A mesterséges intelligenciához kapcsolódó különböző munkafolyamatok kiszolgálása egyre nagyobb teljesítményű hardvereket kíván, ahogy a nagy nyelvi modellek egyre komplexebbé válnak, ez pedig azt eredményezi, hogy a számítási teljesítmény mellett a fogyasztás is jelentősen emelkedik, éppen ezért egyre nagyobb hangsúlyt kap az energiahatékony működés.
A Positron AI fejlesztése nemcsak teljesítmény terén minősül versenyképesnek a piacvezető Nvidia H200-as AI gyorsítókártyáival szemben, hanem energiahatékonyság terén is: nemcsak nagyobb teljesítményt kínál, mint az Nvidia szóban forgó termékei, de közben alig több, mint harmadannyi fogyasztás mellett végzi el a rá bízott feladatokat, ami alapján lehet félnivalója az Nvidia csapatának.

Azt persze fontos leszögezni, hogy a Positron AI Atlas sorozatú gyorsítója egy speciális ASIC, ami messze nem annyira sokoldalú, mint például egy Nvidia H200: csak egyetlen AI jellegű feladattípusra optimalizálták, ez pedig nem más, mint az AI Inference, azaz a dedukció, ami alatt viszont sokkal hatékonyabban működhet, mint az Nvidia terméke. A Positron AI egy viszonylag friss vállalat, ami 2023-ban alapult és azt tűzte ki zászlajára, hogy energiahatékony, nagy teljesítményű megoldásokat fejleszt és gyártat, amelyek egy speciális területre, az AI Inferenc világára koncentrálnak. Ennek megfelelően ezeket a gyorsítókat általános számítási feladatokra, tréningre, illetve egyéb munkafolyamatokra nem lehet használni, dedukció esetén viszont még az Nvidia Hopper architektúra köré épített H200-as megoldásait is alaposan lekörözik.
Az Atlas névre keresztelt megoldás lényegében nyolc darab Archer gyorsítókártyát tartalmaz, amelyek szorosan együttműködnek egymással a feladatvégzés folyamán Ezt a rendszert az Nvidia ugyancsak nyolcutas DGX szerverével mérték össze, amiben H200-as AI gyorsítók teljesítettek szolgálatot. A belsős tesztek szerint – amelyeket ezúttal is érdemes egészséges gyanakvással fogadni, ahogy az az efféle méréseknél lenni szokott – az Atlas a Llama 3.1 8B modellje alatt BF16 számítási módban 280 tokent generált másodpercenként és felhasználónként, míg az Nvidia H200 alapú DGX szervere ugyanilyen körülmények között csak 180 tokent tudott létrehozni. Ez jelentős teljesítménykülönbség, de a fogyasztáskülönbség még ennél is drámaibb: míg az Atlas 2000 W-ot igényelt a munka során, addig az Nvidia DGX szervere 5900 W-ps fogyasztást produkált.
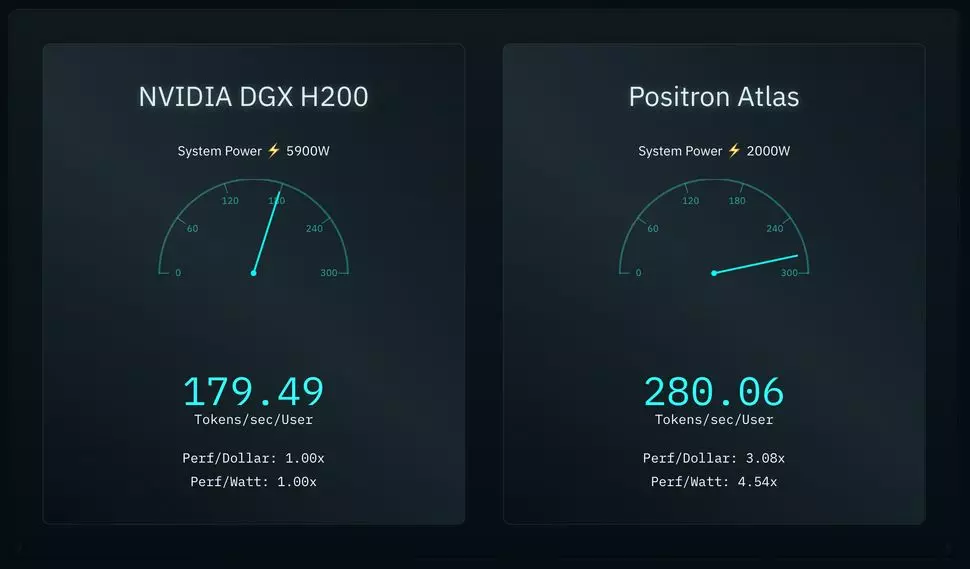
Az Atlas a fentiek alapján nemcsak gyorsabb, mint riválisa, de közel háromszor energiahatékonyabb is, ami igen-igen fontos szempont, és ár/teljesítmény hányados terén is sokkal jobb, mint az Nvidia megoldása. Ezeket az állításokat persze harmadik félnek, független tesztelőknek is igazolniuk kell, csak utána lehet őket tényként elfogadni.
Az Atlas gyorsító egy szinte teljesen amerikai terméknek tekinthető, hiszen fejlesztése és gyártásának egy része is az Amerikai Egyesül Államok területén történik. A speciális ASIC a TSMC Fab 21-es üzemében, Arizonában készül, ahol az N4 és az N5 gyártástechnológiák vannak használatban éppen. A lapka mellé 32 GB-nyj HBM memória is került, ennek megfelelően fejlett tokozási technológiát használ, ezért jó eséllyel Tajvanon szerelték össze.
Pozitívum, hogy az Atlas szerver és az Archer AI gyorsítók tökéletesen kompatibilisek a széles körben használt AI gyorsítók többségével, például a Hugging Face megoldásaival, valamint dedukciós kéréseket is képesek fogadni egy OpenAI API-kompatibilis végponton keresztül, így viszonylag egyszerűen integrálhatóak a meglévő munkafolyamatokban, lényegesebb változtatások szükségessége nélkül.

A Positron a háttérben már készíti a következő generációs hardverét is, ami Asimov AI gyorsítók köré épül és a Titan nevet viseli. Ez is nyolcutas rendszer lesz, azaz nyolc darab gyorsítókártyát tartalmaz, ellenfelei viszont már nem a Hopper vagy a Blackwell, hanem a Vera Rubin architektúra köré épülő Nvidia termékek lesznek. A Titan már akár 2 TB-nyi memóriát is kínálhat egy-egy ASIC számára, a rack rendszerekkel való kommunikációt pedig 16 Tb/s-os adatátviteli sávszélességű hálózat biztosíthatja.
Az új nyolcutas rendszerek akár 16 billió paraméterből álló LLM-ek futtatására is képesek lehetnek, és a rendszer arra is lehetőséget ad, hogy több modell is fusson egyidejűleg, vagyis eltörli az egy modell/GPU megkötést. A vállalat ígéretei szerint teljesítmény és ár/teljesítmény arány terén a Titan már ötször jobb lesz, mint az Nvidia Rubin alapú DGX szervere, ami igen-igen jól hangzik, már amennyiben ezt az állítást a valóság is visszaigazolja. A Titan várhatóan 2026 folyamán jelenik meg, ára pedig ugyanúgy 175 000 dollár lesz, mint a jelenleg is elérhető Atlas-é.
