Az Nvidia a korábbi terveknek megfelelően megtartotta előadását a GTC 2022 alkalmával, ahol sok-sok érdekességről esett szó. Egyrészt bemutatkozott a Hopper architektúra, valamint a köré épülő első szerverpiaci gyorsítókártya, a H100 is, de ezzel együtt a Grace processzorról is szó esett, ami remekül kiegészíti az említett gyorsítókártyát – lényegében egymáshoz passzolnak.
Hopper – Több területen is óriási előrelépések
Az Nvidia legutóbb 2 esztendővel ezelőtt, ugyanúgy a GTC alkalmával mutatta be legutóbbi gyorsítókártyáját, az A100-as modellt, ami még az Ampere architektúra köré épült. Ebből a modellből óriási mennyiséget értéksítettek az elmúlt időszakban – csak az elmúlt esztendő során 10 milliárd dollár feletti árbevételt hozott a szerverpiacon az Nvidia számára.
Eljött viszont az idő arra, hogy az Ampere egy új architektúrának adja át a helyét a gyorsítókártyák szegmensében, ez pedig nem más, mint a Hopper, ami Grace Hopper után kapta a nevét. Grace Hopper egy matematikus volt, aki nem mellesleg a számítástudomány úttörőjeként vonult be a történelembe, még az első fordítóprogram is az ő nevéhez fűződik.

A Hopper architektúra köré egy igen érdekes gyorsítókártya, a H100 épül, amelynek alapját természetesen maga a GH100-as GPu adja. A kifejezetten számítási feladatok gyorsítására kifejlesztett architektúra a gépi tanulással, a mesterséges intelligenciával, illetve a neurális hálózatokkal kapcsolatos területekre érkezett. A köré épülő első gyorsítókártya igen masszív erőforrásokkal rendelkezik, főleg, ha az előző generációs A100-as gyorsítókártyát is mellé helyezzük.
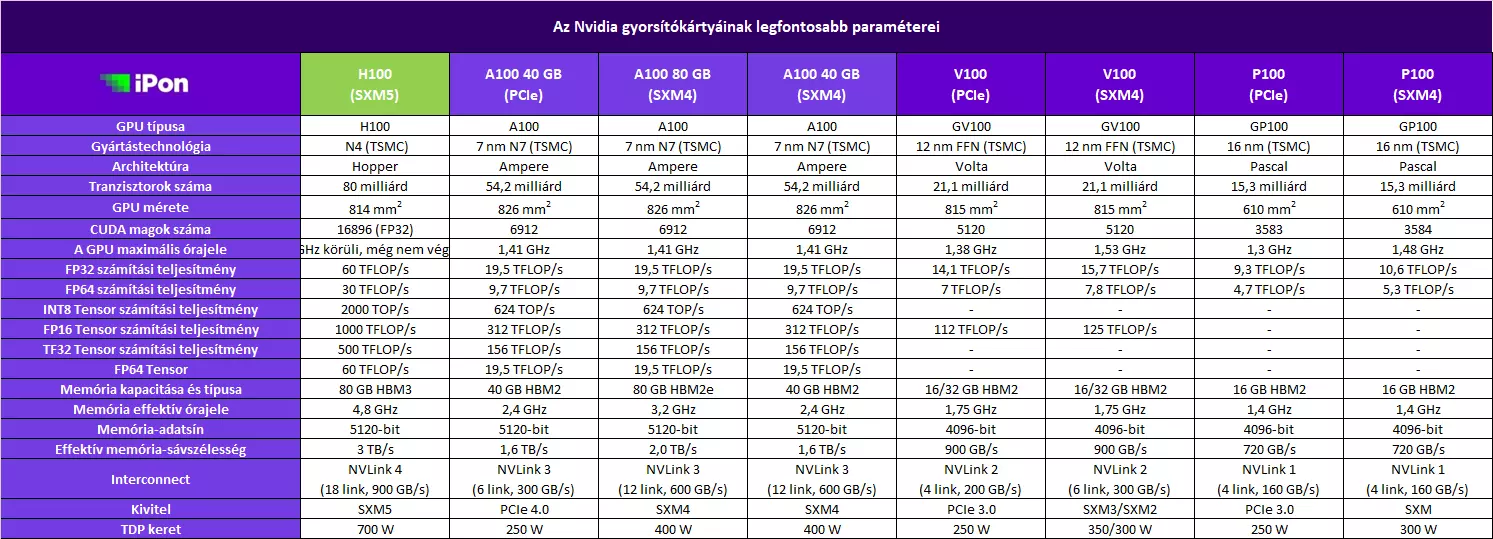
Alapok terén egy nagyjából 80 milliárd tranzisztorból épülő GPU-val van dolgunk, ami a TSMC 5 nm-es csíkszélességének optimalizált verzióját, az N4-et használja, annak is egy egyedi variánsát. Noha az A100-nál alkalmazott GA100-hoz képest egy teljes node-nyi és még egy pici váltás következett be, a tranzisztormennyiség jelentős növekedésének köszönhetően ez a GPU sem lett sokkal kisebb, mint az A100: míg előbbinél 826 négyzetmilliméteres, addig utóbbinál 814 négyzetmilliméteres kiterjedésről beszélhetünk.
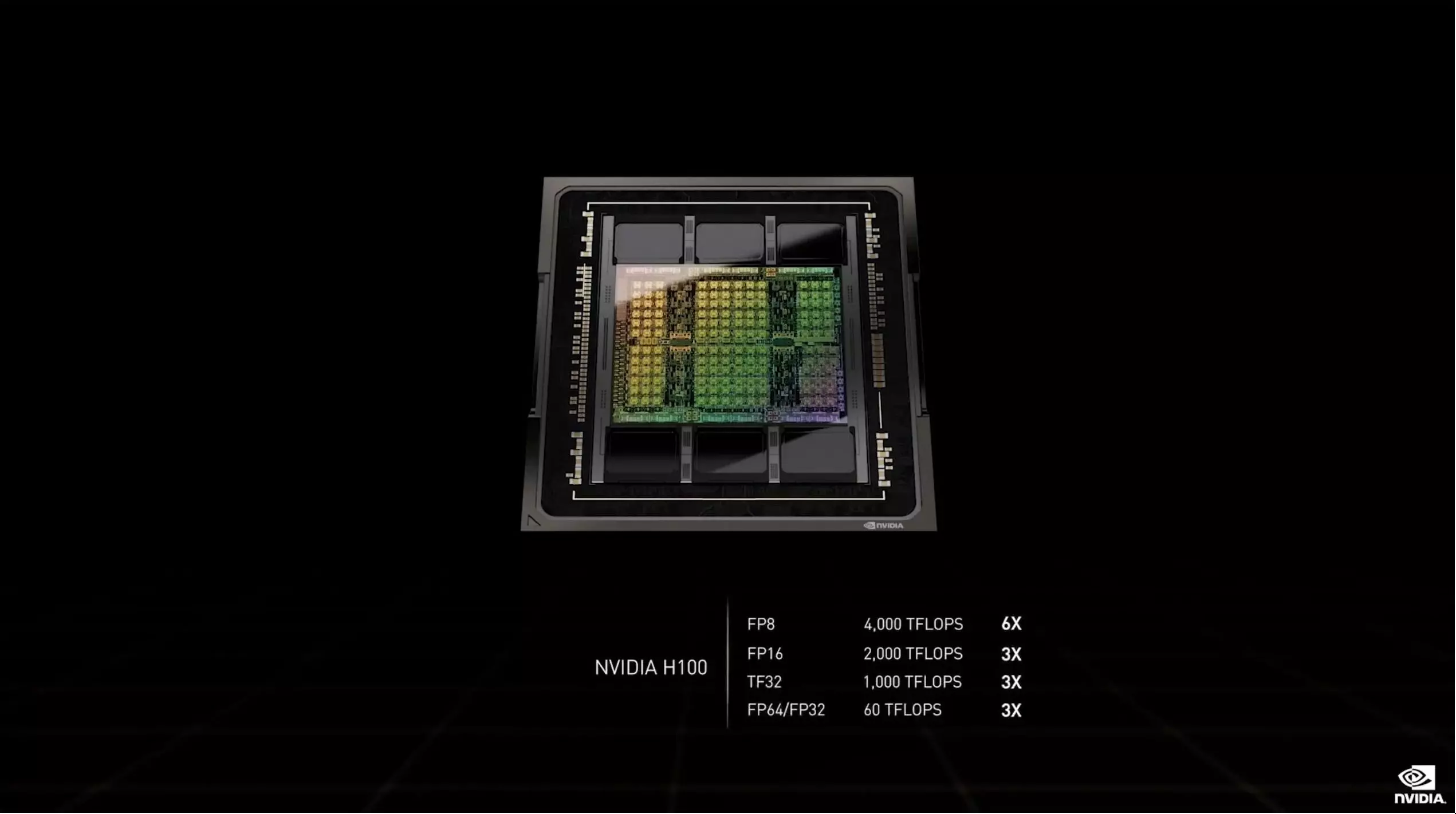
Az új GPU igen komoly gyorsulásokat hoz számítási teljesítmény terén, ahogy az a fentiekből is látszik, igaz, pontos felépítésével kapcsolatban egyelőre szűkszavúnak bizonyult az Nvidia, valamint igazából a várható teljesítménnyel kapcsolatban sem árultak el túl sok mindent. Annyi biztos, hogy az A100-as gyorsítóhoz képest a Tensor teljesítmény háromszor-hatszor nagyobb lehet, természetesen az aktuális formátumtól függően. A nyers elméleti maximális számítási teljesítmények óriási mértékben nőttek, de hogy ez a valóságban mekkora előnyt nyújt majd az egyes munkafolyamatok alkalmával, arról majd csak később hullhat le a lepel.
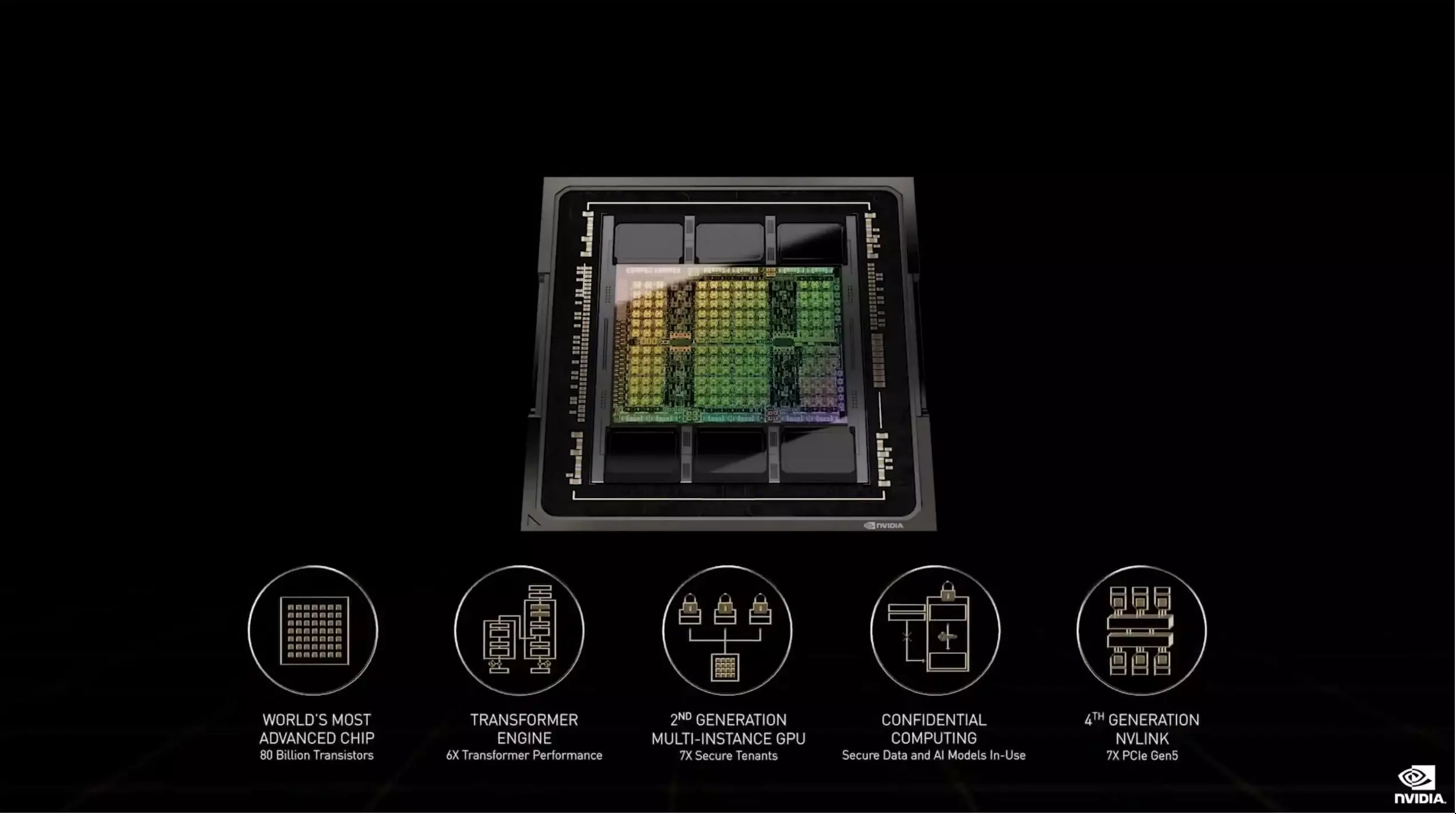
Az viszont már nem titok, hogy az új GPU elsőként használhat PCI Express 5.0-s sávokat, elsőként kap NVLink 4 támogatást, valamint elsőként használha HBM3-as fedélzeti memóriát is. Utóbbi az 5120-bites memória-adatsínen keresztül 3 TB/s-os maximális memória-sávszélességet kínál, ami 50%-kal több, mint amit az A100 esetében megszokhattunk. Belső felépítés tekintetében úgy jön össze a 80 GB-nyi HBM3-as fedélzeti memória, hogy hat darab 16 GB-os HBM3-as chipszendvicset helyeznek el a GPU-n, ám ezek közül az egyik le lesz tiltva, így 5120-bites adatsínnel számolhatunk, ami a fent említett memória-sávszélességet 4,8 Gbps-os effektív memória-sebesség mellett biztosítja.
Érdekesség, hogy maga a GH100-as GPU sem használhatja minden erőforrását, ám az nem derült ki, hogy a belső felépítés pontosan hogyan alakul, azaz hány SM tömb lesz, hogy néznek ki a gyorsítótárak, illetve sok egyéb területet is homály fed még.
Az viszont már nem titok, hogy a Hopper esetében speciális Tensor magok mutatkoznak be, amelyek Transformer Engine néven válnak ismertté- Ezek igazából olyan speciális Tensor magok, amelyek a gépi tanulással kapcsolatos munkafolyamatokat, pontosabban a transformereket tudják hatékonyan gyorsítani. Ezek speciális mélytanulási modellek, amelyek egyebek mellett a természetes nyelvek feldolgozásában és a számítógépes látás biztosításában jeleskednek. Lényegében arról van szó, hogy a Transformer Engine esetében lehetőség lesz a munkafolyamat számítási igényei alapján az FP16-os és az FP8-as formátumok közötti dinamikus váltásra.
Míg a hagyományos neurális hálózatokat fix pontosságú számításokkal tréningezik, addig az Nvidia újításánál a munkafolyamat igényeinek elemzésével lehetőség van arra, hogy FP16 helyett FP8-as pontosságot használjon a rendszer, ha ez lehetséges, így rögtön kétszer nagyobb teljesítmény mellett történhet a feladat végrehajtása. Ebben az esetben a Transformer Engine képes lesz a két számítási mód közötti váltásra minden egyes rétegnél, így azoknál, amelyekhez megfelel az FP8-as számítási pontosság, sokkal gyorsabban elkészülnek, mint a korábbi technológiákkal. Ez az előny egy több GPU-s rendszer esetében akár kilencszeres is lehet, így a nagyobb modellek sokkal hamarabb elkészülnek majd, ami sok új lehetőség előtt nyit kapukat.
A transformer dedukció esetében az Nvidia szerint a H100 az A100-hoz képest nem kisebb, mint 16x-os és 30x-os közötti gyorsulást emleget, ami igen komoly előrelépés, igaz, azt azért hozzá kell tenni, hogy két klasztert hasonlítanak össze, ahol a GPU-k mellett egyéb összetevők is nagy jelentőséggel bírnak, mind például a gyorsabb memória és a gyorsabb I/O is.
Ha már szóba került az I/O, érdemes említést tenni az NVLink összekötő legújabb verziójáról, az NVLink 4-ről is. Ez az összekötő eddig csak grafikus processzorok között teremtett kapcsolatot, de ahogy az rövidesen kiderül, processzorokat is össze tud majd kapcsolni a grafikus processzorokkal. Az új NVLink szabvány esetében érdekesség, hogy a jelátviteli ráta 50 Gbps-ról 100 Gbps-ra növekedett, linkeknként pedig 2 sávot biztosít a rendszer számára.
Az A100 esetében chipenként 12 link állt rendelkezésre, ami összesen 600 GB/s-os adatátviteli sávszélességet biztosított a chipek között. Ezzel szemben a H100 esetében már 18 link áll rendelkezésre, így összesen 900 GB/s-os adatátviteli sávszélességgel gazdálkodhatnak az egyes GPU-k. Ez gyakorlatilag 50%-os sávszélesség-növekedés, ahogy az NVLink 2 és az NVLink 3 között is ekkora volt az előrelépés mértéke.
Az NVLink technológiát nemcsak lapkák között, hanem hálózaton található GPU-k közötti is biztosítani lehet, ehhez külső NVLink Switch szükséges, ami összesen 256 GPU-t kapcsolhat össze egyetlen tartományba, azaz 32 darab 8 GPU-s rendszer foglalhat helyet egy ilyen „közösségben”, ahol a GPU-k közvetlenül kommunikálhatnak egymással.

Fontos még megemlíteni, hogy a Hopper H100 esetében elsőként PCI Express 5.0-s technológia is rendelkezésre áll, ami kétszeresére növeli a CPU és a GPU közötti adatátviteli sávszélességet, így hatékonyabban és gyorsabban juthatnak el az adatok egyik egységtől a másikhoz. Apró szépséghiba, hogy ezt a funkciót egyelőre egyetlen szerverpiaci fejlesztés sem támogatja hivatalosan, ugyanis a PCI Express 5.0-s támogatással ellátott szerverprocesszorok majd csak később érkeznek. Igazából ugyanez igaz a H100-ra is, hiszen majd csak a harmadik negyedév folyamán dobja piacra az Nvidia.
Az új GPU felhasználásával egy speciális bővítőkártya is készül, ami a H100 CNX nevet viseli. Ez igazából egy CX-7 SmartNIC lapkával kiegészített variáns, ami PCI Express 5.0-s csatolófelülethez kapcsolódik és közvetlenül képes a hálózathoz kapcsolni a GPU-t, így elkerülhetőek a sávszélesség-limittel kapcsolatos akadályok.

A H100-as gyorsítókártya ezúttal is kétféle kivitelben érkezik majd, azaz a nagyteljesítményű szerverekben SXM formátumú, míg a hagyományosabb szerverekben PCI Express bővítőkártya formátumú megoldással találkozhatunk. Az új GPU az extra erőforrásoknak köszönhetően igen komoly TDP növekedést eredményez majd mindkét formátum esetében, ez az SXM verziónál azt jelenti majd, hogy 700 W-os TDP-re kell készülni.
Ez a korábbi 400 W-os értékhez képest, amit az A100 esetében megszokhattunk, igen komoly növekedésnek minősül. És ezzel együtt a PCI Express 5.0-s bővítőkártyaként érkező verzió TDP kerete is növekszik, igaz, nem annyira extrém mértékben, hiszen 300 W-ról 350 W-ra emelkedik az érték – pont fele lesz az SXM verzióénak. Hogy ez mit jelent majd teljesítmény terén? Erre csak később kaphatunk választ.

Ha már fentebb szóba került az NVLink Switch, említést érdemel még a DGX sorozat legújabb fejlesztése, a DGX H100, amely természetesen H100-as SXM kártyákból épül fel. Az A100-as generáció esetében négy-, nyolc- és tizenhat-utas rendszereket egyaránt kínál az Nvidia, valószínűleg a H100 esetében is ez lesz a helyzet. A fentebb említett 256 GPU-s rendszer igazából egy DGX Pod, ami 32 darab 8 GPU-s DGX H100-as konfigurációból áll, de igény esetén ezek is összekapcsolhatóak egymással, viszont már nem NVLink Switch-csel, hanem Quantum-2 InfiBand alapon.

Az Nvidia hivatalos bemutatóján elhangzottak alapján utóbbiakból egy szuperszámítógép-fürt is épül, méghozzá szám szerint 18 darab DGX Podból, amelyek összesített FP16-os teljesítménye igencsak lebilincselő, 9 EFLOPS (ExaFlops) lesz. Lényegében ez, vagyis az EOS névre keresztelt szuperszámítógép-fürt lesz a világ leggyorsabb AI szuperszámítógépe.
Jön a Grace SoC is, ami remek párost alkot a Hopperrel
A másik lényeges fejlesztés a korábban már emlegetett Grace SoC egység lesz, ami igazából az adatközpontok szegmensét veszi célba, ahol az Nvidia szerint akár tízszer jobb teljesítményt nyújt majd, mint az x86-os alapokon nyugvó processzorok, ha HPC és AI terhelésformák futtatására kerül sor.

A Grace az Nvidia hivatalos tájékoztatása alapján következő generációs Arm v9 processzormagok köré épül, és két ilyen processzor alkot majd egy Grace Superchip névre keresztelt megoldást. Ez lényegében MCM alapokon nyugszik, ahol összesen 144 ARM v9 processzormag áll rendelkezésre – chipenként 72 –, a gyorsítótárak mérete pedig 396 MB lesz, ami chipenként 196 MB-nyi. A SuperChipek NVLink Chip-2-Chip kapcsolaton keresztül kommunikálnak.
A memória-alrendszer LPDDR5X szabványú lesz és 1 TB/s-os teljes memória-sávszélességet kínál – ez chipenként 500 GB/s-ot jelenthet. Egy teljes SuperChip modul – beleértve a memóriachipeket is – 500 W-os TDP vel rendelkezik. A Grace SuperChip az Nvidia szerint 1,5x gyorsabb, mint a legfrissebb 64-magos AMD EPYC szerverprocesszorból két darab a vállalat saját DGX A100-as szerverében, az energiahatékonyság pedig kétszer jobb, mint a vezető szerverpiaci processzoroké. Ez azért eléggé érdekesen hangzik, az első független tesztekre azonban még várni kell.

Az Nvidia egy Grace Hopper névre keresztelt MCM-et is készít, ami egy Grace processzorból (72 mag) és egy Hopper GPU-ból áll majd, ezek között természetesen NVLink C2C kapcsolat húzódik, amelynek sávszélessége 900 GB/s. Az NVLink kapcsolaton keresztül ráadásul memória-koherenciára is lesz mód, vagyis az LPDDR5X és a HBM3 fedélzeti memória ugyanazt a memória címtartományt használhatja, így egyszerűbb lesz a programozás. A Grace processzorok első kiadása BGA tokozással érkeznek majd, azaz alaplapra forrasztott kivitelben találkozhatunk velük, nem lesznek cserélhetőek, mint például egy x86-os szerverprocesszor.
A Grace igazából majd csak 2023 folyamán debütálhat, azaz még elég sok a kérdés vele kapcsolatban, hiszen a legfontosabb részleteket egyelőre féltve óvja a gyártó a kíváncsi szemek elől. Azt viszont elárulta a gyártó, milyen útitervvel készül a későbbiekben.
A terv szerint minden évben érkezik majd valami izgalmas fejlesztés: vagy GPU, vagy CPU, vagy pedig DPU. A pletykák szerint a Hopper esetében már a chiplet alapú GPU fejlesztése is zajlik a színfalak mögött, ami érdekes új lehetőségeket tartogathat.
A Grace természetesen szuperszámítógép-fürt formájában is debütál majd 2023 folyamán, ugyanis az Amerikai Energiaügyi Minisztérium Los Alamos National Laboratory részlegében a HPE jóvoltából készül egy Grace alapú szuperszámítógép-fürt, ám ennek pontos technikai részleteivel kapcsolatban egyelőre nem osztottak meg semmilyen lényeges információt a felek.
