
Az xAI egyértelműen ott van a nyelvi modellek és a generatív mesterséges intelligencia eszközök fejlesztőinek élmezőnyében, és ezt a pozícióját most tovább erősíti a Grok 4.1 modellel. A cég szerint szignifikáns fejlődést sikerült összehozni a valós felhasználási közegben.
A Grok 4.1 az egyik legjobb képességű nyelvi modell lett, gyorsabb az eddigieknél és kevesebbet hallucinál. A tesztelők visszajelzései szerint az esetek többségében (64,8 százalék) az új eszköz adja a legjobb válaszokat. Remélhetőleg nincsenek szélsőséges hajlamai sem a Grok új verziójának, miközben továbbra is komolyabb tartalmi szűrő nélkül használható.
„A 4.1-es modellünk kivételes képességekkel bír a kreatív, emocionális, és kollaboratív interakciókban” – jelentette ki az xAI. „Érzékenyebb a szándékok finom árnyalataira, lebilincselőbb a beszélgetés vele, és koherensebb a személyisége, miközben teljes mértékben megőrizte elődeinek éles elméjét és megbízhatóságát.”
Az xAI kutatói a korábbi tanítási technikát felhasználva, optimalizálva érték el a kívánt fejlődést. A cég november elejétől a felhasználók egy részének már a Grok 4.1-et biztosította, és a visszajelzések egyértelműen azt mutatták, hogy az új modell válaszait jobbnak ítélik a tesztelők. Két verzióban állt munkába a modell, a Grok 4.1 az alap, és van egy érvelésre kihegyezett Grok 4.1 Thinking opció, ami a nehezebb, összetettebb feladatok megoldására szolgál.
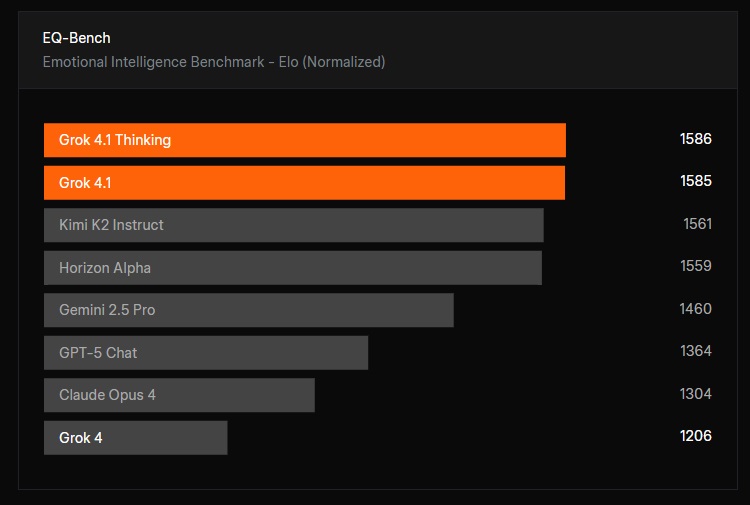
A fejlesztéseknek köszönhetően a Grok érzelmi intelligenciája új szintre lépett. Ezt méri az EQ-Bench, és a Grok 4 ebben már csak 1206 pontot ért el korábban, a Grok 4.1 viszont már 1585-1586 pontot. Jobb lett a modell a kreatív szövegszerkesztési feladatokban is, ezt a cég a Creative Writing v3 teszttel mérte fel.
A kutatások során az egyik legfontosabb cél az volt, hogy a hallucinációra való hajlamot csökkentsék, és a cég saját mérései szerint a Grok 4 12,1%-os hallucinációs arányát sikerült 4,22%-ra faragni, ami kiválóan hangzik. Azt is megtudtuk, hogy 2,97 százalékos FActScore-t ért el az új modell, ami ugyancsak hatalmas fejlődés a korábbi 9,89%-hoz mérten. A FActScore egy olyan megmérettetés, ami a válaszok tényszerűségét vizsgálja, és igyekszik „hazugságra” bírni a modelleket.

A Grok 4.1 Thinking modell az LMArena ranglistáján a második helyet foglalta el, és csak azért csúszott le a trónról, mert a Google által ugyancsak frissen bemutatott Gemini 3 Pro egy hajszállal még jobban teljesített. 1501 pontot hozott össze az új Gemini, ami ellen 1484 pontot volt képes felmutatni a Grok 4.1 legjobb variánsa.
A Grok 4.1 azonnal munkába áll a Grok chatbot mögött, ezáltal a felhasználók már érzékelhetik a változást a generatív MI válaszaiban. A weben és mindkét nagy mobilos platformon egyaránt a friss Grok lépett az előtérbe, nem részesíti egyik platformot sem hátrányban az xAI, ami örömteli.
„Auto” módban üzemel a rendszer, ami azt jelenti, hogy magától képes kiválasztani a chatbot, hogy éppen melyik modellre van szükség a leggyorsabb/legjobb válaszokért. A nehezebb kérdéseket a Grok 4.1 Thinking fogja elemezni, így az eredményre többet kell majd várni, az egyszerű beszélgetéseknél viszont a Grok 4.1 fog gyors válaszokkal szolgálni.
