
Már felsorolhatatlan mennyiségben léteznek generatív MI chatbotok, hiszen az olyan nagy fejlesztéseken túl, mint a ChatGPT, a Claude vagy a Gemini, rengeteg kisebb próbálkozás indult el az elmúlt években. Most éppen arról számolhatunk be, hogy már a Foxconn is színre lép ezen a fronton, ami némi meglepetést jelent.
A Foxconn a világ egyik legnagyobb bérgyártója, nála születnek az iPhone-ok, de egyebek mellett a Pixeleket is a tajvani cég állítja elő, és a végtelenségig lehetne még sorolni a kapcsolatait. A bérgyártás mellett pedig egy sor egyéb területen is aktív, és vannak érdekes fejlesztései. Ezúttal azt láthatjuk, hogy saját nagy nyelvi modellt is létrehozott, bár azt azért látni kell, hogy a FoxBrain elég erőteljes ágazati támogatással született meg.
Az új LLM alapjához a Meta biztosította az architektúrát, ami a fejlesztést jelentősen lerövidítette. A Llama 3.1-re építkezik a FoxBrain, annak is a 70 milliárd paraméteres verzióját alkalmazza, ami a leginkább kiegyensúlyozott a lehetőségek és a fenntartási költségek szempontjából. A tanitásban pedig az Nvidia segítette a Foxconn mérnöki gárdáját, és jelentős mennyiségű Nvidia H100 grafikus feldolgozó munkálkodik a szolgáltatás mögött.
A Foxconn beszámolója szerint ez az első olyan nyelvi modell, ami a tradicionális kínaira optimalizált, és egyben az első tajvani érvelési modell is.
A FoxBrain kapcsán még vannak nyitott kérdések, de azt megtudtuk, hogy már az érvelési modellek sorát gyarapítja. Ennek köszönhetően alkalmas az összetett feladatok, problémák megoldására. Jól vizsgázik a komplex logikai érvelési tesztekben és a matematikai feladványok levezetésében. Állítólag egy egyedi adaptív érvelési reflexiós technikát használtak a fejlesztők, ezáltal tudták azt megoldani, hogy autonóm érvelésben képzettebb legyen az LLM eszköz.
A tréningezés állítólag mindössze 4 hetet vett igénybe. Azt is megtudtuk, hogy ehhez a vállalat 24 különböző témakategóriában hozott létre 98 milliárd token mennyiségű, magas minőségű „pre-training” adatot tradicionális kínai nyelven. A FoxBrain 128 ezer tokenes kontextusablakkal üzemel majd, és a cég elmondása alapján minden vizsgált területen jobban fog teljesíteni ez a modell, mint az alapjául szolgáló Llama-3.1-70B. Viszont azt is elismerte a Foxconn, hogy a DeepSeek ellen ez még kevés, de így is rendkívül versenyképes a fejlesztés.
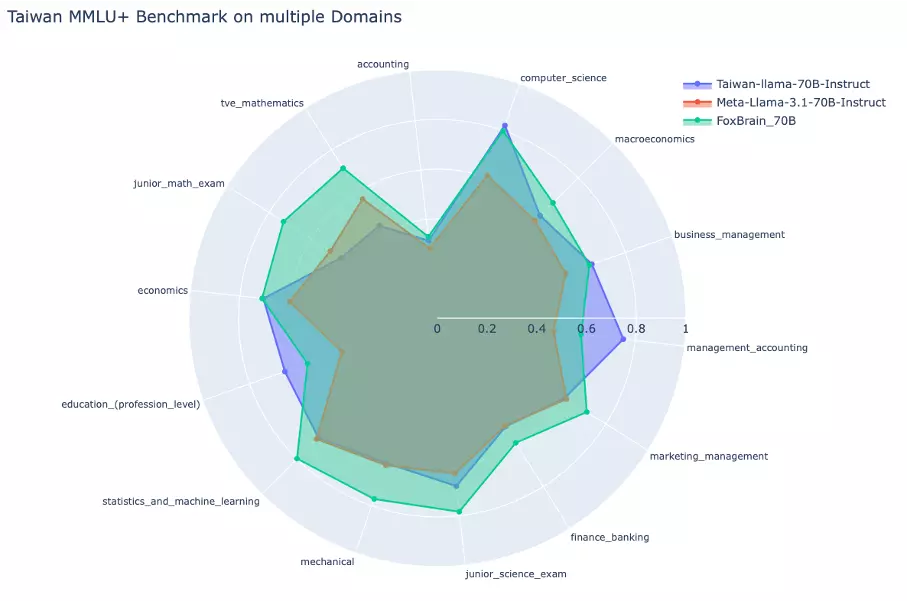
Eredetileg belső használatra készült a FoxBrain. A cég elmondása alapján adatok elemzésére, döntéshozatal támogatására, dokumentumok hatékonyabb kezelésére, programozók munkájának megsegítésére, összetett matematikai számítások megoldására, valamint problémamegoldásra tréningezték. A hétköznapi gyártással kapcsolatos feladatokban változatos módon alkalmazható, ráadásul nyúlt forrású, így rugalmasabban használható.
Most már az a Foxconn elképzelése, hogy elérhetővé fogja tenni a FoxBrain modellt a gyártópartnerek számára is. Nagy segítséget jelenthet ez a mesterséges intelligencia az ipari körülmények között, az ellátási lánc tagjai számára.
