
Májusban jelentette be az OpenAI a GPT-4o modellt, ami a GPT-4 alapjára épül ugyan, de több szempontból is bőven túlmutat azon. Minél újabb egy modell, általában annál jobb, hiszen ezeket folyamatosan javítgatják a felhasználók, viszont azért ez a történet nem ennyire egyszerű. Most a GPT-4o kapcsán az OpenAI elindít egy olyan lehetőséget, ami eddig csak a régebbi modellekkel volt elérhető.
A továbbiakban már lehet finomhangolni a legújabb nagy nyelvi modellt is. Ennek köszönhetően sok esetben lehet még tovább javítani a szolgáltatás működését, pontosságát.
Az OpenAI fontos újítása volt korábban, hogy lehetővé tette a fejlesztők számára, hogy a GPT modelleket úgy is alkalmazhassák saját céljaik megvalósításához, hogy teljesen egyedi adatcsomagokat használnak fel a tréningezéshez. Ennek köszönhetően lényegesen kisebb lesz annak az esélye, hogy hallucinálni kezd a mesterséges intelligencia. A hibás válaszok komoly gondokat tudnak okozni, kiváltképpen olyankor, mikor a pontosság kulcsfontosságú lenne. Persze az MI válaszát lehet ellenőrizni, de ez bizonyos esetekben már túl körülményes.

A partnerek az új lehetőségnek hála még többet tudnak majd kihozni a GPT-4o modellből, és olyan helyen is munkába állítható már ez, ahol eddig a finomhangolási lehetőség hiánya miatt nem volt alkalmazható. Nagyobb szabadságot biztosít a modell működésének beállításában is az OpenAI, így lehet majd még jobban egyedi igényekhez igazítani. Főleg technikai feladatokban jöhet majd az rendkívül jól, hogy lehet a GPT-4o számára adati feltanítási alapanyagot biztosítani. A kisebb adatcsomagok révén akár szignifikánsan is javíthatók a generatív MI-től érkező válaszok.
Az OpenAI folyamatosan dolgozik a nyelvi modelljein, és több különböző szempontból igyekszik ezeket rendszeresen javítani. A finomhangolási lehetőség biztosításával a fejlesztők is lehetőséget kapnak arra, hogy a saját céljaikra még tovább csiszolhassák az LLM rendszer működését.
A GPT-4o egyik nagy újítása a GPT-4-hez képest az, hogy lényegesen olcsóbban lehet használni, de a tréningezése ettől függetlenül azért még eléggé költséges lesz. Nemcsak, hogy magas árat kell fizetni az adatok feldolgozásáért, de ilyenkor azért mégis csak kiugróan nagy mennyiségű adatot kell bevinni, ha en is olyan mennyiséget, mint az eredeti betanítási folyamat során. 25 dollárba kerül egy millió token feldolgozása a tréningezés alatt, ha valaki a finomhangolás mellett dönt. Ezt követően a normál használatban már csak 3,75 dollárba kerül 1 millió token bevitele, a kimenetben viszont 15 dollárt kell fizetni ugyancsak 1 millió token után.
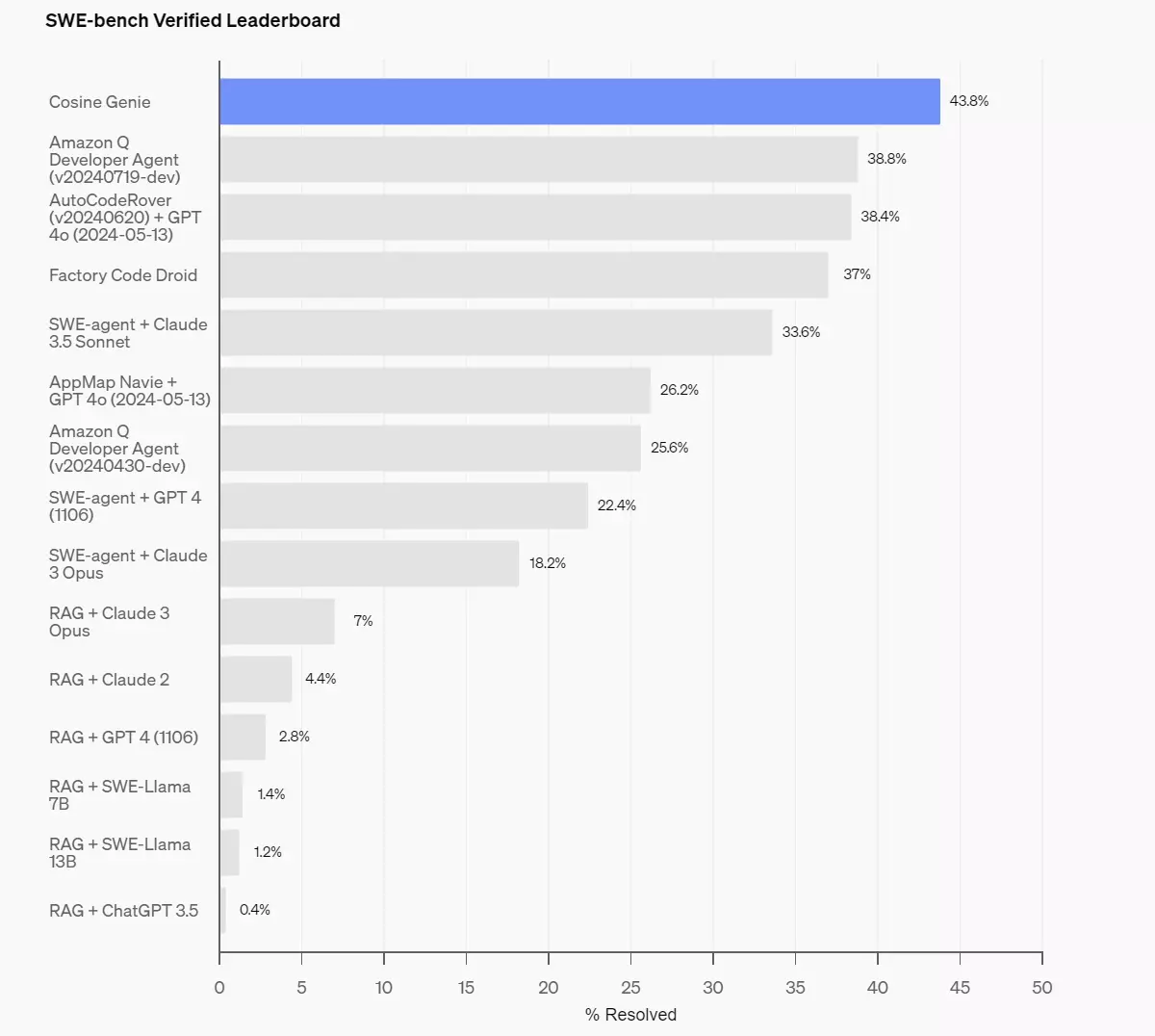
A vállalat több példával is szemléltette, hogy mennyit érhet a finomhangolás a modellek működésében. Néhány kiemelt partnernek már előzetes lehetőséget biztosított erre, hogy bemutathassa azt, mire képes egy „fókuszált” GPT-4o. Mondanunk sem kell, hogy ezekben a tesztekben kiemelkedő eredményeket produkált az OpenAI szóban forgó nyelvi modellje a különböző fejlesztések mögött.
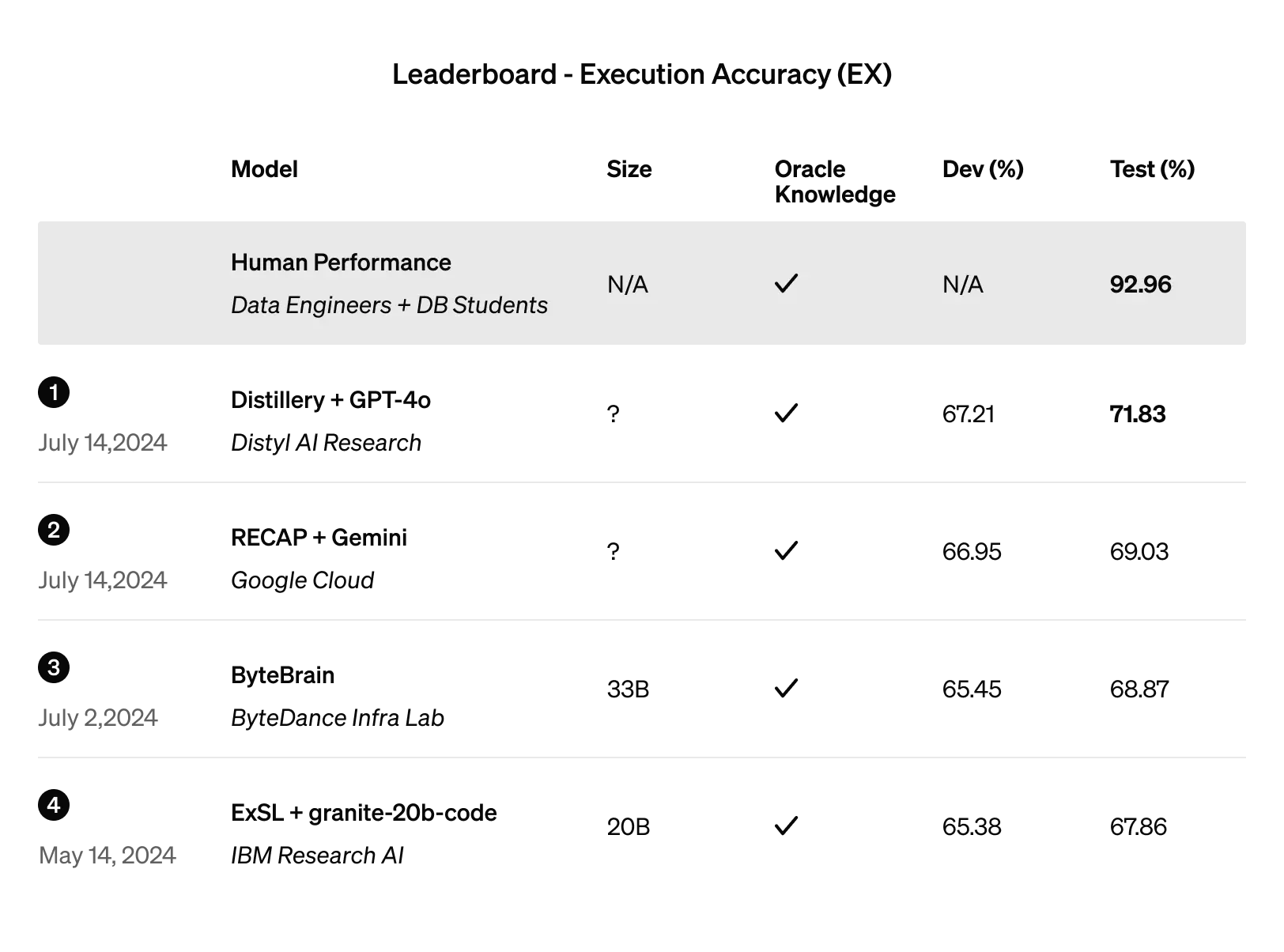
Azt is elmondta a cég, hogy a finomhangolt modell keretében nem kell attól tartani, hogy az adatok rossz kezekbe kerülnek. A vállalati információknál már eddig is igyekezett kiemelt adatvédelemről gondoskodni az OpenAI, és itt sem lesz ez másként. Az egyedi tanításra használt adatokat senkivel nem fogják megosztani, és nem használják fel az általános modell tráningezésére.
Emellett pedig lesz egy plusz biztonsági réteg, ami azt fogja felügyelni, hogy a modellt továbbra se tudják visszaélésekre használni. Ez ugyanis éppen olyan fontos, mint a megfelelő adatvédelem garantálása. Az OpenAI szerződési feltételeit mindenkinek, minden körülmények között be kell tartania. A vállalat kiemelte, hogy izgalommal telve várják, mit tudnak majd kihozni a partnereik a finomhangolt GPT-4o-ból.
