Az AMD az Advancing AI 2025 névre keresztelt rendezvény keretén belül több újdonságról is lerántotta a leplet, amelyekkel az AI szegmensbe, illetve a szerverek piacára készül a nem is oly távoli jövőben. Ebbe a körbe tartoznak az Instinct sorozatot erősíti MI350X és MI355X modellek, amelyek alapok terén igazából egyáltalán nem különböznek egymástól, de teljesítmény terén igen, méghozzá azért, mert míg előbbi léghűtéssel, addig utóbbi már folyadékhűtéssel dolgozik, így nagyobb teljesítmény elérésére képes.
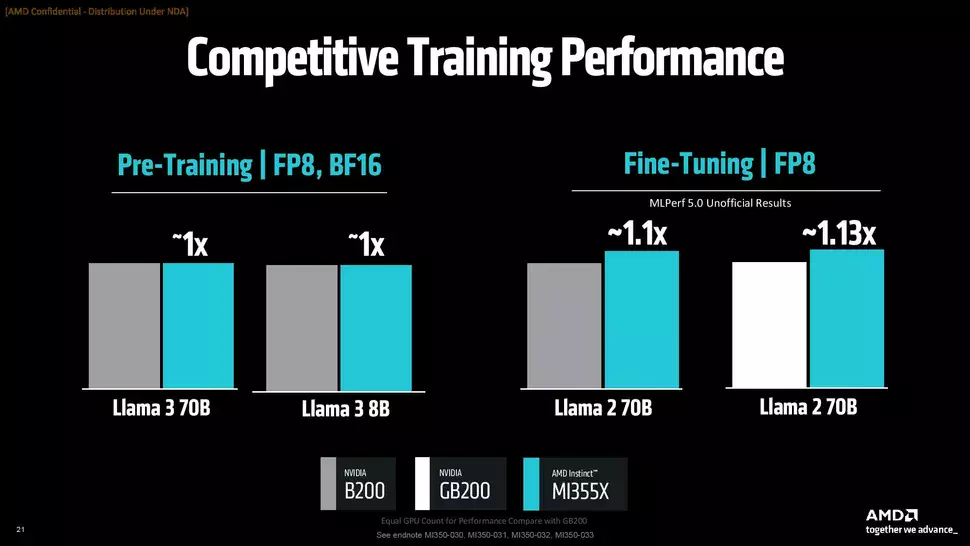
Az AMD szerint az új gyorsítók az MI300X sorozat tagjaihoz képest akár háromszor gyorsabbak lehetnek bizonyos feladatokban, de az Nvidia termékeit is képesek lenyomni: dedukciós feladatok terén 1,3-szoros, míg tréning feladatok esetén 1,13-szoros előnyt tudnak felmutatni riválisaikkal szemben.

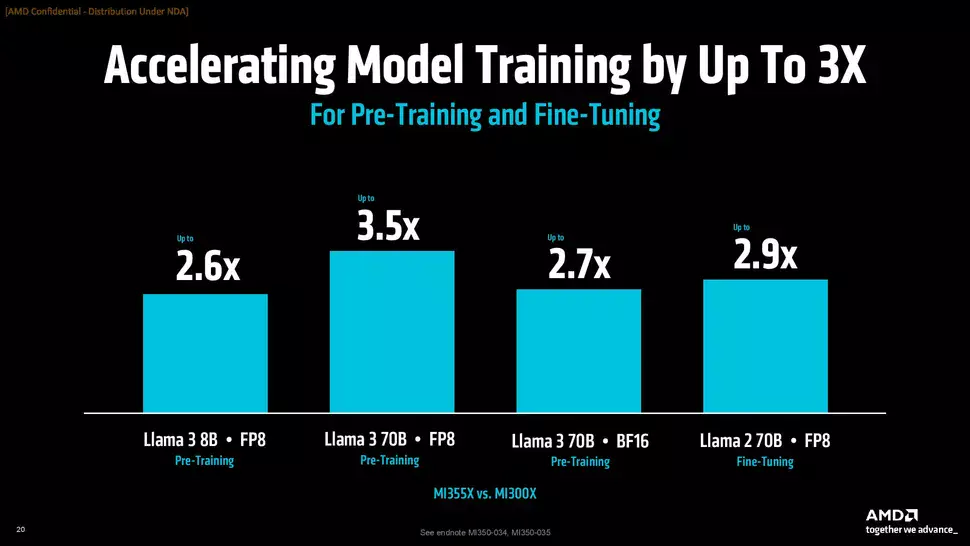
Az új AI és HPC piaci gyorsítók esetében fontos kiemelni, hogy AI számítási teljesítmény terén akár 4-szer is gyorsabbak lehetnek előző generációs társaiknál, míg dedukciós teljesítmény terén már akár 35-szörös is lehet a különbség a javukra, ami nagyrészt a CDNA 4 architektúra bevetésének köszönhető, valamint annak, hogy a Compute Chipletek esetében az eddiginél fejlettebb gyártástechnológiát vetnek be. Az MI300-as sorozat új tagjait már szállítják a partnerek számára, ezek a megoldások idén és a következő év folyamán meghatározó szerepet töltenek majd be a piacon, de jövőre már következő generációs társaik is bemutatkoznak, igaz, az egy másik történet.

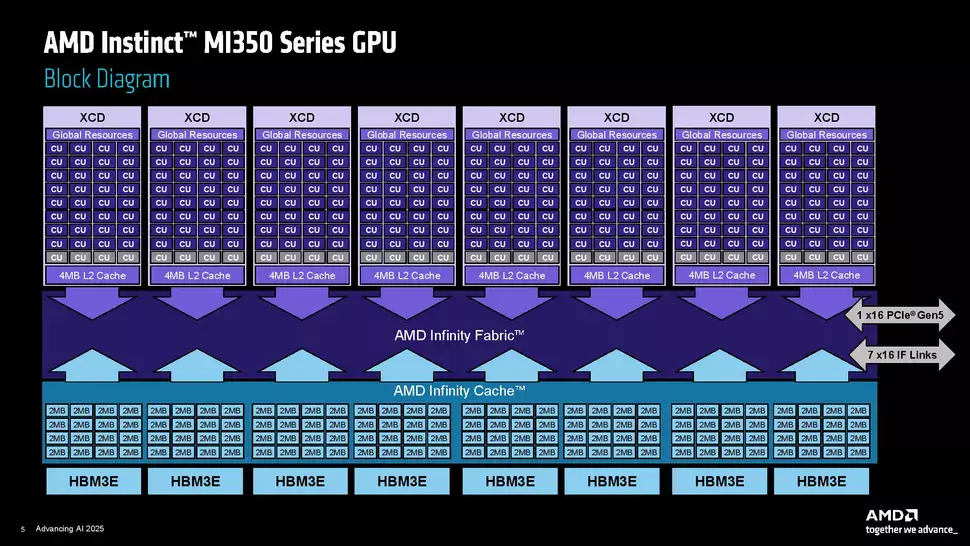
A friss AI és HPC piaci gyorsítóknál számos előrelépést láthatunk, de az alapvető felépítés nem igazán változott, továbbra is ötvözik a 3D és a 2.5D tokozási technológiákat, amelyek közül előbbi az XCD chipletek és az I/P lapkák integrációját segíti, míg utóbbi az IOD lapkák egymáshoz és a 12-Hi típusú HBM3E memóriachip-szendvicsekhez történő kapcsolódását teszi lehetővé. Fontos, hogy az MI350X sorozat tagjaiból nem készül processzormagokat is tartalmazó APU verzió, itt csak és kizárólag GPU alapú gyorsítók közül lehet majd választani, amelyek mellé EPYC szerverprocesszorok kerülnek.
GPU fronton összesen nyolc darab XCD chiplettel van dolgunk, amelyek egyenként 32 CU tömbbel rendelkeznek, vagyis összesen 256 CU tömböt számlál az új fejlesztés. Érdekesség, hogy minden egyes XCD tartalmaz még négy darab tartalék CU tömböt is, amelyek azért kellenek, hogy a lapkák kihozatali aránya jobb lehessen, ezeket igény esetén tudják engedélyezni vagy tiltani, így könnyebben összejön a 32 aktív CU tömb. Maguk az XCD lapkák ebben az esetben már nem 5 nm-es, hanem 3 nm-es csíkszélességgel készülnek a TSMC műhelyében, egészen pontosan az N3P node használata mellett. Egy-egy ilyen chip összesen 185 milliárd tranzisztorból épül fel, ami jelentős növekedés az előző generációnál alkalmazott 153 milliárd tranzisztorból álló büdzséhez képest.

Maga az I/O lapka továbbra is 6 nm-es csíkszélességgel készül, viszont változott a chipen belüli elrendezés, ugyanis itt már nem négy, hanem csak két ilyen lapka áll rendelkezésre annak esetében, hogy egyszerűbb legyen a dizájn. Ez a változtatás az AMD szerint segített abban is, hogy megduplázzák az Infinity Fabric összekötő sávszélességét, így az már 5,5 TB/s-os sávszélesség biztosítására is képes lehet, miközben sikerült csökkenteni a fogyasztást a busz órajelének és üzemi feszültségének csökkentésével.
Ez összességében segít abban, hogy a magokon kívüli (UnCore) részleg fogyasztása csökkenjen, a felszabadult büdzsét pedig a Compute Chipletek használhatják fel, amelyek így nagyobb teljesítmény mellett dolgozhatnak. A rendszer természetesen Infinity Cache típusú gyorsítótárat is kapott, ami a HBM memóriachip-szendvicsek előtt foglal helyet és egyenként 32 MB-nyi kapacitással bír.

Az MI350X sorozat tagjai mindannyian OAM formátumban érkeznek, valamint támogatják az FP4-es és az FP6-os formátumokat is. Mindkét megoldás 288 GB-nyi HBM3E memóriával érkezik és maximum 8 TB/s-os memória-sávszélességet oszthat be, viszont TBP terén lesz különbség köztük: a folyadékhűtéses MI355X esetében 1400 W-os TBP keret lesz érvényben, ami az MI300X 750 W-jához és az MI325X 1000 W-jához képest jelentős növekmény. Formátum terén nem lesz különbség a korábbi modellekhez képest, ami gyorsítja a bevethetőségüket, a folyadékhűtéses verziót pedig sűrűbben lehet majd pakolni a racken belül, ami segít a teljes birtoklási költség (TCO) alacsonyabban tartásában.

A rendszer PCI Express 5.0 x16-os csatolófelületet használ és egyetlen logikai eszközként jelenik meg a kiszolgáló számára. A GPU a többi chippel Infinity Fabric linkeken keresztül kommunikál, amelyek összesen 1075 GB/s-os adatátviteli sávszélesség elérésér képesek. Egy-egy node-on belül maximum 8 gyorsító kommunikálhat egymással a kétirányú Infinity Fabric linkeken keresztül, ami 153,6 GB/s-os adatátviteli sávszélességet kínál, és minden node tartalmaz egy 5. generációs AMD EPYC szerverprocesszort is, ami a Turin sorozatot erősíti. A rendszerek sokféle hálózatot támogatnak, de elsősorban a vállalat által kifejlesztett Pollara vezérlőket részesítik előnyben, amelyek Ultra Ethernet kompatibilisek, míg a felskálázásért UAL (Ultra Accelerator Link) felel.

A folyadékhűtéses rackekben maximum 128 darab MI355X gyorsító fér el, amelyek összesen 36 TB-nyi HBM3E memóriát foghatnak munkára – ez annak köszönhető, hogy az ütőképes hűtés miatt sűrűbben helyezhetőek el a rendszerben a gyorsítók. A léghűtéses verzióknál ehhez képest csak maximum 64 GPU bevetésére van mód, amelyek így csak 18 TB-nyi HBM3 memóriát használhatnak, és ezek nagyobb rackekben foglalnak helyet annak érdekében, hogy a léghűtés hatékonyan működhessen.

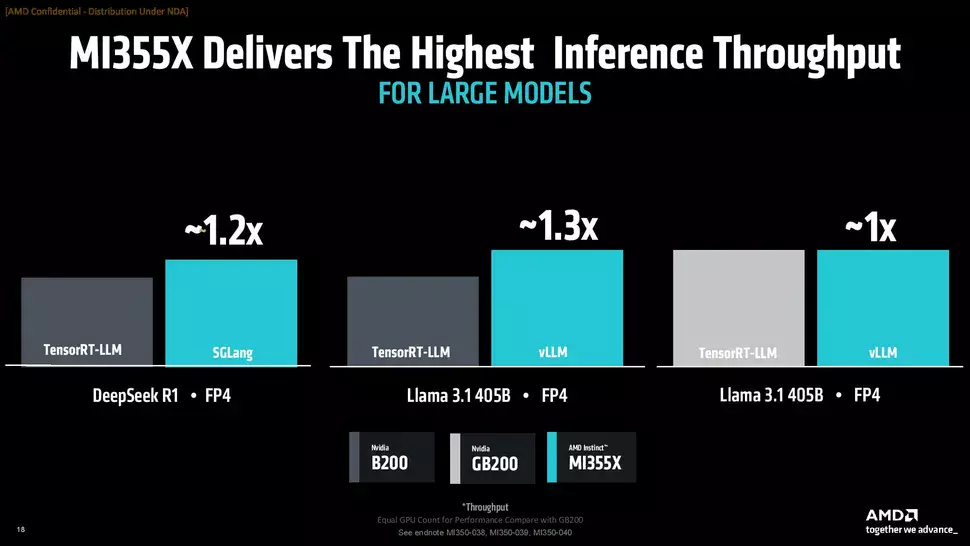
Az AMD néhány teszteredményt is mutatott azzal kapcsolatban, mire képes az MI355X a rivális megoldásokkal szemben. A négy darab MI355X gyorsítóból álló rendszer az ugyancsak négy GB200-as gyorsítót használó Nvidia DGX rackhez képest Llama 3.1 405B alatt 1,3-szor gyorsabb, míg nyolc darab MI355X gyorsító a nyolc darab B200-as gyorsítóval ellátott HGX rendszerhez képest 1,2-szer gyorsabb DeepSeek R1 alatt. Utóbbi rendszer a Llama 3.1 405B tesztben azonos teljesítményt kínál, mint riválisa. Tréning terén szintén versenyképesnek bizonyul az MI355X a B200-hoz és a GB200-hoz képest, ott ugyanis a Llama modellek alatt vagy azonos teljesítményt kínál vagy maximum 1,13x gyorsabb náluk.
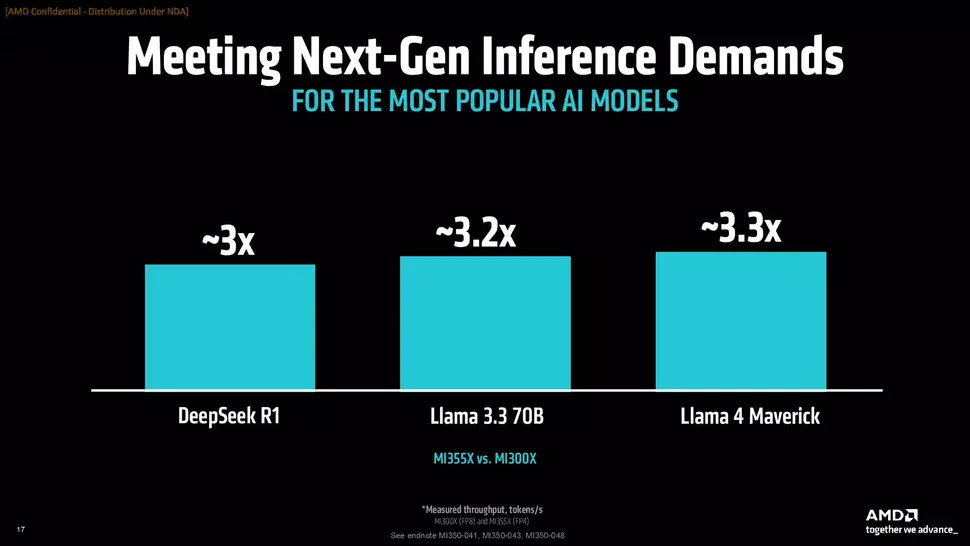
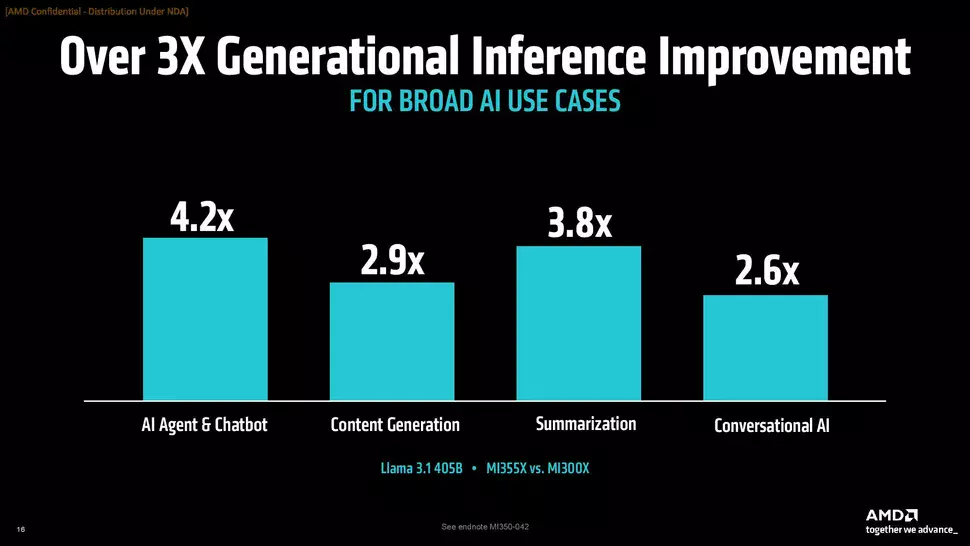
Az AMD szerint az MI355X az MI300X-hez képest AI Agent és Chatbot munkafolyamatok esetén akár 4,2x nagyobb teljesítményt tud felmutatni, míg egyéb feladatok, például összegzés és tartalomgenerálás esetén 2,6-szorostól egészen 3,8-szoros mértéki terjed az előnye. A generációk között gyorsulást szemlélteti továbbá az is, hogy DeepSeek R1 alatt háromszoros, míg Llama 4 Maverick alatt 3,3-szoros gyorsulást tud felmutatni az újdonság.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}