
Nemrégiben zajlott le az Intel Architecture Day 2018, amelynek keretén belül kiderült, milyen újításokkal készül a vállalat CPU és GPU fronton az elkövetkező évekre. Egyes témaköröket elég részletesen kitárgyaltak az illetékesek, míg más témakörökben éppen csak a felszínt kapargatták, hogy felkeltsék az érdeklődést és tűkön ülve várjuk, mire is készül pontosan a cég.
Útitervek mutatják az irányt
A vállalat az Atom, illetve a Core sorozat esetében egyaránt felvázolt egy-egy jövőképet az érkező architektúrákkal kapcsolatban. Fontos, hogy a név ezúttal csak magát az architektúrát jelöli, a köré épülő processzorok teljesen más kódnevet kapnak majd – a Sunny Cove architektúra például az Ice Lake processzorok alapját adja.
Kezdjük is a sort ezzel, vagyis a Sunny Cove architektúrával, ami már 2019 folyamán debütál a piacon. Hogy mire számíthatunk? Megnövelt egyszálas teljesítményre, 10 nm-es gyártástechnológiára, új utasításkészletre, valamint jobb skálázhatóságra és AVX-512 támogatásra is. Ez, vagyis a Sunny Cove architektúra a jelek szerint a Gen11 GPU architektúrával karöltve alkotja majd az Ice Lake CPU sorozatot.
Egy évvel később, 2020 folyamán már a Willow Cove architektúra érkezik a piacra, ami szintén 10 nm-es csíkszélesség köré épülhet – legalábbis ez tűnik valószínűbbnek, a 7 nm talán egy kicsit korai lenne. A Willow Cove esetében a gyorsítótárakat kissé átalakítják, ami az L1/L2 Cache szerkezet megreformálására utalhat, de ezzel együtt tranzisztor optimalizációkat is végrehajtanak, plusz további biztonsági szolgáltatások is megjelennek majd a fedélzeten, amelyek alighanem az újabb oldalcsatorna alapú támadások ellen is védenek.
A Golden Cove lesz a következő, 2021-es lépcső, amelynél már tippelni sem igazán lehet, mely gyártástechnológia köré épül – a 10 nm és a 7 nm egyaránt esélyesnek tűnik. Ennél az architektúránál tovább növelik az egyszálas teljesítményt, valamint az AI teljesítményre is figyelmet fordítanak, ami AI gyorsító integrálását is jelentheti. A lapka hálózatkezeléssel kapcsolatos újításokat szinténfelvonultathat, valamint tovább növelik a biztonságot.
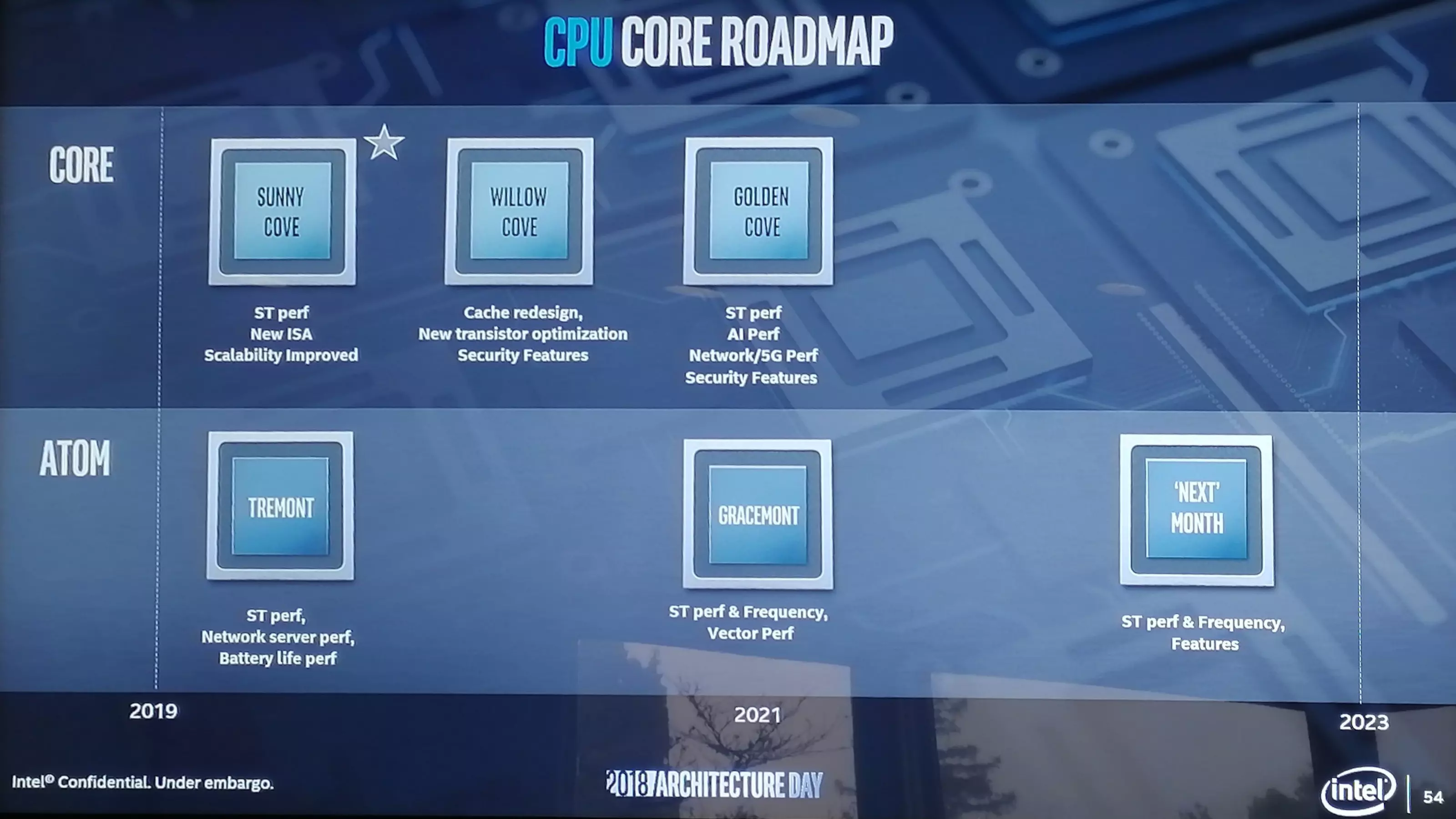
Az Atom családban ugyanebben az időszakban kicsit lassabb ütemben érkeznek majd a friss megoldások. 2019 folyamán a Tremont mutatkozik be, amely az egyszálas teljesítmény növelésére, az akkumulátoros üzemidő javítására, valamint a hálózati kiszolgáló teljesítményére koncentrál. A Tremont architektúra köré épülő termékek jó eséllyel 10 nm-es csíkszélességgel készülnek majd.
A Tremontot a Gracemont követi majd, egy év kihagyással, tehát 2021-ben jelenik majd meg. Ennél a fejlesztésnél az órajelek növelésére, illetve az egyszálas teljesítmény további emelésére fordítanak kiemelkedő figyelmet, amelyekhez megnövelt vektorteljesítmény is társul, azaz vagy szélesebb vektor egységek, vagy újabb vektor utasításkészletek érkeznek – esetleg mindkettő.
A következő lépcső a „New Mont” architektúra lesz, ami csak egy munkanév, vagyis a 2023-as architektúra is valamilyen „mont” tartalmú nevet kap, de még nem döntötték el, mi legyen az. Az új architektúra új szolgáltatásokkal, nagyobb egyszálas teljesítménnyel, magasabb órajelekkel és egyéb újításokkal érkezhet.
Nézzük meg közelebbről a Sunny Cove architektúrát
A Sunny Cove esetében egyebek mellett a back-endről is szó esett, amiből kiderül, hogy az L1 adat gyorsítótár 32 KB helyett 48 KB-ra hízik, vagyis 50%-kal megnövelik. Ezzel együtt az L2 Cache kapacitása is nőni fog mind a Core, mind pedig a Xeon lapkák esetében, azt azonban még nem árulták el, pontosan mekkora lesz az új L2 Cache. Jelenleg a Core sorozatnál 256 KB-os, a Xeon sorozatnál pedig 1 MB-os L2 Cache van érvényben, tehát ennél biztosan többet kapnak az új processzorok. Emelkedik a micro-op (uOp) cache mérete is, ami most 2048 bejegyzést tud tárolni, igaz, azt ebben az esetben sem részletezték, hogy az új uOp pontosan mekkora lesz. Szintén nőni fog a másodszintű TLB mérete, egzakt szám viszont ebben az esetben sem érkezett.
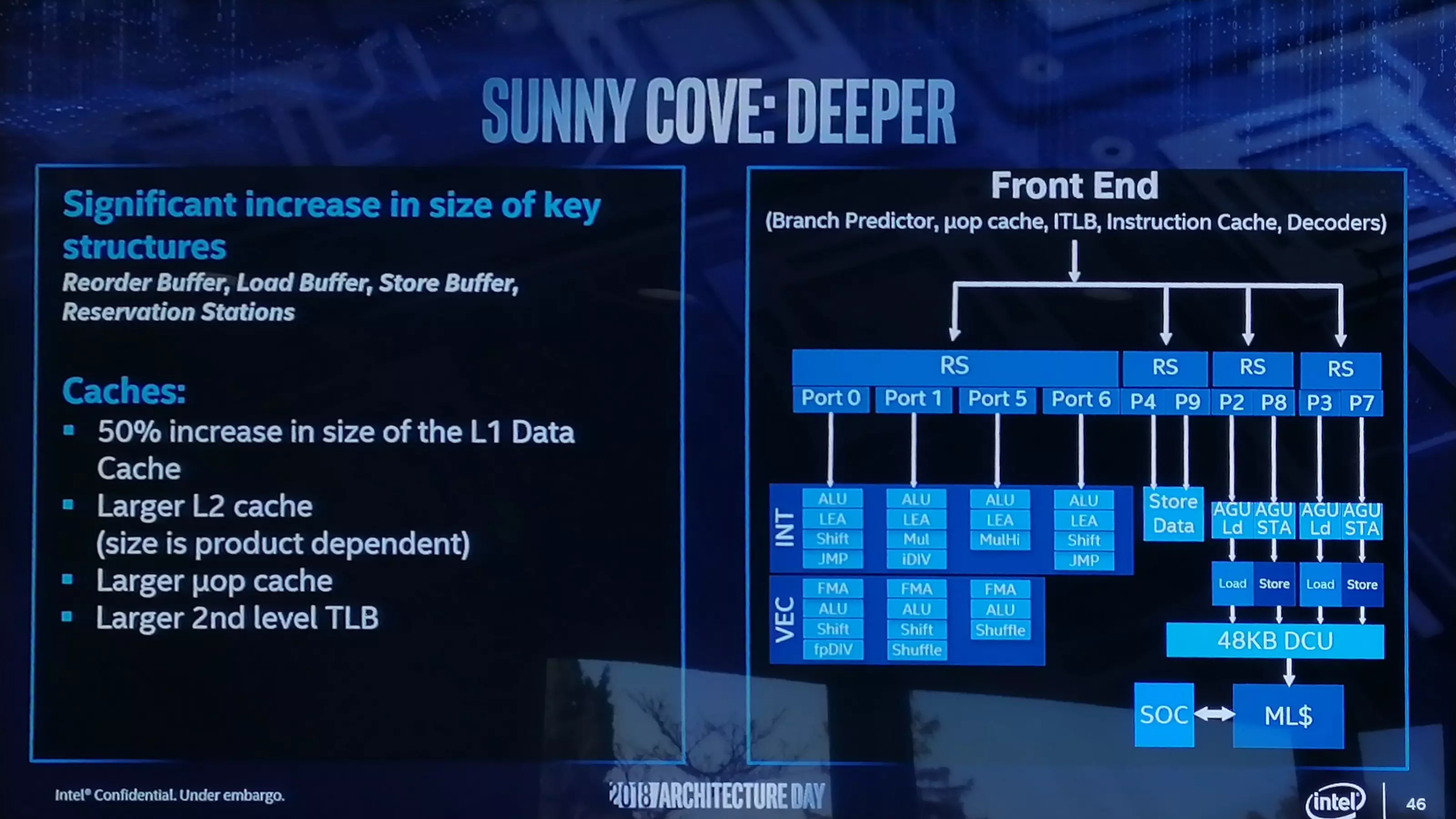
A front-end esetében a végrehajtó portok számát nyolcról tízre növelik, így az időzítőkből egy időben több utasítás jöhet ki, mint eddig. Ennél a dizájnnál a Port 4 mellett a Port 9-re is kapcsolódhat egy-egy adattároló regiszter, azaz a sávszélesség duplájára növekszik, plusz az AGU tároló is kétszeresére nő, amihez az 50%-kal nagyobb elsőszintű adat gyorsítótár remekül jön.
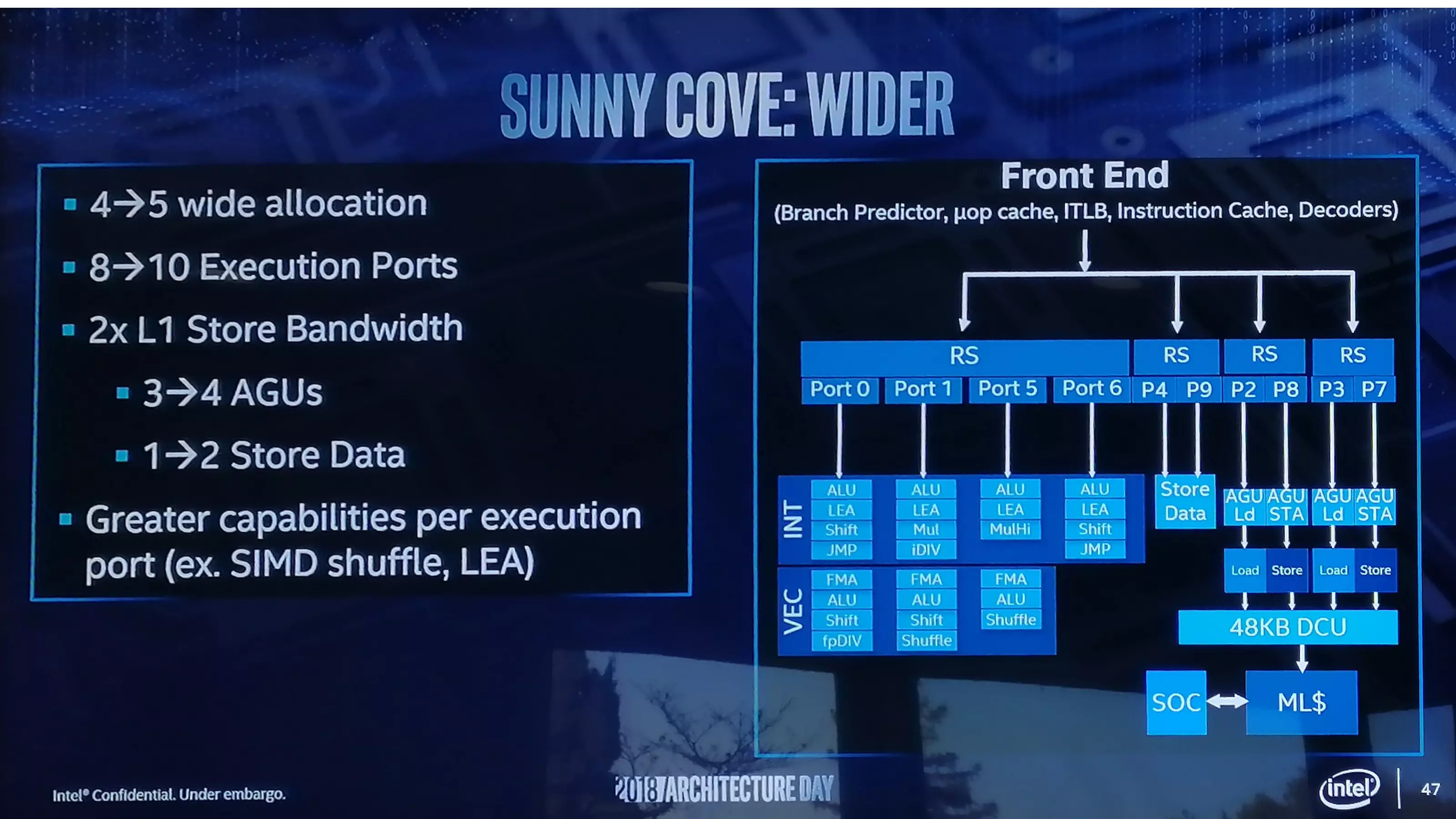
A mag integer részében a jelek szerint több LEA egység foglal helyet, mint eddig, amelyek segíthetnek a memóriacímzéssel kapcsolatos számítások elvégzésében, így lehetőség nyílik a korábbi biztonsági sebezhetőségek javítása okozta sűrűbb memória-számítások miatt elvesztett teljesítmény egy részének visszaszerzésére. Kiegyensúlyozás céljából a korábbi Port 5-ről a Port 1-re kerül egy MUL egység, plusz egy Integer Divider is kerül ide.
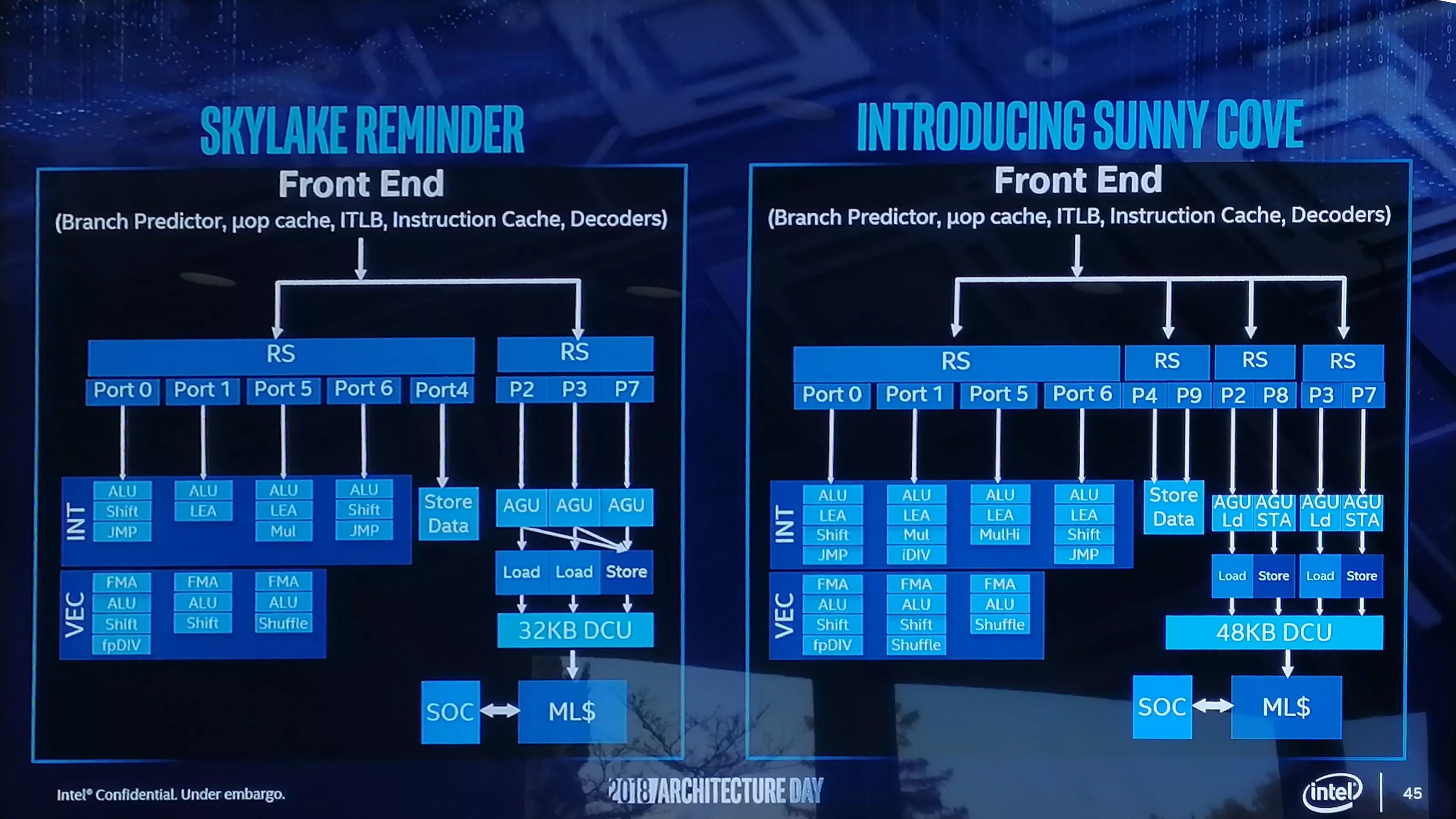
Az FP oldalon megnövelt Shuffle erőforrással találjuk szemben magunkat, amire egyes megrendelők miatt volt szükség, ezekkel ugyanis speciális kódjaik szűk keresztmetszete kiiktatható. Az FP részleg FMA egységeinek képességeit nem részletezte a gyártó, annyi viszont biztos, hogy a mag rendelkezik AVX-512 egységgel, vagyis legalább az egyik FMA kapcsolatban van vele. A Cannon Lake egyetlen 512-bites FMA-val rendelkezik, így valószínűleg ebben az esetben is ez a helyzet, a Xenon Scalable változatnál pedig kettő ilyen egységre számíthatunk, ha a feltevés helyes. A további frissítések között fejlettebb elágazásbecslő, illetve alacsonyabb effektív betöltési késleltetés szerepel, ami a TLB és az L1D bővítésének köszönhető.
Architektúra terén említést kell még tenni az új utasításkészletekről is, amelyek segítenek a speciális számítási feladatok gyorsításában, mint amilyenek a riptográfia, az MI számítások, stb.

A Sunny Cove esetében a memóriatámogatás is javul, azaz több rendszermemória kezelésére lesz mód. Ez annak köszönhető, hogy a rendszermemória laptáblája négy helyett öt rétegből áll, így a lineáris címtartomány 57-bitig, a fizikai címtartomány pedig 52-bitig terjed. Ez szerverprocesszorok terén azt jelenti, hogy foglalatonként elméletben akár 4 TB-nyi memória megcímezésére is lehetőség nyílik. A Sunny Cove alapú szerverprocesszorok, vagyis az Ice Lake-SP modellek 2020 ban érkeznek, amennyiben minden a korábbi Xeon útitervekben felvázolt forgatókönyv szerint zajlik.
Célkeresztben a Gen11 iGPU architektúra
Az aktuális Gen9.5 dizájn alapját adó Gen9-es architektúra még 2015 folyamán mutatkozott be. A Gen9.5 a Kaby Lake és a Coffe Lake sorozatú processzorok fedélzetén kapott helyet, majd a Gen10 következett volna a Cannon Lake érkezésével, ám eddig aktív iGPU-val szerelt Cannon Lake processzort még nem adott ki a gyártó – az eddigi Cannon Lake modellek mellé kényszerből AMD Radeon 540-es dGPU került.
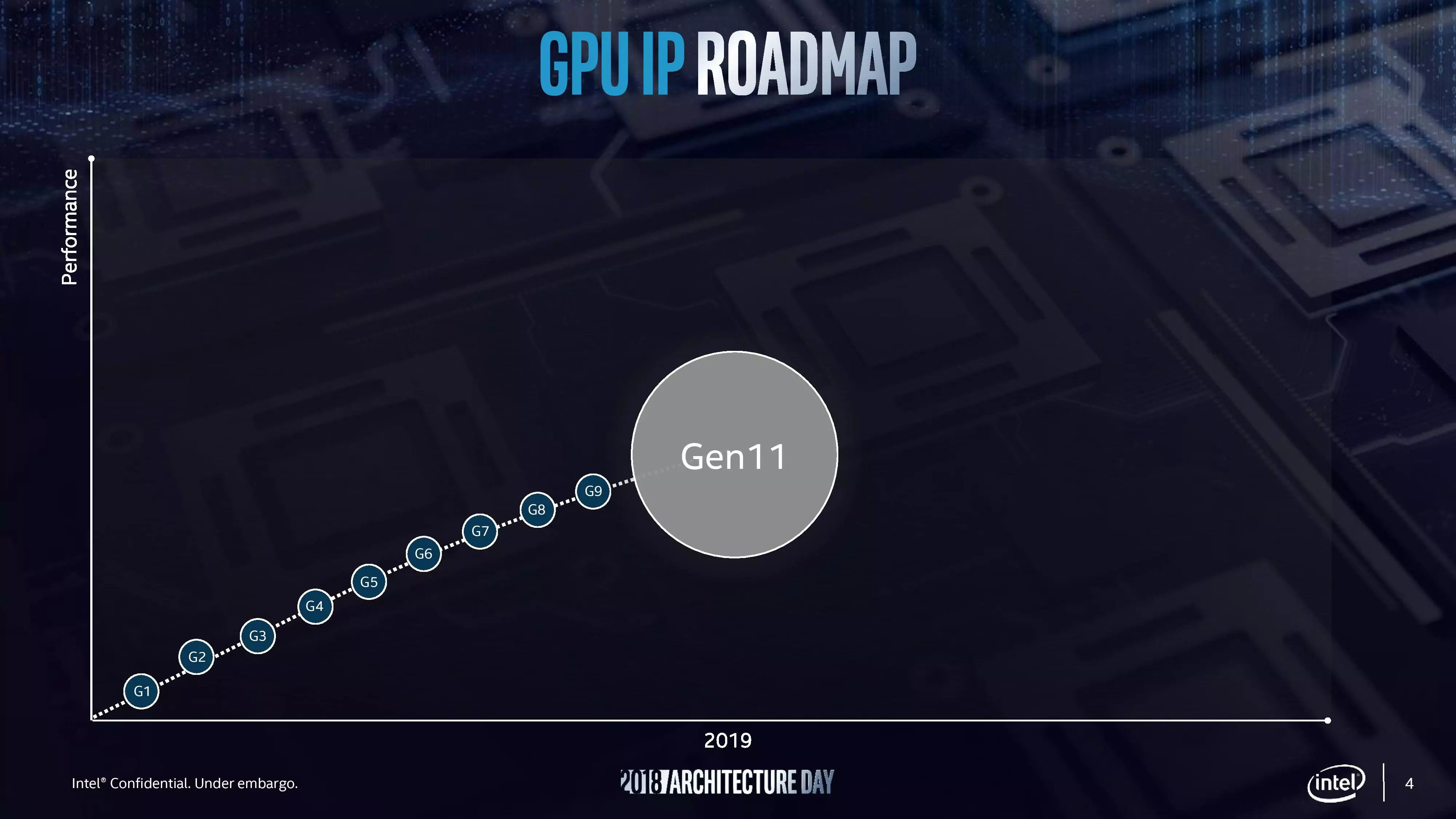
A fenti útiterven a rossz emlékek miatt a Gen10 eleve nem is szerepel, egyből a Gen11-re koncentrál a vállalat, ami az előző bekezdésben említett Sunny Cove processzormagokkal együtt juthat szerephez 2019 folyamán, 10 nm-es csíkszélesség mellett. Az Intel által kiadott diagram szerint – ami egy GT2 osztályú iGPU-t ábrázol –, a Gen11 alapú iGPU-k már nem 24, hanem 64 EU-t kapnak (Execution Unit). Ezt a 64 EU-t összesen négy csoportra bontják, tehát valószínűleg 16-osával lehet majd tiltani az EU-kat a gyengébb processzorokhoz.

Az információmorzsák alapján az FP16 támogatás megmarad, az egyes EU-k pedig továbbra is maximum hét szálon dolgozhatnak, mint most. Annak érdekében, hogy ezeket a futószalagokat megfelelő teljesítménnyel lehessen „etetni”, a gyártó a memória-alrendszert is átdolgozta egy kicsit: az L3 Cache a Gen9.5-ös megoldásokéhoz képest négyszeresére nőtt, azaz 3 MB-nyi lett, és most egy különálló blokkban foglal helyet a GPU unslice részlegében (jelenleg az EU-kat tartalmazó részeket hívja Slice-oknak az Intel, és mindent ami azokon kívül van, mint pl. a raszter egység, memóriavezérlő, stb. unslice-nak).

Az Intel végre a csempe alapú renderelést is bevezeti, ami az AMD-nél 2017-óta, az Nvidiánál pedig 2014 óta működik. Ez a szolgáltatást a GPU renderelés-menetenként engedélyezheti és tilthatja majd, szükség szerint. Az újítás az iGPU-k mellé kifejezetten jól jön, ugyanis remekül passzol az iGPU-kra jellemző memória-sávszélesség limithez, pontosabban segít jobban sáfárkodni a rendelkezésre álló erőforrással. Ezzel egy időben a veszteségmentes memória-tömörítést is fejlesztik, ami a legjobb forgatókönyv esetén akár 10%-os teljesítménynövekedést vagy 4%-os geometriai átlagnövekedést hozhat a konyhára. További jó hír, hogy a GTI csatoló innentől kezdve 64 bájtnyi olvasást és írást támogat órajelenként, ami remekül passzol a feljavított memória-alrendszerhez.
Bekerül a támogatott technológiák közé a Coarse Pixel Shading, ami az Nvidia Variable Pixel Shading technológiájára hasonlít. Ennek köszönhetően a GPU csökkentheti az árnyalási feladatokkal kapcsolatos munkát, mert nem feltétlenül kell a kép minden részén ugyanolyan részletesség mellett lefuttatni a shadereket – ha például távoli objektumokat kell renderelni akkor a szokásos 1:1 alapnál kevesebb munka elvégzése is elegendő, de ez a technológia akkor is jól jön, ha a képernyő közepétől távolabb esik a képpont, azaz akkor, ha nincs benne a közvetlen látószögben. Utóbbi főleg a VR tartalmak erőforrás-kímélő renderelését segíti. A technológia olyannyira hatékony, hogy ha csak 2x2 stencilt alkalmaznak, azaz négy pixelblokkra csak egy pixel-árnyékoló művelet jut, az aktuális FPS érték akár 30%-kal is növekedhet. Ezt a módszert persze játékonként kell optimalizálni és alkalmazni ahhoz, hogy a jelentős képminőség-romlás elkerülhető legyen, vagyis nem egy univerzális, azonnali megoldásról van szó, ami mindenre ráhúzható.


Szó esett a médiablokkról is: a Gen11 esetében egy új HEVC enkódert alkalmaznak, ami magas minőségű kódolásra és dekódolásra képes. Ezeket a médiára kihegyezett fix funkciós egységeket az adatközpontokban már használják különböző videófeldolgozási feladatokra, így hamarosan a felhasználók is profitálhatnak ugyanabból a hardverből. A párhuzamos dekóderek használatával lehetőség nyílik több videó stream egyidejű futtatására, de ezeket a dekódereket kombinálhatják is, hogy egy nagyobb, akár 8K-s felbontású streamet is kezelhessenek.

Kijelzőmotor frontján szóba került az Adaptive Sync támogatás, amit igazából már a Skylake rajtjakor bejelentettek, de most már végre készen is áll arra, hogy bevessék. Ehhez HDR támogatás is társul. Noha a prezentáció nem tartalmazza, az aktuális információk alapján úgy tűnik, hogy a Gen11-es iGPU mellé Tpye-C videó kimenet támogatás is érkezik, így a szükséges mux már integrálva érkezik, nem az alaplap dizájn részeként.
Előkerült egy Sunny Cove maggal és Gen11 iGPU-val ellátott Ice Lake-U chip
A fejlesztői alaplapban helyet foglaló központi egység egy 15 wattos TDP kerettel rendelkező megoldásnak tűnt, amelyen a bemutató alkalmával 7-Zip és Tekken 7 futott. Előbbivel az új utasításkészletek, mint például a Vector-AES és az SHA-NI előnyeit próbálták demonstrálni: egy azonos szintű Skylake alapú processzorhoz képest 75%-os teljesítménynövekedés jöhet össze azonos órajel mellett, ami azért nem kevés. Ez persze csak azoknál a feladatoknál tapasztalható, amelyek a speciális utasításkészleteket használni is tudják, vagyis nem általános felhasználásra vonatkozó teljesítménynövekedést takar ez a szám. Az azért ennél szerényebb lesz.

A 7-Zip mellett a Tekken 7 is előkerült, amelynek futtatása során a Sunny Cove + Gen11 alapú rendszer teljesítményét egy Skylake + Gen9 alapú konfigurációéhoz mérték. A látottak alapján az új rendszeren természetesen jobban futott a játék, mint a régin, igaz, azon még dolgozni kell, hogy a minimális FPS értékek ne essenek be 30 FPS alá.
Jön az XE dGPU/iGPU márkanév
Noha eddig zömében arról volt szó, mi várható 2019 folyamán, ennek a résznek a témája inkább a 2020-as évre vonatkozik, hiszen az Intel csak akkor lép be a dGPU piacra, ahogy azt már többször is elismerték. Az új GPU márkanevet maga Raja Koduri, az Intel dGPU részlegének vezetője jelentette be, aki nem is olyan régen még az AMD Radeon Technologies Group első embere volt. Az XE márkajelzés a hivatalosan még be nem jelentett Gen12 alapú megoldásokra vonatkozik, használata pedig 2020-ban indulhat meg. Ez a márkajelzés klienspiacra szánt megoldásoktól az adatközpontokba szánt speciális gyorsítókig minden területet lefed majd.
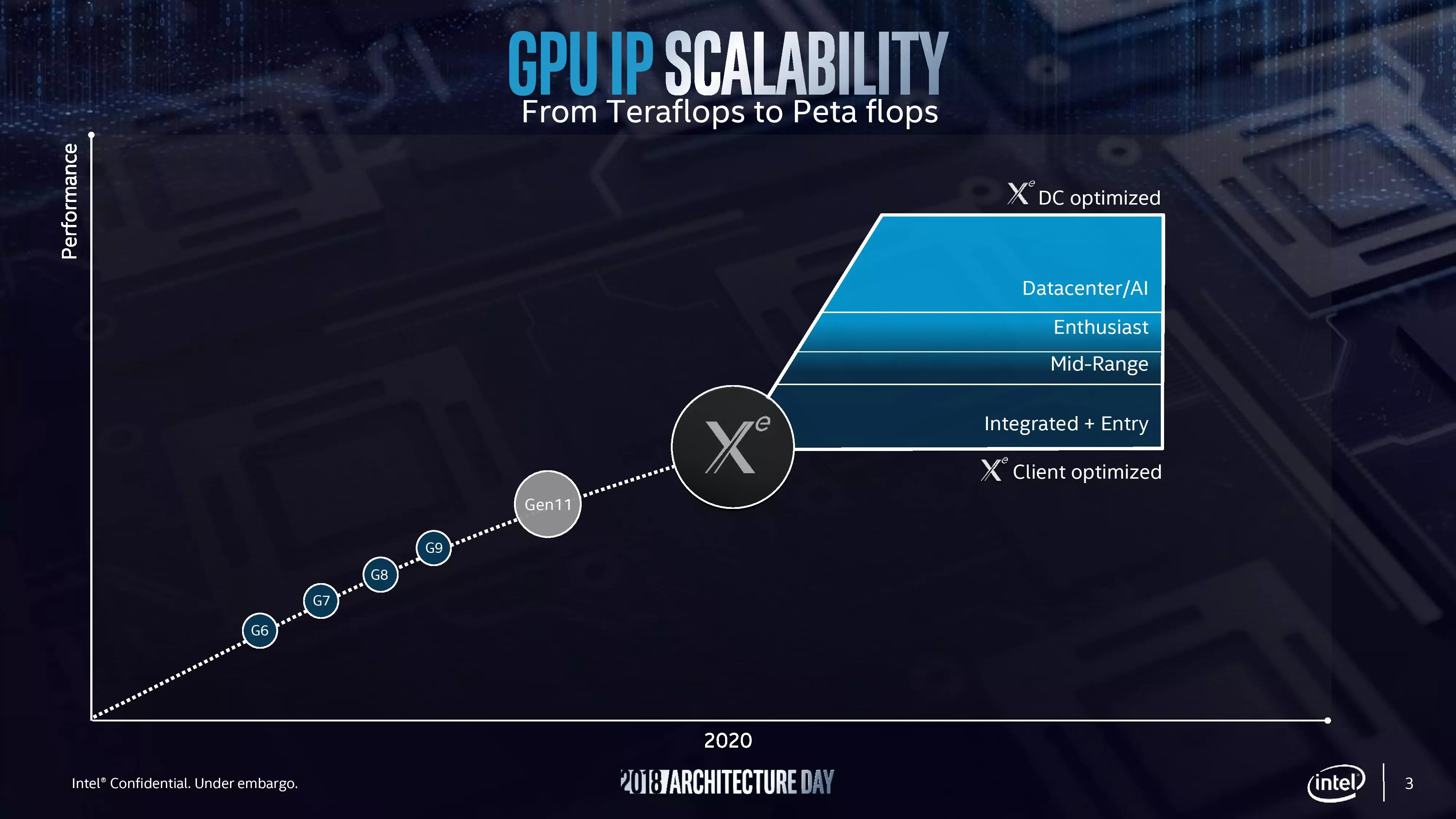
Az XEsorozatútermékek 10 nm-es gyártástechnológiával indulnak és a Single Stack Software filozófiát követik, vagyis a szoftverfejlesztők egyetlen API készleten keresztül aknázhatják majd ki a CPU, a GPU, az FPGA és az AI típusú gyorsítók előnyeit. Az XE jelölés több GPU generációt is lefed majd, azaz hosszú ideig velünk marad, az viszont még nem teljesen világos, hogy az XE jelölést az AI és az FPGA típusú megoldásokra is alkalmazzák-e.
Foveros: új módszer a 3D tokozás gyártásához

A Foveros esetében leegyszerűsítve arról van szó, hogy olyan interposert, vagyis köztes átvezető réteget hoznak létre, amellyel különféle lapkák kapcsolhatók egymáshoz egyetlen tokozáson belül. Az egyes lapkák eltérő gyártástechnológiát használnak – mindegyik olyat, ami az adott területhez a leginkább illik teljesítmény és költségek terén. A Foveros tulajdonképpen az EMIB továbbgondolása, ami a VEGA pGPU-val szerelt Kaby Lake-G soc egységekből már ismerős lehet. Ezúttal azonban nem csak egy egyszerű passzív interposert készítettek, hanem egy aktív változatot: maga az interposer nem csak a különböző lapkarétegek közötti összeköttetést biztosítja majd, hanem saját maga is tartalmaz egy-egy lapkát, például egy platformvezérlő hubot, vagy egyéb I/O vezérlőket. Az interposer tehát nem csak a tápellátást és az adatkapcsolatot biztosítja a fölé telepített lapkák számára, hanem működő lapkát is magában foglal, ami értékes hely megtakarítására ad módot (olyan, mint egy mini-alaplap, platformvezérlővel).

Az új gyártástechnológia első körben csak kevésbé bonyolult dizájnok építésére szolgál, vagyis néhány processzormagot integrálnak a PCH fölé. A konkrét példaegy 22FFL gyártástechnológia köré épülő interposerről szól, amelyre 10 nm-es csíkszélességgel készülő lapka kerül, néhány processzormaggal. Ezek fölé DRAM lapkákat integrálnak PoP (Package on Package) kivitelben.

A show alkalmával két olyan chipet mutatott a vállalat, amelyek már a Foveros technológiát használják. Ezek hibrid x86-os megoldások voltak, amelyeknél egy nagy Core sorozatú magot négy kisebb Atom sorozatú mag vett körül, amelyek mindannyian 10 nm-es csíkszélességgel készültek. A következő bekezdésben ezekről lesz szó.
Az Intel is a big.Little dizájn felé kacsintgat
A big.Little koncepció az ARM háza tájáról már ismerős lehet és igazából az Intel is próbálozott már hasonlóval, gondoljunk csak az Intel Edisonra, ahol ugyanarra a szilícium lapkára több különböző x86-os processzormag is került. A bemutatott lapka, amely a Foveros technológia segítségével készült, 12 x 12 milliméteres tokozással érkezett és egy 22FFL gyártástechnológiával készített I/O lapkát használt aktív interposerként. Ez az interposer aztán egy 10 nm-es lapkához csatlakozott a szokásos TSV-ken (Throug-Silicon-Vias), vagyis függőleges összekötőkön keresztül, amely egy Sunny Cove és négy Atom processzormagot tartalmazott – utóbbiak alighanem Tremont architektúra köré épültek. Az új lapka tehát meglehetősen kompakt, üresjárati teljesítményfelvétele pedig mindössze 2 milliwatt, vagyis ideális megoldás lehet mobileszközökben történő felhasználásra.

A demórendszer, amit meg lehetett tekinteni, hasonlított az előző Sunny Cove laphoz, igaz, itt a hűtőborda jelentősen kisebb volt és csatlakozók terén is mutatkozott néhány különbség. A fejlesztői alaplapban helyet foglaló lapka az Intel szerint PCIe M.2 és UFS támogatással egyaránt rendelkezik. Extra, hogy két SIM foglalat is lapult a deszkán.

A rendszerrel kapcsolatban egy diagram is felbukkant, amely szerint a nagy processzormag 0,5 MB-nyi köztes szintű gyorsítótárat kapott (MLC), a kisebb processzormagok pedig 1,5 MB-nyi megosztott másodszintű gyorsítótárhoz kapcsolódtak. Az uncore részleg egy 4 MB-os utolsó szintű gyorsítótárral, valamint egy négycsatornás (4 x 16-bites) memória-vezérlővel rendelkezett, ami LPDDR4-es memórialapkákat támogatott. Volt itt még 64 EU-val felvértezett Gen11-es iGPU,Gen 11.5-ös kijelző-vezérlő,egy új IPU, valamint MIPI DSI/CSI ésDisplayPort 1.4 támogatás is – mindez ebben az aprócska tokozásban.

A lapkán található processzormagok C6 alvó állapotba léphetnek, ha nincsenek használatban, TDP keret terén pedig 7 watt alatti értékekről beszélhetünk, amihez aktív hűtés sem feltétlenül szükséges. Az új lapkában komoly lehetőségek rejlenek, így ha sikerül vele megszólítania a piacot a vállalatnak, abból nagyon komoly bevételforrása származhat. Érdekesség, hogy az új lapka az egyik partner kérésére készül, aki 2 mW készenléti fogyasztás mellett dolgozó chipre vágyott, méghozzá a fentebb részletezett funkcionalitás és teljesítmény kíséretében.
Az Intelnél Jim Kellner szerint sokféle projektet próbálgatnak a Foveros technológiával, így sokféle különlegesség készül, hogy kiderüljön, mi az ami működik és miből lehetne igazán jó terméket gyártani. A Foveros alapú lapkák 2019 és 2020 folyamán kezdhetnek el szállingózni.
Lencsevégen egy 10 nm-es gyártástechnológiával készített Ice Lake Xeon CPU

Az Intel tervei szerint az üzleti piacot a Cascade Lake és a Cooper Lake sorozatú Xeon processzorok veszik majd célba a nem is oly távoli jövőben, amelyek 14 nm-es csíkszélességgel készülnek és az AI munkafolyamatokat is gyorsítani fogják, hála a különböző utasításkészleteknek. Ezek a processzorok biztonság terén is fejlődni fognak.
A két említett sorozat után következnek a 10 nm-es csíkszélességgel készülő Ice Lake Scalable modellek, amelyekről még mindig nem árult el semmi különöset a vállalat, de már megmutattak egy kész lapkát, ami arra utal, rendben haladnak a folyamatok a háttérben.

{kind=link}
{kind=link}