A Google és a Microsoft feszült egymásnak az utóbbi időben leginkább a mesterséges intelligenciát illető fejlesztések tekintetében, de azért a Meta is dolgozik ezen a fronton, és most ezt elég határozottan jelezte. ImageBind néven egy olyan megoldásról beszélt, amihez hasonló sincs még jelenleg.
A Meta nyílt forráskódú AI modellként vezette fel az ImageBindet, ami képes lesz szimultán kezelni több forrásból származó adatokat, és szenzoroktól származó információkat feldolgozására is képes lesz. A multiszenzoros területen már vannak érdekes megoldások, de a Meta által megálmodott komplex AI modell mindenképpen rendkívül izgalmasnak ígérkezik.
Akár hat különböző adatformával lesz képes egyidejűleg dolgozni az ImageBind.
Egyelőre csak egy kutatási projektről van szó, tehát nem érhető el fogyasztóknak, arról egyáltalán nincs szó, hogy kész termékben felhasználható lenne, valószínűleg nem is fog működni még egy darabig úgy, ahogy azt a Meta vízionálja. Azonban mindenképpen érdekes lehet abból a szempontból, hogy megmutathatja, merre tart a generatív mesterséges intelligencia. A jövőben az MI talán képes lesz már arra, hogy egy valóban immerzív, minden részletre kiterjedő virtuális környezetet létrehozzon.
A koncepció lényege az, hogy számos különböző adatformát kössön össze a Meta egy csokorba, és ezzel létrehozzon egy multidimenzionális indexet, ami nagyon futurisztikusan hangzik, de lényegében egy „beágyazott térről” van szó, amihez az MI generál mindent azok alapján, amit tanítottak neki.
A chatbotok a szöveges parancsokra válaszolva alkotnak szövegeket, a Stable Diffusion pedig szintén szöveges parancsra hoz létre képet, de a GPT-4 például már képes arra, hogy szöveget és képet egyszerre értelmezzen. Az ImageBindnél pedig már hat különböző adatformával tudna dolgozni a rendszer. De mi is lenne ez a hatféle adat? Nos, a Meta elmondása alapján tudná kezelni a szöveget, a vizuális dolgokat, a hangokat, a mélységinformációt, a hőmérsékletet, valamint a mozgási adatokat is.
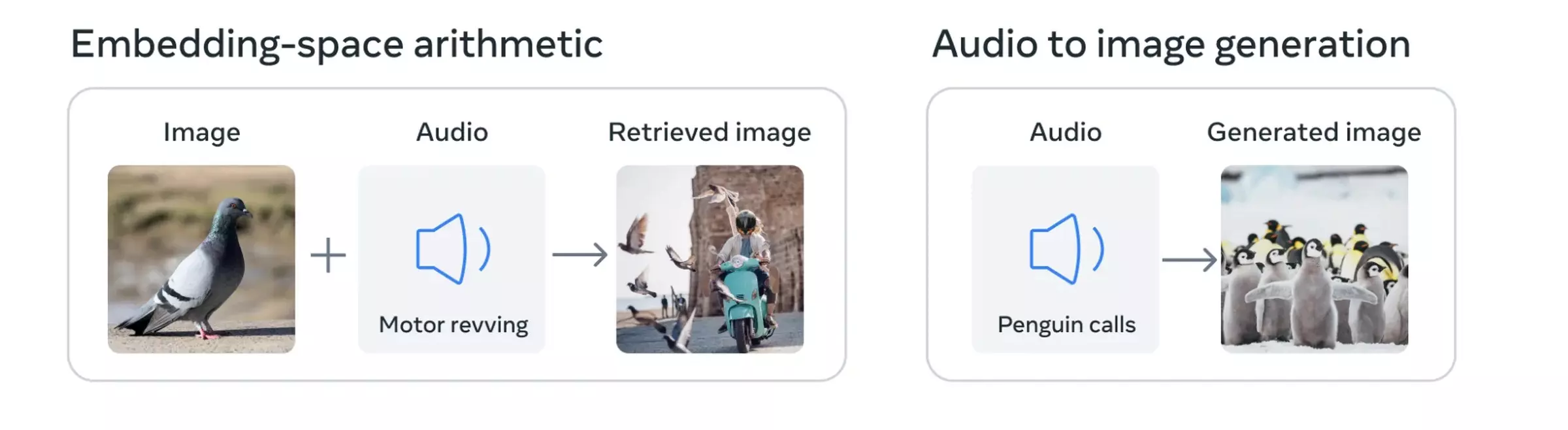
Meg tudná oldani, hogy egy pingvin hangot bejátszva létrehozna egy pingvinekkel teli képet, lehetne neki adni egy galambfotót, és mellé egy olyan hangot, amin sok galambot lehet hallani emberi zaj mellett, és létrehozna egy képet, melyen az utcán galambok között közlekednek emberek. De meg tudná oldani azt is, hogy egy virtuális teret hozna létre 3D elemekkel, a háttérben például zenével egyszerű szöveges utasításokat alapul véve. A lehetőségek itt már nagyon széles határok között mozognának.
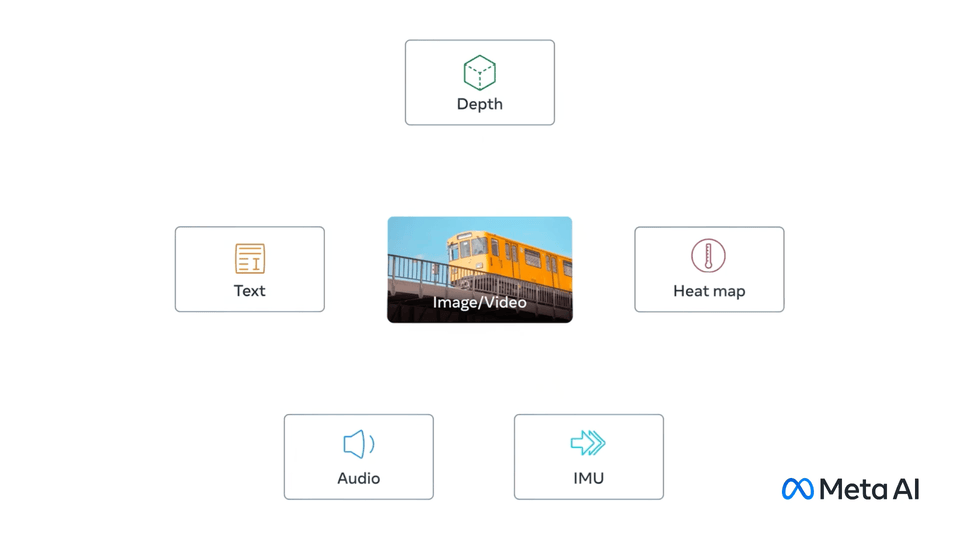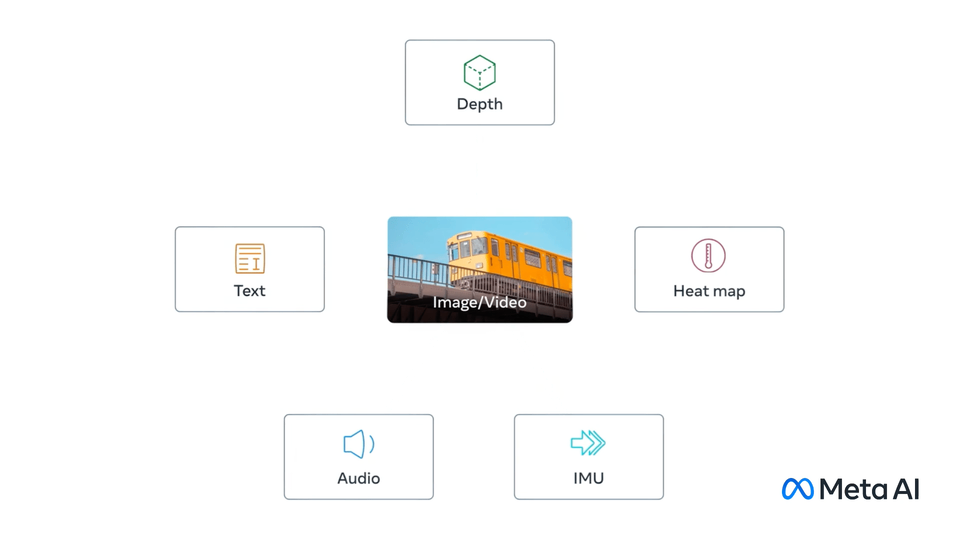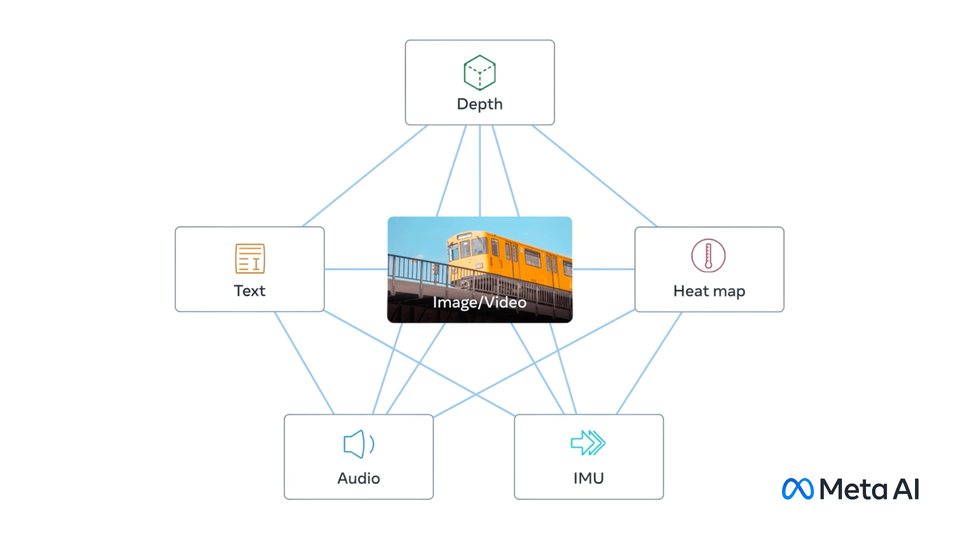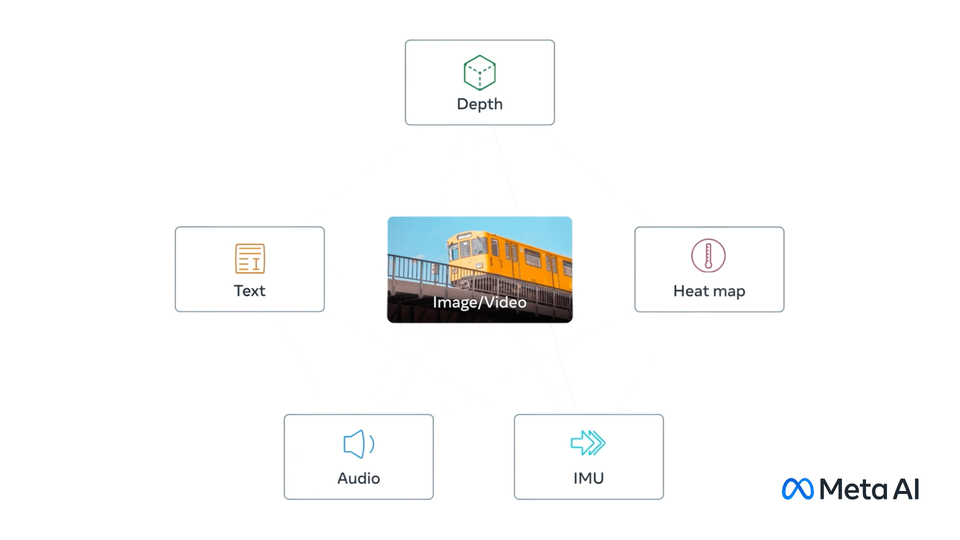
A Meta a virtuális és a kiterjesztett valóság fejlesztéseket nagyon komolyan veszi, még a megszorítások mellett is nagyon sokat költ ezen a fronton. A metaverzumba is rengeteg pénzt tol bele, és az ImageBing is egy olyan fejlesztés, amivel például ezt a fronton ki lehetne bővíteni és vonzóbbá lehetne tenni. A jövőben talán megoldható lesz majd az, hogy utasításokra képes lesz a generatív MI létrehozni egy olyan virtuális környezetet, ahol a felhasználó teljesen úgy érezheti, mintha ténylegesen egy olyan helyen lenne, amit elképzelt. Olyanok lennének a hangok, a környezet és minden más is, illetve tudna igazodni a hely a valós környezeti hangokhoz, ha éppen arra van szükség.
Még távolabbi jövőbe is tekintett a Meta az újdonság kapcsán, és kitért arra, hogy egyszer talán még az érintés érzését, a szagokat, vagy akár az fMRI agyalapi jeleit is tudja kezelni a generatív MI. Felismerhetné például a kiváltott érzelmeket, a virtuális térre adott reakciót, és annak megfelelően tudná létrehozni a képzeletbeli tere. Kíváncsian várjuk, hogy mi lesz ennek a nyílt kutatási projektnek az eredménye, nagyra törő elképzelésekből nincs hiány, az biztos.
