A GTC 2025 alkalmával a Blackwell Ultra sorozat tagjai mellett számos egyéb termékről is szó esett, például azt is elárulta Jensen Huang, hogy milyen GPU- és CPU architektúrák érkezésére számíthatunk az elkövetkező időszakban, már ami az AI és a HPC piacra szánt fejlesztéseket illeti. Jelenleg a Blackwell Ultra érkezésére várunk, ami masszív gyorsulást hoz FP4-es számítási teljesítmény terén, valamint memóriakapacitás tekintetében is – mindkét területen 50%-os előrelépésre számíthatunk –, és ez a fejlesztés még idén, valamikor az év második negyedévében debütálhat.
A 2026-os és a 2027-es esztendőkre is tartogat meglepetéseket a vállalat, ugyanis a Blackwell Ultra után érkezik majd a Vera és a Rubin architektúra – előbbi az ARM alapú processzort, utóbbi pedig az új GPU architektúrát takarja. Az is szóba került, hogy a Blackwell architektúra esetében hiba történt a név megállapításakor, már ami a szerverpiaci platformot illeti, hiszen a B200-as GPU igazából két darab lapkából áll, így a Blackwell B200 NVL72 név helyett igazából helyesebb lenne az NVL144 elnevezést használni, hiszen fizikailag 144 GPU lapkáról van szó, így ez a jelölés sokkal találóbb lenne.

A Rubin esetében végre is hajtják a névváltást, vagyis változatlan lapkamennyiség mellett immár az NVL144 nevet fogják használni, és a meglévő Blackwell NVL72 infrastruktúrával való kompatibilitás is megmarad, azaz egyszerűen be lehet majd vetni az új gyorsítókat a régi rack házak felhasználásával. Ahogy az az előadáson is elhangzott, míg a B300 NVL72 esetében a Dense FP4 számítási teljesítmény 1,1 ExaFLOP/s lesz, addig ez az érték a Rubin NVL144 érkezésével már 3,6 ExaFLOP/s-ra növekszik. A Rubin az FP8-as számítási teljesítmény terén is óriási előrelépést hozhat, hiszen míg a B300 mellett 0,36 ExaFLOP/s-os számítási teljesítmény érhető el, addig a Rubin esetében ez az érték már 1,2 ExaFLOP/s lesz, vagyis itt is több, mint háromszoros gyorsulásra van kilátás.

Az új GPU architektúra mellé új memória-alrendszer is érkezik, azaz a HBM3/HBM3E memóriachip-szendvicseket lecserélik HBM4-es megoldásokra, a Rubin Ultra esetében pedig a HBM4E is bevetésre kerül. A memóriakapacitást a B300-nál látott szinten, azaz 288 GB-on hagyják, viszont a memória-sávszélesség 8 TB/s-ról egészen 13 TB/s-ra növekszik. Gyorsul az NVLink is, ami így kétszer nagyobb adatátviteli sávszélességgel dolgozhat, ez 260 TB/s-ot jelent, az egyes rackek között pedig immár CX9-es kapcsolat húzódik, ami a B300-nál alkalmazott CX8-hoz képest szintén dupla akkora adatátviteli sávszélességet nyújt – ez 28,8 TB/s lesz.
A Rubun GPU architektúra mellé egy új CPU architektúra is érkezik, ami a Vera nevet kapja majd, ezzel leváltva az éppen használatos Grace modelleket. A kompakt kivitelben érkező újdonság a tervek szerint 88 darab ARM alapú processzormagot és 176 szálat foghat munkára – ezek természetesen egyedileg módosított magok lesznek. Az új processzor esetében 1,8 TB/s-os NVLink kapcsolat biztosítja majd a kommunikációt a Rubin alapú grafikus processzorokkal.
A következő lépcső a Rubin Ultra lesz, ami valamikor 2027 folyamán debütálhat. A Vera CPU továbbra is a kínálat részét képezi majd, viszont a GPU részleg egy igen komoly gyorsuláson eshet át. A rack alapú rendszernél teljes átalakítást eszközölnek, ennek köszönhetően NVL576-os dizájn jön létre, ami 576 GPU alkalmazását eredményezi. Az FP4 teljesítmény immár 15 ExaFLOP/s-ra rúghat, míg az FP8-as teljesítmény 5 ExaFLOP/s lehet, azaz négyszer gyorsabb lesz az NVL576-os rendszer, mint a korábbi NVL144-es – nagyrészt azért, mert pontosan négyszer több GPU-t rejt majd. Az egyes grafikus processzorok ebben az esetben kettő helyett immár négy lapkát rejtenek majd, azaz elég nagy lesz a számítási sűrűség.
Míg az NVL144 alapú Rubin szerverek 75 TB-nyi „gyors memóriával” érkeznek, addig a Rubin Ultra esetében az NVL576-os dizájn révén 365 TB-nyi memória állhat rendelkezésre. Utóbbi esetben HBM4E alapú fedélzeti memóriáról van szó, ami az Nvidia szerint 4,6 PB/s-os memória-sávszélességgel bír, ez pedig azt jelenti, hogy egy GPU-ra mindössze 8 TB/s-os memória-sávszélesség jut, azaz kevesebb, mint amit a normál Rubin esetében láthattunk. Lehet, hogy ez annak az eredménye, hogy az új fejlesztésnél nem kettő, hanem négy darab GPU lapul egy tokozáson belül. A négy lapkát tartalmazó GPU 1 TB-nyi HBM4E memóriát oszthat be, az FP4 teljesítmény pedig 100 PetaFLOP/s lehet.
Az új rendszer esetében NVLink 7 kapcsolatot használnak, ami hatszor gyorsabb lesz, mint amit a normál Rubin alapú termékek használhatnak, azaz 1,5 PB/s-os adatátviteli sávszélesség elérésére nyílik lehetőség. A CX9-es összekötők szintén négyszeres gyorsuláson mennek keresztül, ami 115,2 TB/s-os adatátviteli sávszélességet eredményez – valószínűleg azért, mert megnégyszerezik a linkek számát.
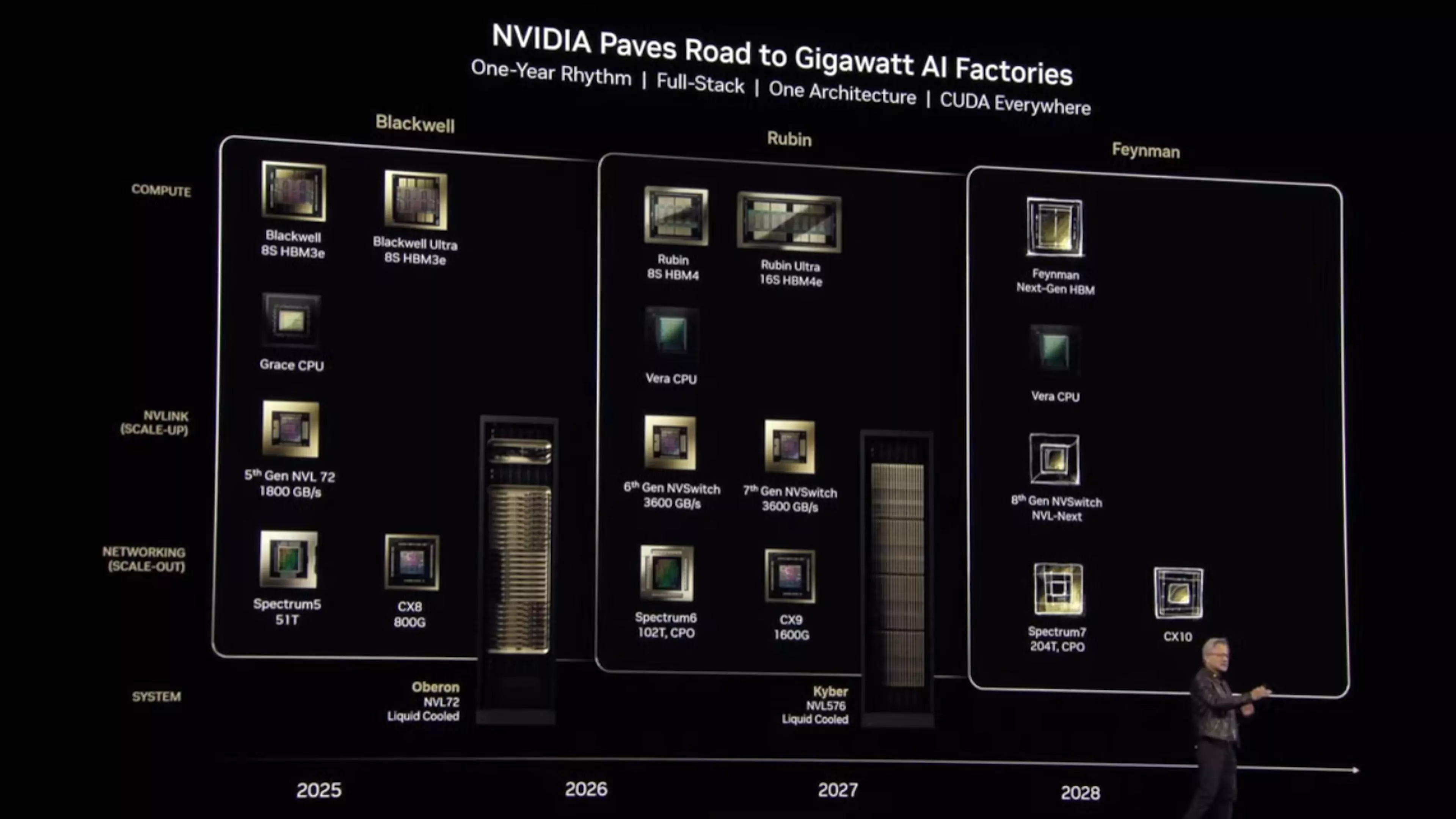
Noha a Rubin és a Rubin Ultra architektúra köré épülő fejlesztésekkel kapcsolatban egyelőre eléggé szűkszavúnak bizonyult az Nvidia csapata, azt azért elárulták, milyen új architektúrák érkeznek később. Úgy tűnik, a Rubin után a következő a Feynman lesz, ami egy elméleti fizikus, Richard Feynman után kapja a nevét – ennek megfelelően a CPU architektúra a Richard nevet viselhet, már ha az Nvidia folytatja az eddigi gyakorlatot a nevezéktan esetében.
