Több évtizednyi tanulás vs. az emberiség vizuális kincsei
Több, mint 10 éve rajzolok. Nagyon - nagyon későn kezdtem el a dolgot, a pálcikaember szint alatti tudással vágtam bele az önfejlesztésbe. Előtte ugyanis azt a döntést hoztam, hogy megírok egy könyvet, ám azért, hogy nincstelenként is spórolni tudjak, elhatároztam, hogy magam rajzolom meg a borítót. Igen ám, de nagyon hamar rájöttem, hogy ehhez nem elég megnézni egy-két YouTube videót, sajnos ennél többről van szó akkor, ha az ember komoly eredményt szeretne elérni. A könyv végül a fiókban végezte, ám a rajzolás szeretete megmaradt, persze továbbra is tehetségtelennek érzem magam.
Természetesen fejlődtem azóta, ismét saját könyvhöz készítem majd el a borítómat, annyi változás viszont történt, hogy ha ma kezdenék bele a dologba, akkor nem kellene évtizedek alatt kitanulnom a szakmát egyetlen könyvborító miatt, hanem generáltatnék magamnak egyet, például így:

Kész a képem.
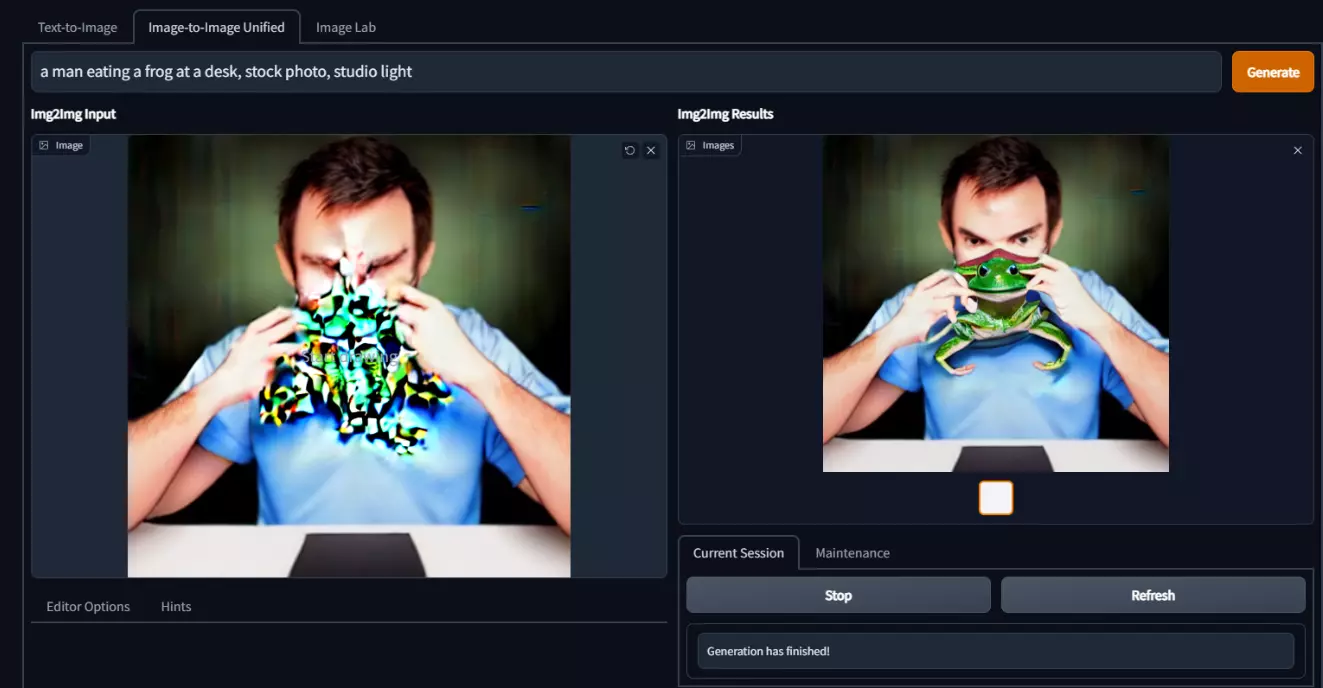
Ez egész jó eredményt hozott, de mi van, ha csak egy kicsit változtatnék rajta, a stílust, a ruházatot vagy az arckifejezést? Nem probléma, készítek belőle egy másik változatot, ezúttal a korábban elkészült képet alapul véve (tehát nem újat generálva), kiegészítve az információkat arról, hogy legyen kék ruha rajta egy nyaklánccal.

Egy kicsit nagyobb felbontásban kéne.

Bár egyértelműen nem tökéletes az eredmény, az összhatás már most sokkal izgalmasabb, mint amit a legtöbb ember több éves gyakorlás után el tud készíteni. Egy-két photoshop mókolással ez a kép hamar tökéletessé válhat és akár könyvborítónak is alkalmazható eredmény születhet (a galériában több változat is megtekinthető, amit a cikkhez készítettem).
A kérdés az, hogyan jutottunk el idáig, és miért nagy dobás az, hogy ezeket a fenti képeket egy teljesen ingyenes, nyílt forráskódú mesterséges intelligenciával készítettem a saját számítógépemen?
A grafikus művészek elengedhetetlenek a szórakoztatóiparban. Ők azok, akik szinte mindenért felelnek, ami a látvánnyal kapcsolatos. A cipőd, az autód, a telefonod, a sorozataid, a filmjeid, a videojátékaid, a reklámok az utcán, a weboldalak, a takaród, de még a fogkeféd is; bármi, amit a neten találsz vagy megvehető a boltban, néhány kivételtől eltekintve átment egy vagy több művész kezei között, hogy hozzád már egy élvezhető produktum kerüljön. Kétségünk ne legyen, egy mérnök meg tudná építeni a világ legjobb tulajdonságaival rendelkező autóját, ám művészek nélkül az olyan ronda és nehezen használható lenne, hogy valószínűleg első ránézésre bárki elszállíttatná, mint hulladék.
A művészek azok, akik az adott keretből, ami a rendelkezésükre áll, a lehető legjobb, legszebb és leghasználhatóbb dolgot hozzák ki, így esztétikus, használható eredményt kapunk. A művészeket az informatika és filmipar már régen felfedezte magának, egy-egy videojáték elkészítésénél akár tízszer vagy százszor több művész dolgozik, mint programozó, filmek és sorozatok pedig művészek nélkül nem is léteznének. Hiába van több milliós kamera valaki kezében, ha nincs megfelelő tudású művész mögötte, akkor kevesebbet ér, mint egy 10 éves telefon béna felvevője.
A művészet tehát piacosítva van, a legtöbb ilyen munka régóta nem arról szól, hogy a művész igényeit kielégítse, hanem arról, hogy a fogyasztóra hasson.
A tanulás elve, a tudás monopóliuma
A művészek a fogyasztói társadalom nagyon fontos mozgatórugói, hatalmas jelentőséggel bírnak a modern világban, akkor is, ha erről a fogyasztó nem tud vagy nem is sejti. Ám mi van akkor, ha ezen emberek nagy része lecserélhetővé válik a gépek által?
Az elmúlt pár hónapban a művészi és informatikai körökben egyre nagyobb zajt keltett az, hogy érkeznek az AI, avagy a mesterséges intelligencia alapú képgenerátorok. Ezek az eszközök - ahogy a fenti példám is mutatja - bizonyos, emberi nyelven megírt (pl. angolul) utasítások alapján képesek olyan képet generálni nekünk, amire mi megkérjük őket. Ehhez különböző technikákat használnak, ám közös pont bennük, hogy ezeket meg kell tanítani arra, hogy miként kell értelmezni az adott dolgokat.
Az emberi képzelet csak olyan dolgokon alapulhat, amit valaha, bármilyen formában az ember megtapasztalt vagy látott már. Ez egy alapvető korlát az emberi elmében, csak és kizárólag a megtapasztalt valóságon alapulhat a képzeletünk is, ami ezt összeturmixolva alkot valami újat, valami soha nem látott dolgot.

Ugyanez a korlát igaz a számítógépekre is. Ha a számítógép nem látott valamit korábban, nem tudja elképzelni, hogy milyen lehet az. A deep learning megoldásoknak hála viszont meg lehet tanítani a gépet arra, hogy mi micsoda a világunkban, minek mi a jelentése, és akár még arra is megtaníthatjuk, hogy mi számít szépnek.
Egy képgenerátor mesterséges intelligenciánál ezt pedig úgy lehet elérni, ha hihetetlen mennyiségű képet, és vele együtt rengeteg információt táplálunk bele. Megmondjuk, hogy mi az, amit jól értett, mi az, amit rosszul, mi az, ami látható a képen és hasonlók. Bizonyos szempontból nem különbözik attól, mint amikor egy szülő magyarázza a gyermekének, hogy amit lát a világban, az micsoda és mire jó, annyi különbséggel, hogy a valódi, létező képek, videók mellett ez a kommunikáció általában kód formájában, a gép nyelvén történik. Azért, hogy a gép „megértse” a rengeteg kapott képet, úgynevezett DNN tanítóhálón alapuló modell leírást is kap.
Létezik igazi AI?
Éppen ezért egy AI írása, illetve ezek tanítása nem feltétlenül elérhető, és nem is érthető a halandók számára, így az AI technológia nagyon okos és profi kutatók kezében van jelenleg. Ilyen mérnökök általában a Google-nél, Microsoftnál, Nvidiánál stb. dolgoznak és űrből is jól látható összegeket keresnek.
A tréningfolyamatnak van más hátulütője is: rendkívül erőforrás és idő igényes. A fent említett vállalatok hatalmas gépparkokkal oktatják ezeket a gépeket, egy 512x512 felbontású képre optimalizált AI tanítása ugyanis hatalmas teljesítményű szerverek nélkül nem lehetséges.
Igen, jól olvastad, ilyen alacsony felbontású képek tanításához ipari teljesítményű videokártyák kellenek, és még hatalmas gépparkokkal is hónapokig tart a tanításuk. Otthon, legyen bármilyen drága géped is, szinte betaníthatatlanok ezek a rendszerek. Meg lehet oldani, de annak az időtartama évekig fog tartani úgy, hogy mást sem számol a számítógéped, csak 100% teljesítményen ezt. Ebből következően hatalmas energiaéhségről beszélünk, ami rendesen megpörgeti a villanyórát, vagyis egyáltalán nem olcsó egy üzemkész modell létrehozása.
Gosztolya Gábor szerint az 512-es felbontás a gépigény miatt már nagynak számít. A VGG DNN-struktúra, ami egy képen látható dolgok felismerésre épül, például csak 224x224-es felbontást kezel.
A training idejét le lehet csökkenteni emberi időre, ha már van egy előre betanított modellünk, amit nem a nulláról kell betanítani, csak kicsit ki akarjuk egészíteni a tudását. Ilyenkor egy-egy képet hozzátanítani csak pár óra lesz. Például jön egy új telefon egyedi külalakkal, ha van róla pár fotónk, pár óra alatt már fog tudni a gép ilyet rajzolni, ha a tréning után megkérjük rá. Ez még otthoni keretek között is megoldható, ha ismétlem, van egy (több) brutálisan erős videokártyád, hatalmas mennyiségű RAM-mal.

A számítási igényei miatt a betanítás kevesek kiváltsága maradt. A fent említett nagy cégeken, illetve kormányokon kívül nem sokan engedhették meg maguknak, hogy így okosítsanak fel egy AI-t a kezdetektől. Mivel egy ilyen oktatás rengeteg pénz és idő, ezért a betanított modelleket kincsként őrzik a vállalatok. Nem hozzáférhetetlen kincsként, de csak messziről piszkálhatjuk API hozzáféréseken keresztül, viszont oda nem adják nekünk.
Az Nvidia például a Canvas nevű AI szoftverrel egy jó ideje képes egyszerű színekből legendás tájképeket készíteni. A lenti képet természetesen én rajzoltam. Mármint a bal oldalit, a jobb oldalit az Nvidia videokártyám rajzolta valós időben, és át is tudja alakítani több más stílusba egyetlen kattintással.
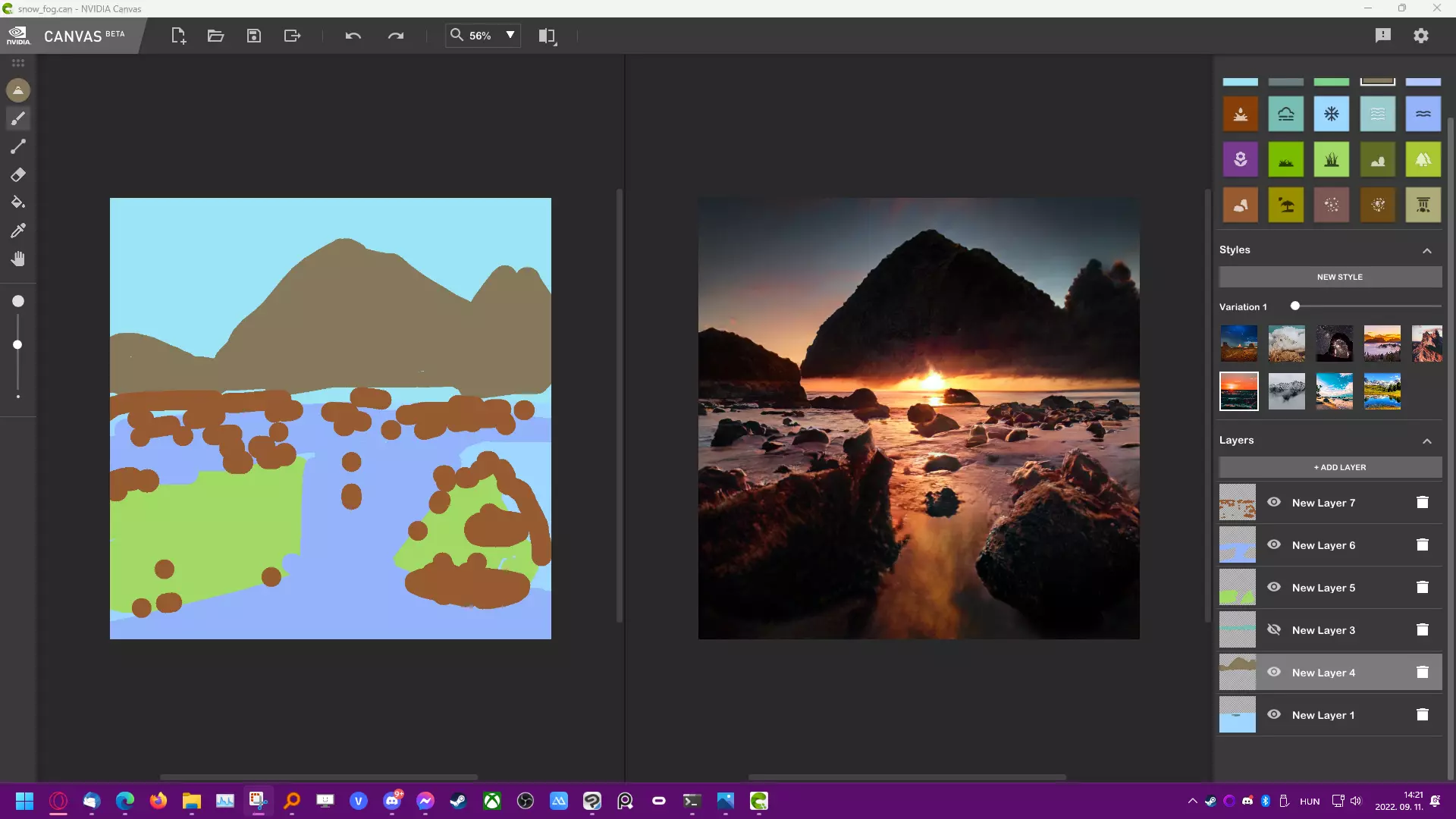
Bár a program ingyenesnek tűnik, valójában csak RTX videokártyákon működik, azoknak az AI magját használja, márpedig ezeket a GPU-kat meg kell vennünk. Vagyis mégse teljesen ingyenes a program, a videokártya vásárlása mellett közvetve ezt a szoftvert is kifizettük. A Google is több AI eszközt adott már az emberek kezébe. Most mivel a képalkotók mellett maradunk, ezért például a fordító, felismerő és kereső AI-t csak említés szintjén hozom fel, de ők is rendelkeznek AI alapú képalkotó eszközökkel, amiket szintén pénzért, de bárkinek engednek használni.
Az Nvidia és a Google mellett viszont megjelentek más szereplők is, akik egyre közelebb hozták a halandóhoz a már betanított és nyugodtan használható AI eszközöket. A Dall-e 2 és a Midjourney AI teljesen megváltoztatta a művészetről alkotott korábbi képünket. Pár kulcsszó megadásával olyan képeket lehet létrehozni szinte bármilyen stílusban, ami, mint említettem, évtizedes tanulás mellett sem valószínű, hogy megvalósítható.
Ezekben a fenti példákban az a közös, hogy bár mi magunk generálhatunk képeket velük, általában pár kép után fizetőssé, havidíjassá válnak, ráadásul ezek a cégek ellenőrzik azt is, hogy mit hozunk létre, cenzúrázhatnak, babrálhatnak dolgokat, és mi nem is taníthatjuk ezeket a rendszereket. Az AI képgenerálás tehát közeli, könnyen elérhetővé vált, de csak pénzért juthat el a halandókhoz.
Az elmúlt három-négy hétben viszont minden megváltozott. Megérkezett a Stability AI, a HuggingFace és a CoreWeave kutatói és mérnökei által létrehozott, nyílt forráskódú Stable-Diffusion, ezzel pedig új korszakot nyitottak a képgeneráló AI-k elérhetőségében.
A Stable-Diffusion megjelenése történelmi fontosságú. Az AI nem csak, hogy nyílt forráskódú, de a HuggingFace előre betanított modelljét is használhatjuk hozzá, ami annyit tesz, hogy otthon, cenzúra vagy adathalászat félelme nélkül, bármilyen képet generálhatunk magunknak, ha van elég erős számítógépünk, és emellett még kereskedelmi célokra is használhatjuk a rendszert.

Azt a lehetőséget hozta el a Stable-Diffusion bárki számára, amit eddig csak fotósok, festők és alkotók tudtak megalkotni számunkra úgy, hogy távoli helyekre utaztak, fotómodellekkel dolgoztak együtt, vagy órákon át rajzoltak, festettek, modelleztek. Ezentúl viszont pár másodperces generálás után mi magunk is elkészíthetünk bármilyen remekművet, mindezt pedig látványos, akár azonnal használható formában.
Ráadásul mivel a rendszer nyílt forráskódú, ezért a közösség saját maga készíthet erre épülő programokat, így az eddig csak mérnökök és kutatók által érthető nyelvet már te is tudod használni, hamarosan azt is megmutatom, hogy te hogyan alkothatsz képeket magadnak.
Miként működik?
Emlékeztek még a cikk elején gyorsan összedobott könyvborítóra? Azokat a képeket a Stable-Diffusion-nel készítettem, a saját videokártyám futtatta le a szükséges számításokat a HuggingFace 1.4-es módosított modelljét használva. Mint említettem, a training modellek, avagy a betanított csomagok hatalmas értéket képviselnek, az, hogy a HuggingFace közösség kutatóanyaga így az emberiség közös kincsévé lett, egészen érdekessé fogja varázsolni az eddig csak üzleti alapon működő AI világot.
A MidJourney AI-ról már beszéltem korábban. Ők más modelleket használnak, így hiába adod meg ugyanazokat a kulcsszavakat, sosem fogod ugyanazt az eredményt látni, mint a Stable-Diffusionnél.
Kíváncsiságból azért nézzük is meg, hogy mit dob a korábban kipróbált és bevált prompt csomagra a MidJourney AI?

Az első dolog, ami szembe jön, hogy a „sexy” szó „bannolt”, avagy nem lehet megadni ezt a kifejezést, mert tiltólistán van. Itt már azonnal érezhető is, hogy mekkora különbség van aközött, ha egy vállalat, és aközött, ha egy szabad szoftver irányítja a képgenerálás folyamatát. A MidJourney-el nem fogsz tudni 18+-os képeket készíteni, a Stable-Diffusionnél úgy hallottam a szomszéd néni ismerősétől, hogy ez nem probléma. Már ha egy barátod anyukájának a fia kérdezné tőled ezt, azért jó, ha tudsz neki válaszolni erre a kérdésre, hogy igen, lehet néniket és bácsikat így, úgy és amúgy is generálni.
A másik, amit viszont észrevehetünk, hogy a MidJourney AI sokkal inkább van a művészetre tréningezve, és szinte bármilyen promptot adunk meg neki, első ránézésre mindig szinte tökéletes, szemnek gyönyörködtető lesz az eredmény.

De mi is a prompt? A prompt az, amivel lényegében megsúgod a gépnek, hogy mit szeretnél látni. „Egy kiscica leesik a fáról, miközben egy hurrikán lerombol egy házat. Fotó minőségben, nagy látószög.” Ha ezt így leírod az AI-nak, akkor megpróbál ebből valamit kihozni, és megépíti a képet neked. A cikkbe ágyazott képek környékére a legtöbb esetben odaírtam, hogy milyen prompt-ot használtam, hasonló beállításokkal ugyanolyan eredményt tudsz elérni, mint amit én is készítettem. Annyi viszont fontos, hogy az én modellem, amivel legtöbbször dolgoztam (nem mindnél), az a cikk írásakor a legújabb, az 1.4-re épülő 1.4 Waifu Diffusion. De az is lehet, mire ez az írás kikerül, már megjelenik a HuggingFace 1.5 is, ami szintén publikus, de már fejlettebb modell lesz, így azzal is más eredményt fogsz kapni.
Azt már átbeszéltük tehát, hogy a másként tréningezett anyag különböző eredményt hoz. De miként születik meg a kép végül?
A Stable-Diffusion úgy működik, hogy véletlenszerű zajt generál, arra pedig elkezd valamit rá generálni, amit megírtál neki, abból a tudásból, amit birtokol. Azért, hogy ez ne tartson végtelen ideig és ne foglaljon végtelen helyet, ezért ez az AI alacsony felbontásra, 512x512-re van optimalizálva, ami azt jelenti, hogy az ilyen méretű képekkel képes a legjobban dolgozni. Elkezd elkészíteni egy képet, aztán egy másikat, aztán egy másikat, aztán egy másikat, egészen addig, amíg mi azt nem mondjuk neki, hogy elég.
Minden egyes képpel egyre jobban finomodik a gép ízlése. Természetesen minél több lépésből áll egy kép, annál jobb lesz a minőség, ám ez annál több időt is igényel. Egy 50 lépéses kép elkészítése 50x több időt igényel, mint egy színes pacából álló, semmire sem használható egy lépéses kép.

Az alacsony felbontás másik előnye, hogy így nem képes a gép lemásolni az eredeti képeket. Ha például megtanították az AI-t egy adott művész stílusára, nem fogja tudni a gép egy az egyben visszaadni ugyanazt a képet, mint amiről tanult, mert csak az ismertető jegyeire elég információja van. Emlékezetből tehát nem tud rajzolni, így elméletileg elkerülhető az is, hogy a gép szerzői jogi problémákat okozzon, például Bob Ross festménye egy az egyben nem fog megjelenni előttünk, csak annak egy másolata. Érdekes adaléka viszont ennek, hogy néha még az aláírás is rágenerálódik egy-egy képre úgy, hogy az olvashatatlan formában, de megjelenik. Felmerül a kérdés is, hogy etikus-e, illetve jogos-e élő alkotók stílusát „ellopni” a jobb modell érdekében, de erre jelenleg nincs még se jogi, se erkölcsi válasz.
Annak a kérdése is felmerülhet, hogy mit kezdhetünk a mai világban alacsonynak számító képfelbontással, amit a generálás után kapunk. A jó hír, hogy a felbontás manapság már javítható. Több olyan AI is létezik, ami kifejezetten arra van kiképezve, hogy alacsony felbontású képet sokkal nagyobbra varázsoljon. Nem csak egyszerűen megszorozza a kép méretét, hanem konkrétan újra alkotja úgy a képet, hogy úgy tűnjön, valóban ilyen felbontású volt az eredeti anyag is. Ez a megnagyobbítás viszont nem visszaállítja a soha meg nem volt információt, hanem kiegészíti olyan dolgokkal, amik az adott környezetben ott szoktak lenni.
Itt is van egy felnagyított Chuck Norris kép, amit az AI istenének büntetéseként is értelmezhetnénk.

Az eszköz, ami épít
Egyre több médiafelületen foglalkoznak az AI képgenerálás kérdésével, ám a legtöbb próbálkozás kifullad abban, hogy béna eredményeket kap, így elkönyveli, hogy nem használható érdemben semmire. Ezek a felületes tesztek viszont általában nem veszik figyelembe azt a tényt, hogy ezek az algoritmusok nem hétről-hétre, hanem óráról-órára fejlődnek, hiszen pont ez a lényegük, hogy tanuljanak, a fejlesztők meg azon dolgoznak, hogy jobbak legyenek.
Sokan felhozzák, hogy az AI nem tud kezet rajzolni, ami lehet, hogy most igaz, de igaz lesz ez holnap is? Azt is felróják, hogy nem képes emberi arcokat szépen megjeleníteni, de szerintem a cikk is bizonyítja, hogy ez már most nem állja meg a helyét. Ha mégis lennének rossz arcú eredmények, van már olyan AI, ami kifejezetten arra készült, hogy kijavítsa az elrontott AI arcokat. Sok Stable Diffusion szoftver már eleve ezt tartalmazva érkezik meg.

A másik, hogy jól kell megmondani a gépnek, hogy mit akarunk látni, és milyen módon. A megfelelő kulcsszavak kitalálása és keresése nem könnyű, de nem is egy bonyolult dolog rálelni a nekünk tetsző promptokra. Az egyik leglátványosabb segítség például a Lexica.art, ahol beírhatjuk, hogy mit szeretnénk gyártani, és a korábban publikus felületen generált képek között válogathatunk. A képekre kattintva megnézhetjük, hogy az adott képhez milyen prompt és seed kellett, majd mi magunk is legenerálhatunk valami hasonlót. Hasonló segítséget nyújt a Promptomania és rexwang8 saját oldala is, de tele van az internet segítséggel és ötletekkel.

Ha megtaláltuk a nekünk tetsző stílust, akkor a megfelelő szavakat átírva még egyedibbé tehetjük. Cserélhetjük a művészt, a kép témáját, és persze a bővíthetjük, szűkíthetjük olyan dolgokkal, amikkel akarjuk. A kulcsszavakon túl rendelkezésre áll nekünk egy úgynevezett seed szám is. Ez az a szám, ami alapján megkezdődik a véletlenszerű generálás. Ha egy képhez ugyanazokat a tulajdonságokat adjuk meg, de a seedet nem változtatjuk, akkor a gép mindig ugyanazt a képet generálja le.
Egy kép készítésénél általában változtathatjuk a felbontást, és azt is, hogy a kulcsszavak mennyire legyenek befolyással a végeredményre. Például lehetséges beállítani, hogy a gép jobban ragaszkodjon ahhoz, amit kérünk tőle, de akár a saját fantáziáját is elengedheti, ez tőlünk függ. Az 512-es felbontásnál nagyobb képet viszont az említett gépigény miatt nem nagyon fogunk tudni létrehozni, maximum utólagos növeléssel.

A helyzet az, hogy bármilyen egyszerű is ez az egész, meg kell tanulni használni. Egy magyar hírportál az egyik tesztjében például azt sem vette figyelembe, hogy amiket tesztelt AI-k, azok bár különböző honlapokon voltak, pontosan ugyanazt használták, vagyis a Stable Diffusion 1.4 Hugging Face modellt. Ezen túlmenően ráadásul magyar specifikus dolgokkal próbálkoztak, amikre nem igazán vannak betanítva még ezek a modellek; a magyar miniszterelnökről értelemszerűen kevesebb kép van beléjük táplálva, mint az amerikai elnökről. A jövőben ez változhat, de jelenleg kevés tudással rendelkeznek Magyarországról és a magyar híres emberekről, és mivel ezek a modellek nem valós időben kutatják fel a netet információért, ezért mindig csak a legutóbbi verzió kiadásának a tudását tartalmazzák.
Nos, hogy ezeket átbeszéltük, jöjjön a lényeg. Miként lehet ezeket kipróbálni?
Jelenleg háromféle AI-t tudok ajánlani a fent már említett, tájképekre szakosodott Nvidia Canvason kívül. Van több is, de a mai cikkünk témája ezzel a fajta képalkotással, a szövegből-képet, és a képről-képet generátorokkal foglalkozik.
Az egyik a Dalle-2 béta, amihez nekem sincs még hozzáférésem, de lehet igényelni, hátha hamarosan kapsz. Ezt sokan szeretik, pár generálás ingyenes, de utána fizetőssé válik majd, szóval nem hosszútávú dolog.
A Midjourney AI szintén ingyenesnek tűnik, de a valóság az, hogy csak pár generálásig fogjuk tudni használni. Ha ki szeretnéd próbálni, menj fel a linkelt honlapra, csatlakozz a Discordra, lépj be egy „newbies” szobába, kezdd el írni azt, hogy /imagine és utána angolul azt, amit látni akarsz. Ha segítség kell az angol nyelvhez, akkor az AI alapú DeepL fordítóval probléma nélkül tudsz bármit szinte tökéletes angolra lefordítani, a már linkelt Lexicán pedig könnyen találsz tippeket is, hogy mit írj be.
A Midjourney tehát látványos, elsőre és kevés prompt mellett is gyönyörű eredményt nyújt, de nagyon fontos tudnod, hogy hamar fizetőssé válik, és az eredményt mindenki látja a világon.
Végezetül pedig el is érkeztünk a Stable-Diffusion AI-hoz, amihez viszont több módon is hozzáférhetsz.

Ha minimum RTX videokártyával rendelkezel, amiben van legalább 8GB RAM, akkor ez a leírás lehet a segítségedre. Ezzel az útmutatóval jó eséllyel a legjobb Stable-Diffusion élményt tudod magadnak megadni, én általában ezt használom.
Az eszköz az elmúlt két hétben hatalmas fejlődésen ment keresztül. A kezdeti egyszerű, csak szövegből kép program mára már képes képből-képet is generálni, arcot javítani, felbontást növelni és még sorolhatnám. Zseniális cucc.
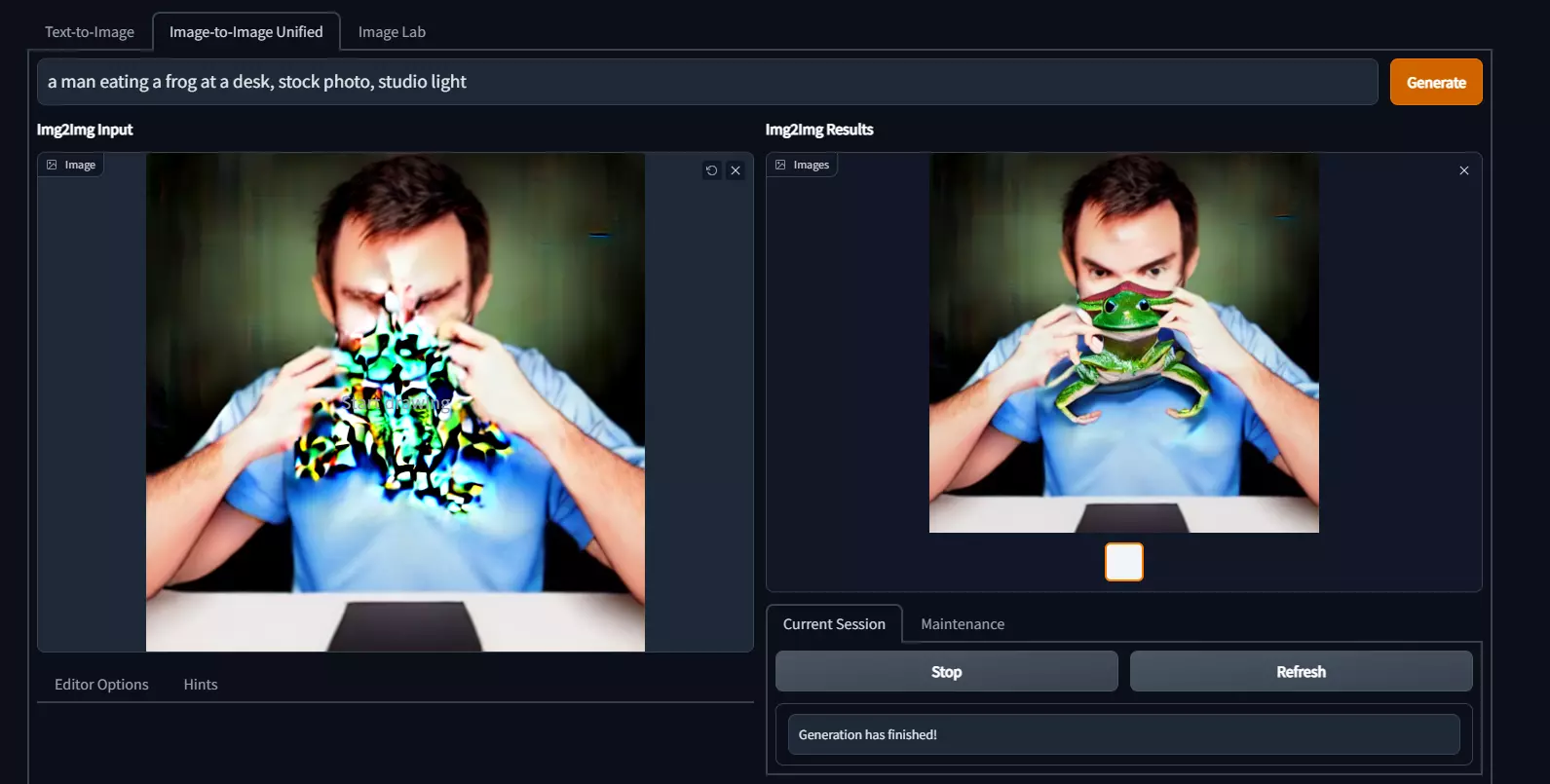
Ám, ha nem szeretnél a konfigurálással bajlódni, szerencsére van ennél is egyszerűbben telepíthető megoldás. Az ingyenesen elérhető NMKD Stable Diffusion GUI nagyszerű és könnyen installálható lehetőség az AI használatára. Segítségével szinte minden fontos funkciót elérhetsz, de nem feltétlenül tartalmazza a legújabb és legjobb funkciókat.
Viszont van egy pár rossz hírem is. Ha gyenge géped van, esetleg AMD kártyád, akkor sajnos nehezebb lesz működésre bírnod a Stable-Diffusion rendszert. Ha ilyen helyzetbe kerülnél, akkor ezt a leírást kövesd.
Ha nem szeretnél semmilyen telepítéssel bajlódni, a Stable-Diffusion kipróbálható a Dream Studio weboldalon is, de ahogyan a Midjourney-nél, itt is meg van szabva, hány képet generálhatsz. Egy idő után sajnos el fog fogyni a kvótád és nem használhatod tovább a felhős számítási kapacitást. A DreamStudio viszont a cikk írásakor először rendelkezik az 1.5-ös HugginFace modellel, így jó eséllyel mindig itt lehet leghamarabb kipróbálni az új modelleket.
Az AI képgenerálás csalás vagy művészet?
Így a cikk vége felé, térjünk vissza kicsit az AI és az ember munkakapcsolatára, vagyis az egész emberi oldalára. A kérdésre a válasz az, hogy sokak szemében, így az enyémben is, jelenleg csalás. Ennek ellenére azt is érzem, hogy mégsem csalás, sőt, kontextustól függően igenis van legális és érthető létjogosultsága.

Ha a saját példámat nézem, most egyszerre dolgozom egy könyvön és egy játékon is. Az igazság az, hogy vannak olyan területek, mint például az épületek és tájképek, amiben nem vagyok túl jó, márpedig az ilyen illusztrációk elkészítésében nagyban segít nekem mostantól az AI. Kell nekem egy iskolai terem háttérnek? Szerzői jogvédelmi vagy a tankerületi harag nélkül tudok generálni magamnak ilyen fotókat, és tudom használni őket a játékomban. Egy barlang illusztrációra van szükségem egy hatalmas pókkal a falon? No para, maximum kicsit átrajzolom és tökéletes lesz az eredmény a könyvembe.
A másik, hogy az AI segít új karaktereket megalkotni, kitalálni. Pár generálással kibővíti a látóteremet, olyan ruhákat, színeket, hangulatot vagy plánokat mutat nekem, amik izgalmasak és inspirálnak arra, hogy valami hasonlót alkossak. Az alkotási folyamat elején órák mehetnek el azzal, hogy referenciaképeket gyűjt az ember a neten. Ezentúl viszont miért ne építhetne fel a gép nekem egy referenciatáblát?
Szinte minden 3D-s modellt fel kell valahogy textúrázni. Ez azt jelenti, hogy a 3D modellre valamilyen kétdimenziós képet kell rakni, így úgy fog kinézni, mintha beton, fa vagy valamilyen anyag lenne. Ilyen textúrát létrehozni fárasztó és monoton, márpedig az AI a textúrakészítésben is tud segíteni. Ezek a képek mindenképpen olyanok kell, hogy legyenek, hogy minden oldala egymáshoz passzoljon, hogy ha ismétlődnek, ne tűnjön fel a vágás. Az AI megcsinálja ezt.

Ha így ezeket nézzük, ez így már nem is csalás, hanem segíti a munkánkat, a munkafolyamatomat. Pénzt és időt takarít meg nekem is és bárkinek, aki nem grafikus vagy mással szeretne foglalkozni.
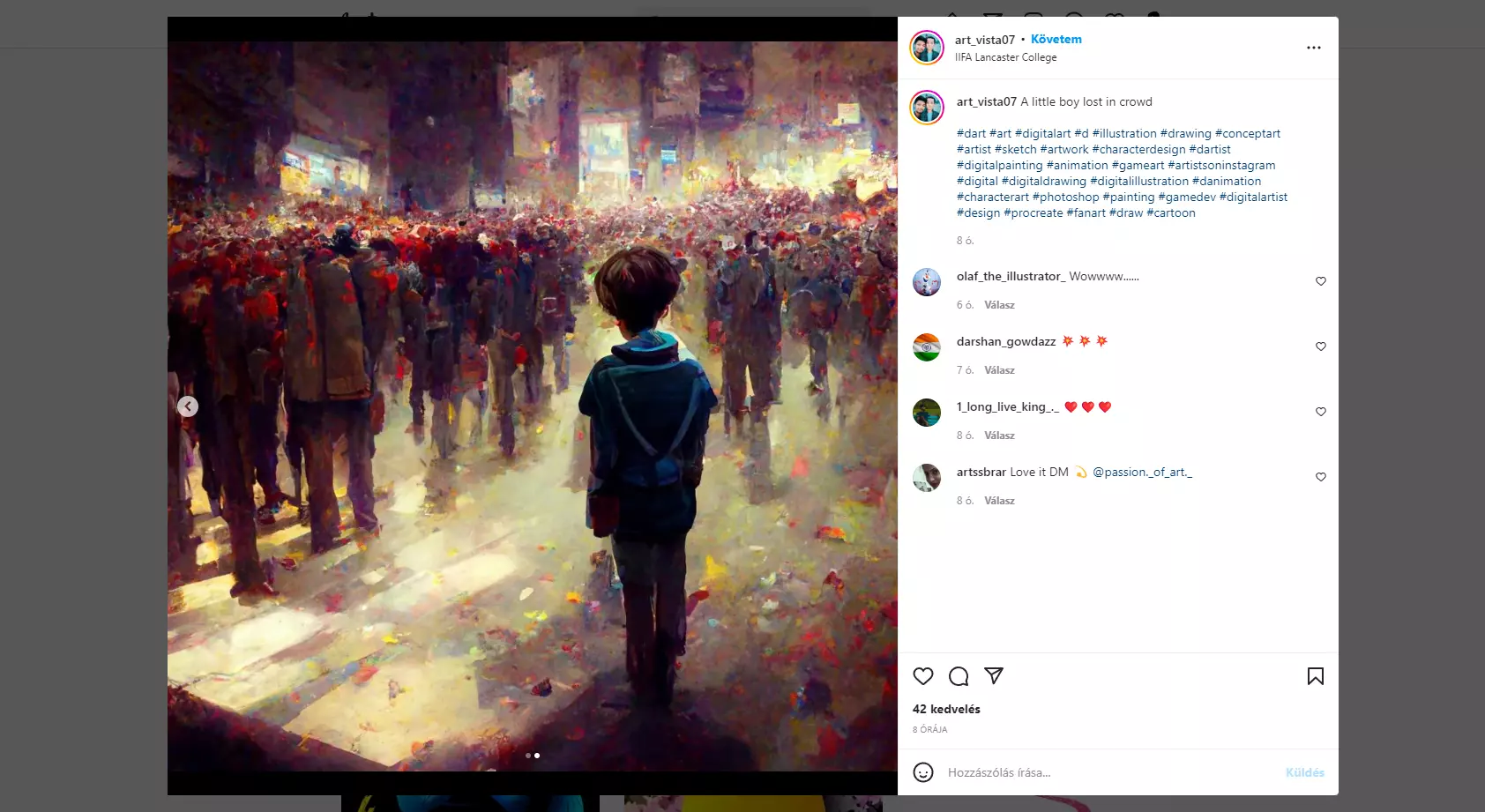
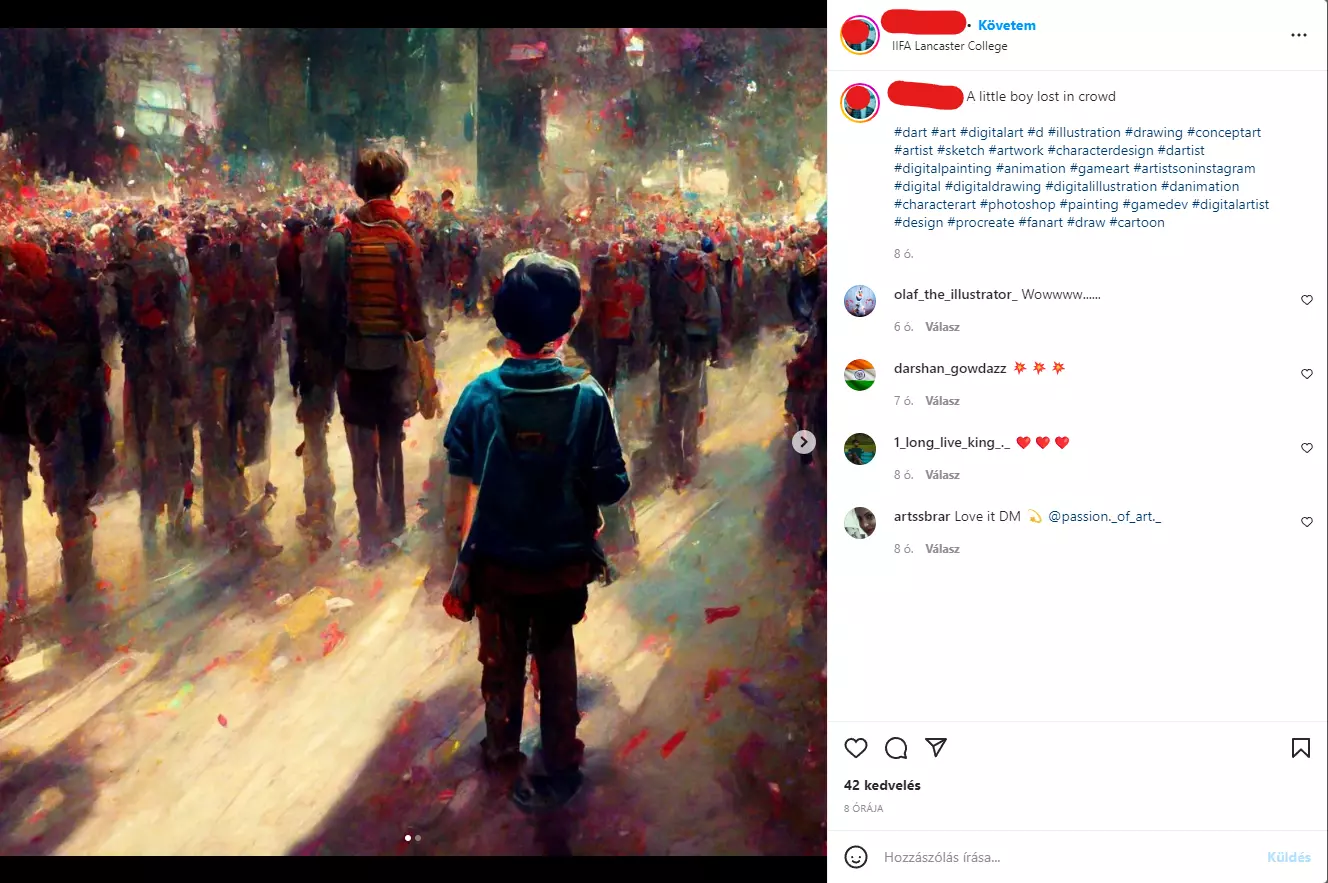
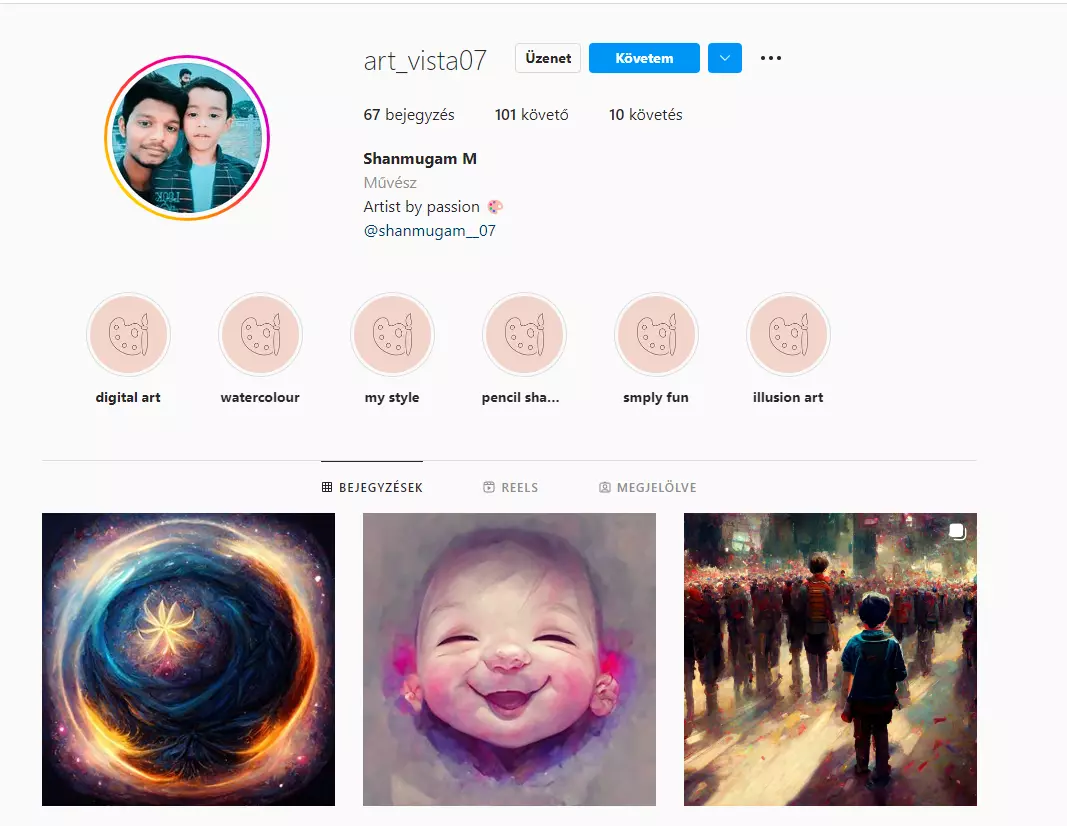
Másrészről viszont lehet nagyon is csalás, mint ahogyan a neten már több kóklerbe is belebotlottam. Instagramon és Facebookon is több csoportban feltűntek az olyan személyek, akik azt állítják magukról, hogy művészek, profi koncepció rajzosok, holott ha megnézzük a képeiket, akkor egy szakavatott hamar láthatja, hogy AI generálta anyagokról van szó.
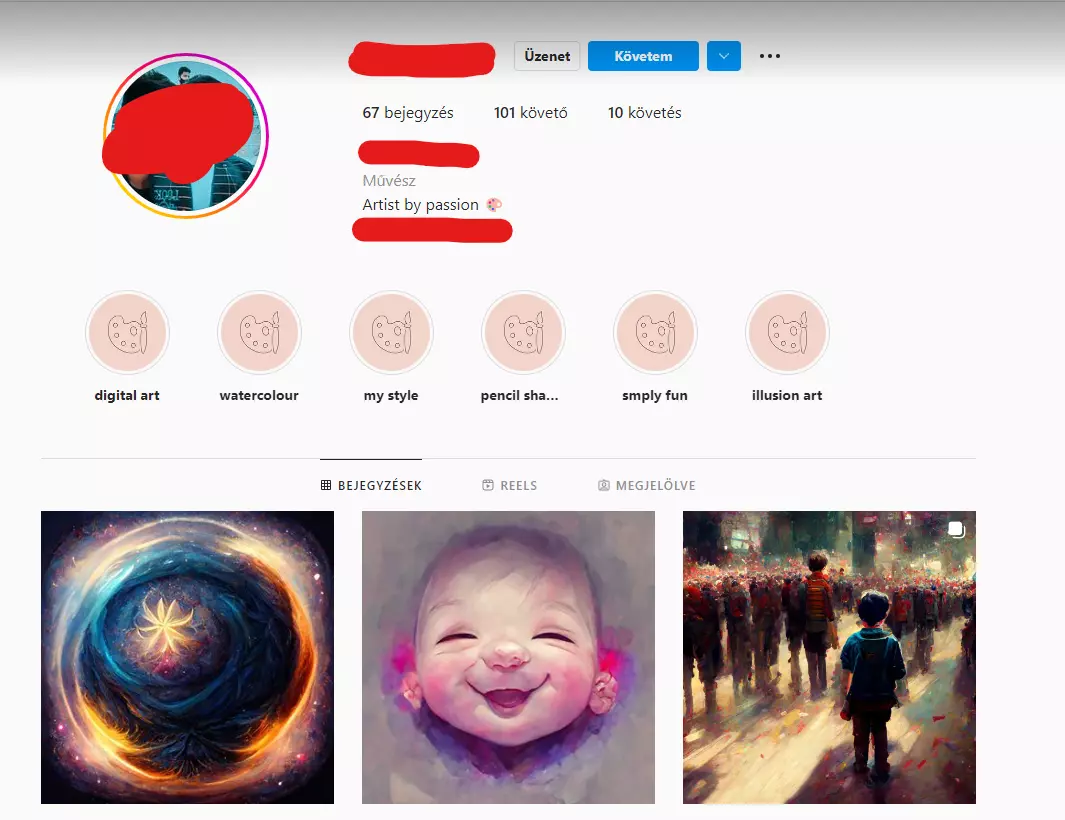
Ilyen például az alábbi művész is. Ha megnézzük a profilját, azt hihetnénk, hogy nagyon ügyes alkotó. A baj az, hogy a leírásokban azt állítja magáról, hogy ezeket ő csinálta iPaden, és ő egy profi koncepció művész.
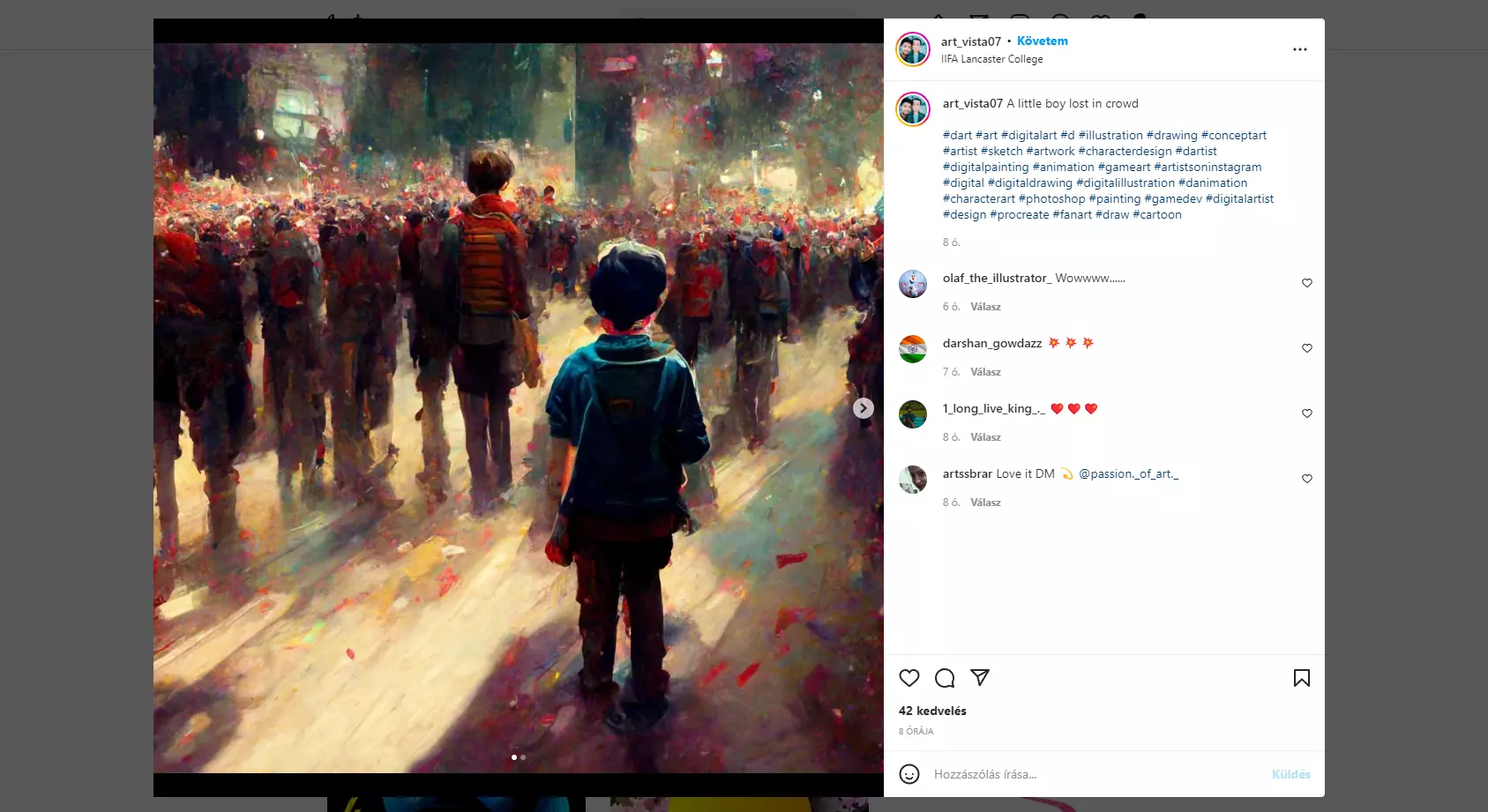
De hogyan lehetséges az, hogy egy ilyen profi pár nappal korábban a saját képeit még így festette meg, ezen az óvodás felhő színvonalán? Hogyan lehet ekkorát ugrani a skillek tekintetében pár nap alatt?
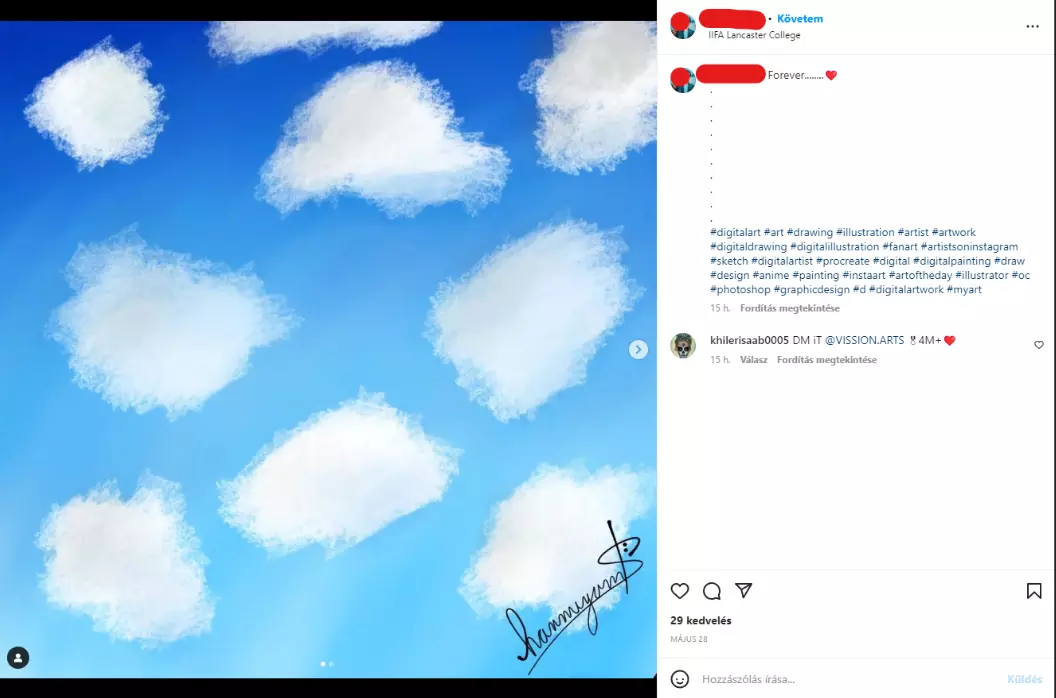
A válasz egyértelmű, sehogy. Ennek ellenére az AI képeket egyre többen próbálják meg úgy eladni, hogy saját mű, és bár nehéz megkülönböztetni az igazit az AI-tól, jelenleg nem lehetetlen. Például a fent látható képet most még egy AI-val foglalkozó grafikus azonnal kiszúrja. Nem volt nehéz észrevenni, hogy ez nem ember alkotása, és erre fel is hívtam a „művész” figyelmét, aki törölte a képeket szégyenében.
Ennek ellenére egyre több helyen látom az ilyen jellegű csalásokat, és ahogyan haladunk előre az időben, egyre nehezebb lesz megkülönböztetni az ember és a gép alkotásait.
Viszont van, hogy a fordítottja történik meg, és nem a géppel csalnak, hanem a „valódi” művészettel.
Jazza az egyik legnépszerűbb art projektekkel foglalkozó YouTuber, mindig érdekes kísérleteket tesz a csatornáján. Az ő videója azért kifejezetten érdekes, mert valódi művészeknek fizetett közel 500 000 ft-ot, hogy bizonyos utasítások alapján készítsenek neki képeket. Miközben várta az eredményt, ugyanezen utasításokat megadta az egyik AI szoftvernek is.
Jazza kísérlete nem várt eredményt hozott. Az AI-val ingyenesen generált képek szinte minden esetben sokkal jobbak lettek, mint a fizetett „művészek” alkotásai, de nem feltétlenül azért, mint amit elsőnek gondolnánk. A fizetett művészek nagy része ugyanis csaló volt. Eladták magukat olyan profinak, akik bármit meg tudnak csinálni egy adott stílusban, a valóságban viszont a legtöbbször az internetről lopták le a képeket, vagy pár perces munkával hánytak valamit a digitális vászonra, mindezt akár közel százezer forintos díjazás ellenére is.
Jazza lényegében egyetlen olyan művészt talált, aki megérte a pénzét, mert valóban azt dolgozta ki, amit kértek tőle. Érdekes módon ő volt a legolcsóbb mind közül.
Az eset jól mutatja, hogy csalók mindig is voltak és mindig is lesznek, szóval nem az eszköz a bűnös, hanem az ember, aki használja.
Nemrég többek között a Getty Images és a Shutterstock is bejelentette, hogy kitiltja az AI készítette anyagokat a rendszerből. Ez azt jelenti, hogy innentől kezdve csak emberi kézzel készült anyagok jelenhetnek meg ezeken a stock fotó, stock grafikai oldalakon, a gép generálta képek visszautasításra kerülnek. A kérdés az, hogy mennyi esélye van az embereknek kiszűrni a jobban sikerült generált képeket, illetve meddig lesz fenntartva ez a korlátozás.
De visszatérve a saját tapasztalatomra. Az előző hónapban egy game jam (játékkészítő verseny) VR játék készítő csapatban voltam 2D grafikus (trailer, hihi), és így én készítettem többek között az illusztrációkat is. Az egyik feladat az volt, hogy legyenek poszterek is a pályán. Ezeket különböző stílusban akartam elkészíteni, így kitaláltam, hogy készítek egy hónap dolgozója goblin képet is, valami folyékony tintás stílusban. Akkor még nem volt elérhető a Stable-Diffusion, de mi lett volna, ha ezt a feladatot a gépnek adom oda és nem én alkotom meg nulláról a képet?
Például úgy, ha csak ennyit adok meg:

Mint látható, az eredeti, bal oldali kép az enyém, ez az, ami bekerült a játékba is. A többi hatot viszont a cikk kedvéért generáltam le kb. 2 perc alatt a Stable Diffusion-nel. Az igazat megvallva, van pár, ami igazán egyedi és akár el tudnám képzelni a játékban minimális módosítások mellett. Az a bal alsó vörös, karmos koponyás izé mennyire menő már? Állat egy poszter lenne belőle, míg a mellette jobbra is egy igen vicces karikatúra.
Ami a képen viszont egyértelművé válhat mindenkinek, az az, hogy az AI jelenleg nem igazán képes írni. A szövegek és számok jelenleg nem élveznek prioritást, így ha azt kérjük az AI-tól, hogy írjon valahova valamit, akkor jó eséllyel nem fog megtörténni az, amit szeretnénk. Ez nem jelenti azt, hogy ez ne változhatna a jövőben, egy - két hónap múlva már lehet, hogy tökéletes filmposztert fog alkotni, kitalált stáblistával, akár több nyelven is, de ma itt még nem tartunk.
Az AI készítette animációkról ráadásul még nem is írtam, ez is megér egy misét, de lényegében azt a technikát használja, amit már korábban vázoltam, tehát van egy kép és azt módosítjuk apránként. A sok kis módosítással pedig létrehozhatunk egy animációt, ami látványos és egyedi élményt nyújt a nézőnek.
Lecserélheti-e a gép a művészeket?
Ha te művész vagy, és ezt megélhetési formaként űzöd, akkor nem tudok biztató dolgokkal szolgálni számodra. Véleményem szerint 10 éven belül a legtöbb 2D, 3D grafikus és fotós munkája lecserélhető lesz AI-ra, 20 éven belül pedig ezek annyira elterjedté válnak, hogy már mindenki tudni fog róla, és használni is fogja őket.
Ahogy a fent említett videó is mutatja, az a nem mindegy, hogy ki használja ezeket. A szakma hamar olyan szinten telített lesz, hogy csak a legjobbak maradnak majd életben, így nagyon fontos, hogy még időben fejleszd fel magad egy olyan szintre, amivel hasznosabbá válhatsz, mint egy AI szoftver. Ha úgy érzed, ez nehéz, akkor viszont azt javaslom neked, hogy ismerd meg az „ellenséget”, és használd ki annak előnyeit.

Bár kulcsszavakkal generálja az AI, amit szeretnénk, ha elég jó szemed van a szakmához, te lehetsz az, aki ezeket az eszközöket a legjobban kezeli, és olyan képeket tud készíteni, illetve úgy tudod majd ezeket használni, hogy ezek produkciókba is használhatók legyenek.
Ismerd meg annyira az ellenséget, hogy ha kell, akkor tudd módosítani azt. Tanítsd be te a saját stílusodra, készíts egyedi képeket, olyanokat, amikre más AI nem képes.

Bár az AI képkészítés manapság csalásnak számít, el fog jönni az idő, amikor már nem így lesz. Amikor megjelentek a digitális képszerkesztők, minden korábbi művész csalást kiáltott, eretnekség volt a Photoshop. Nem is olyan régen még a digitális utómunka a fényképek esetében például megbocsájthatatlan bűn volt. Amikor megszületett a photobashing ötlete, minden tradicionális digitális művész csalást kiáltott, ma pedig már olyan gigaprodukciókban használják a technikát, mint a Star Wars és a Dune, mivel látványos és gyors eredményt hoz.
Természetesen sorolhatnám még a „csalás” digitális művészeti evolúcióját, az viszont a múltat megnézve egyértelműen látszik, ha nem állsz valami újnak az élére, akkor jelentősen veszítesz a piaci értékedből, ezzel pedig a megélhetésed kerül veszélybe.
A zenészek egy része hasonló nehézségekbe ütközhet, mivel egyre több olyan AI van, ami egy koncertet is le tudna lassan adni úgy, hogy már énekel is mellé.
Gosztolya Gábor fenntartásokkal kezeli a következő kijelentésem, de nekem nincs kétségem afelől sem, hogy az AI hamarosan jobb programokat fog tudni írni, mint a programozók zöme. Szerintem a most nagyon jól fizetett szakma, a programozás is egy halálsorra kerülő tevékenység lesz, amiben csak a legjobbak maradnak majd életben. Programozókra mindig lesz szükség, de nem olyanokra, akik alig értik, hogy mit csinálnak, de eddig jók voltak egyszerű feladatok elvégzésében. Az igazi érték az alacsony szintű, vagyis a gépi kódú ismeret lesz, ami jó darabig, legalábbis a szingularitásig biztosan érték marad. De az ilyen programozók eddig is a világ legjobb techcégeinél vagy tudományos szervezeteinél dolgoztak, és sok esetben éppen egy olyan AI-t építenek, ami a sekélyebb tudású kollégáikat fogja feleslegessé tenni.
Bárhogy is alakul a jövő, a művészet szerintem az, ami megérinti az embert és hatással van rá. Bár sokan azt állítják, az AI alkotta kép nem művészet, mert annak szívből kell jönnie, én ezzel nagyon nem értek egyet.
Az én értelmezésem szerint a művészet többféle módon élvezhető és nem is kell szívből jönnie. Egyértelmű, hogy az a legjobb forgatókönyv, amikor az alkotó és a fogyasztó is élvezi a folyamatot vagy a produktumot. De szerintem akkor is művészet marad a végtermék, ha csak az egyik fél szívét érinti meg a dolog. Ahogy a cikk elején is említettem, a művészet régóta piacosított, nem kell, hogy az alkotó élvezze az alkotását, elég, ha a fogyasztó boldog. Márpedig, ha a fogyasztó élvezi a gép művészetét, vagy annak egy származtatott termékét, akkor egy szívet már biztosan megérintett a dolog.

De ugyanez igaz akkor is, ha a művészet szívből jön, ha egy alkotó készít valamit önmagának, például azért, hogy a saját érzelmeit feldolgozza. Ez a folyamat miért ne működhetne egy mesterséges intelligencia segítségével? Lehet valaki nem tud rajzolni, ám mégis sikerül egy olyan képet generáltatnia, ami megérinti a lelkét annyira, hogy hasznos legyen számára a dolog.
De történjék bármi is, az alkotás folyamatát, amit mi emberek magunk élvezetére végzünk, azért, hogy gyógyítsuk a lelkünket vagy lekössük az elménket, na azt sosem fogja tudni elvenni tőlünk egyetlen számítógép sem.
A szakmai lektorálást Dr. Gosztolya Gábor, az MTA-SZTE Mesterséges Intelligencia Kutatócsoport tudományos főmunkatársának köszönhetjük.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}