el a GPU-k a másik memóriaterületeit, mintha az a sajátjuk lenne, közvetlen kapcsolattal.

A memória-alrendszert mindkét chipletnél egy-egy 4096-bites memória-adatsín alkotja, amihez 96 GB-nyi HBM3E típusú fedélzeti memória kapcsolódik, ez négy darab 24 GB-os memóriachip-szendvics formájában érhető el, így a teljes B200-as chip összesen 192 GB-nyi fedélzeti memóriát vethet be. A memória-sávszélességet szintén nem aprózták el, az ugyanis 8 TB/s-os értéket képvisel, azaz nem sokkal alacsonyabb, mint a chipletek közötti kapcsolatot biztosító egyedi összekötő. Természetesen NVLink támogatás is jelen van a kínálatban, amellyel a kiszolgálóhoz és egy másik B200-as chiphez kapcsolódhat a GPU, ennek sávszélessége 1,8 TB/s, ami szintén masszívnak nevezhető.

A fentieket lehet még fokozni, ugyanis a vállalat a GB200-as Superchippel is előrukkolt, ami már összesen két darab GB200-as GPU-t tartalmaz, így összesen négy darab chiplet áll rendelkezésre, amelyekhez összesen 384 GB-nyi fedélzeti memória kapcsolódik. Az összesen 416 milliárd tranzisztorból felépített GPU-k természetesen NVLink kapcsolaton keresztül kommunikálnak, valamint egy ARM alapú Grace Superchip is jelen van a fedélzeten, ami az előző generációs GH200-as Grace Hopper Superchip lehet, ugyanis a termékről nem zengett ódákat az Nvidia első embere, így nem valószínű, hogy új fejlesztésről van szó. A Grace-Hopper Superchip bevetése azért előnyösebb egy AMD EPYC vagy egy Xeon Scalable sorozatú x86-64-es szerverprocesszorhoz képest, mert az NVLink magasabb adatátviteli sávszélességű kapcsolatot biztosít az egyes komponensek között, valamint a speciális architektúra miatt a chip jobban is passzol az AI jellegű munkafolyamatokhoz is.
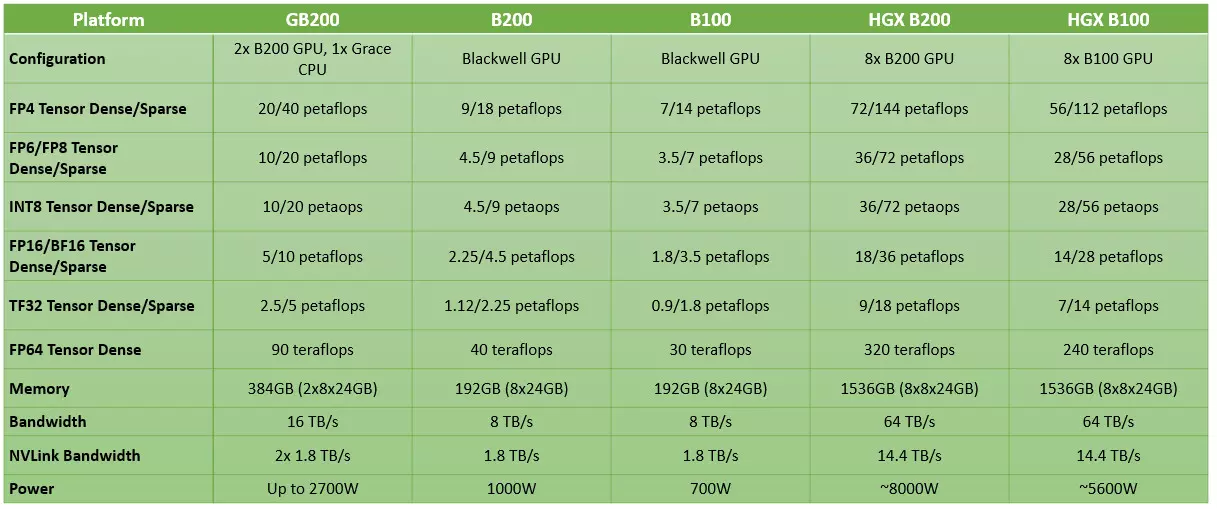
Itt el is érkeztük az egyes B200-as GPU-k és a GB200-as megoldás teljesítményét taglaló adatokhoz. Azt sajnos nem árulta el az Nvidia vezetője, hogy az egyes GPU-k pontosan hogyan épülnek fel, így az SM tömbök, a CUDA magok, a Tensor magok, illetve a gyorsítótárak pontos paraméterei sajnos nem ismertek, de az azért kiderült, mennyire hatalmas számítási teljesítményre számíthatunk majd. Az egyes B200-as chipek a hírek szerint 20 PFLOP/s-os számítási teljesítményt tudnak felmutatni a dedukciós munkafolyamatok alatt, ami 20 000 TFLOP/s-os értéket takar. A GB200-as modellnél ez az érték már 40 PFLOP/s lehet, ha az FP4 Tensor számítási teljesítményt vesszük alapul. Az FP64-es számítási teljesítmény szintén impresszív, az ugyanis 90 TFLOP/s-os értéket képvisel, azaz háromszor magasabb, mint amit a Hopper alapú GH200-as modellnél megszokhattunk.
Azt persze érdemes kiemelni, hogy a B200 esetében a 20 PFLOP/s-os teljesítmény, ami az FP4-es számformátummal értendő, gyorsulás szempontjából egy picit félrevezető. Ha az FP8-as szintet nézzük, amelynél az FP4-hez képest feleakkora teljesítmény érhető el, akkor a B200 és a H100 közötti teljesítménykülönbség már nem ötszörös, hanem csak két és félszeres (10 PFLOP/s vs. 4 PFLOP/s), így reális az összehasonlítás, hiszen így almát hasonlítunk az almához, nem FP4-es teljesítményt az FP8-ashoz.
Az Nvidia új fejlesztései várhatóan még idén elrajtolhatnak.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}