
A Google szédületes tempót diktálva fejleszti a különböző nyelvi modelljeit és az azokra épülő generatív mesterséges intelligencia szolgáltatásokat. A cég szeretne ezen a területen az élre állni, de az OpenAI és a Microsoft együtt nagyon komoly versenytársnak bizonyul; éppen ezért a Google az utóbbi időben a fejlesztések minden lépéséről beszámol, hogy a lehető legtöbbször szerepeljen a híroldalakon ezzel a témával.
Most éppen arról adott hírt a vállalat a Cloud Next 2024 konferencia keretében, hogy a Gemini 1.5 Pro elért abba a szakaszba, hogy már a publikum is tesztelheti. A Vertex AI keretében lehet azt próbálgatni, hogy mire képes az új generációs modell, ami már egy új architektúrát (Mixture of Experts) használ annak érdekében, hogy hatékonyabb és pontosabb legyen, valamint akár 1 millió tokenes kontextusablak mellett is stabilan tudjon üzemelni, miközben eddig 128 ezer token jelentette a felső határt.

A Google csak decemberben jelentette be a Geminit, majd februárban már a Gemini 1.5-ről kezdett beszélni, és ennek a középső lépcsőfoka a Gemini 1.5 Pro, ami most elérhetővé vált egy szűkebb közönség számára. Állítólag már a Gemini 1.5 Pro is olyan erős lesz, hogy überelni fogja a Gemini 1.0 Ultra modellt, ami a jelenleg széles körben elérhető legnagyobb LLM rendszere a keresőóriásnak, és még a Gemini 1.5-ből is érkezik az Ultra változat. A Gemini 1.0 Ultra pillanatnyilag az előfizetéses Gemini Advanced szolgáltatáson keresztül érhető el.
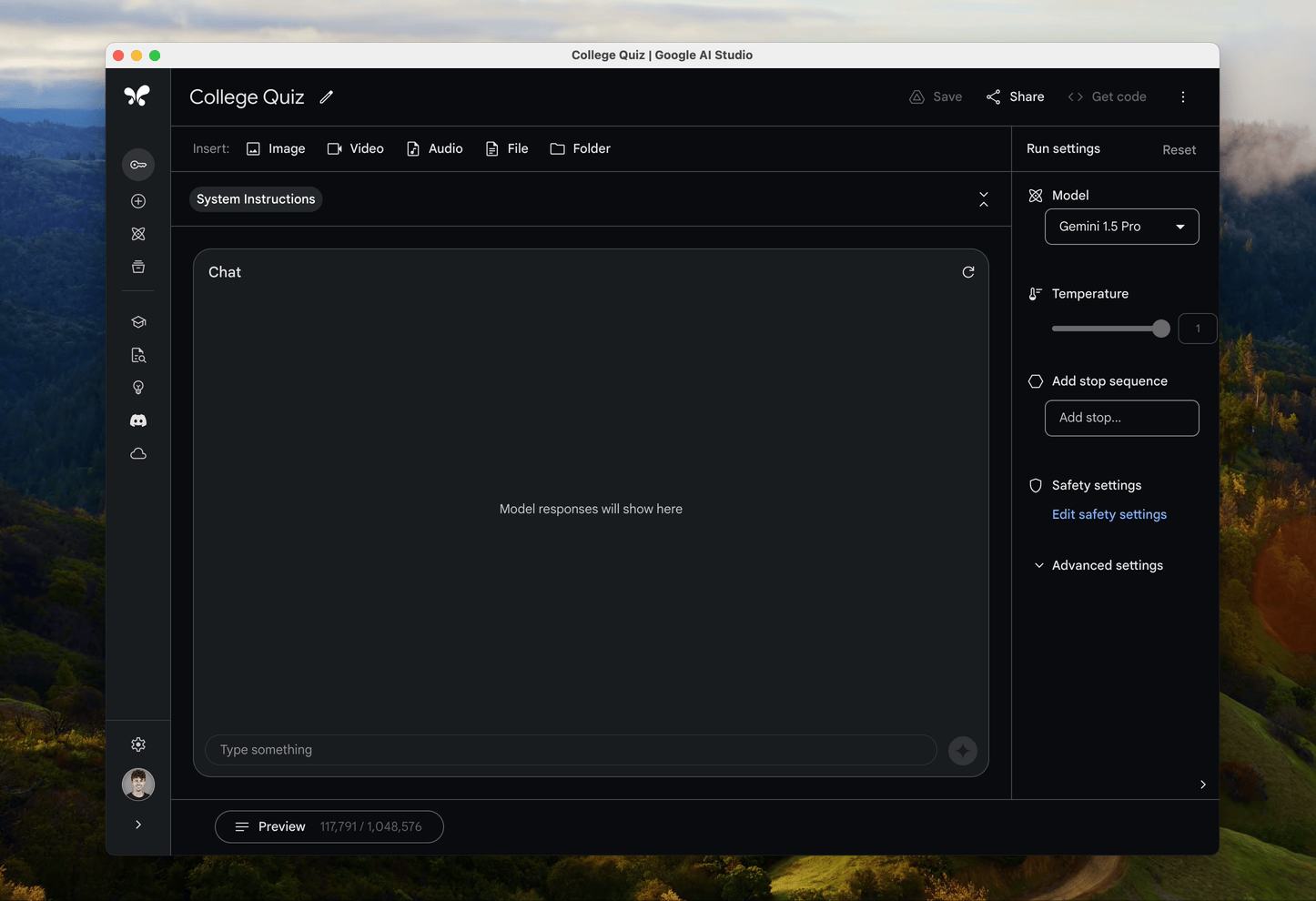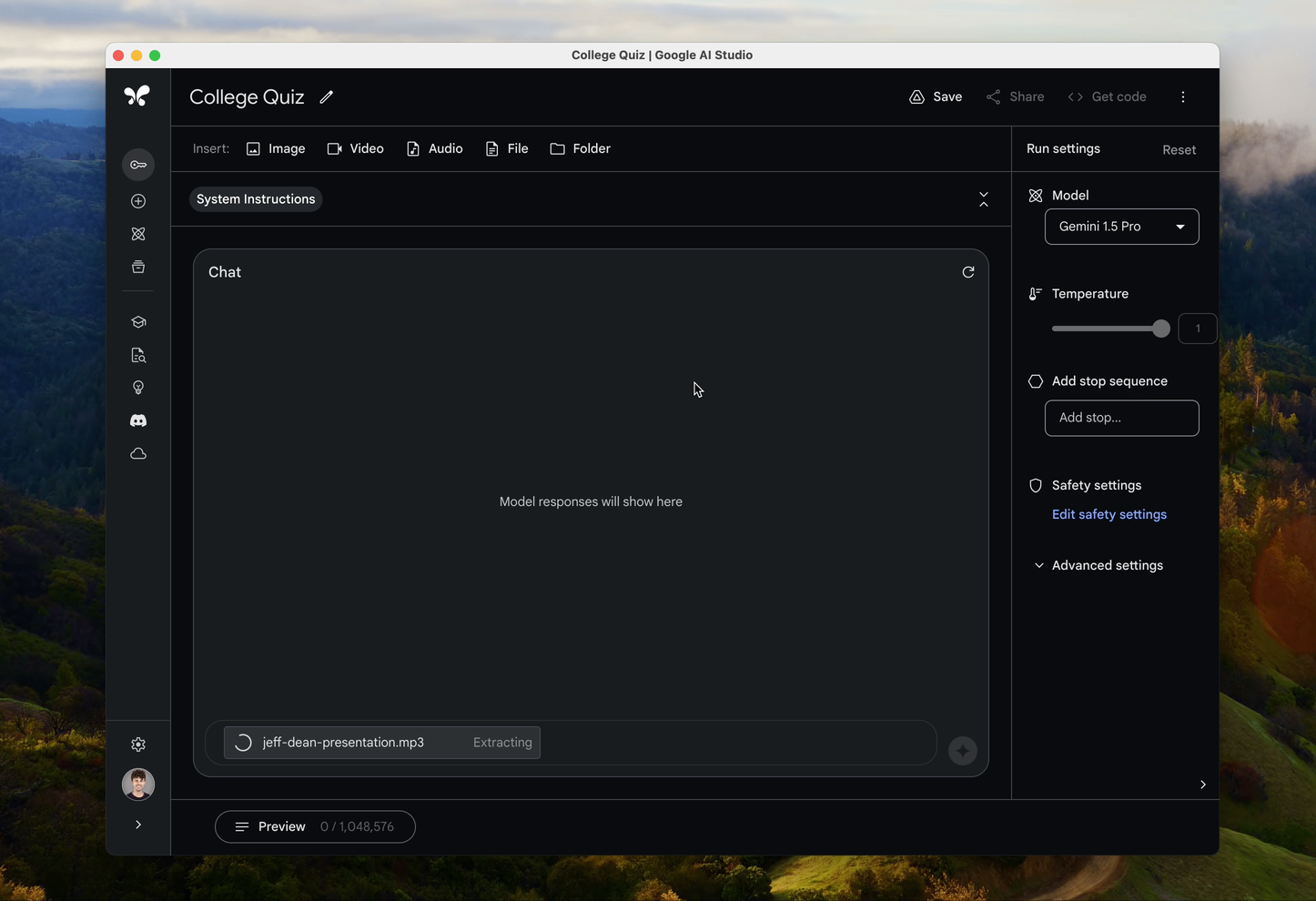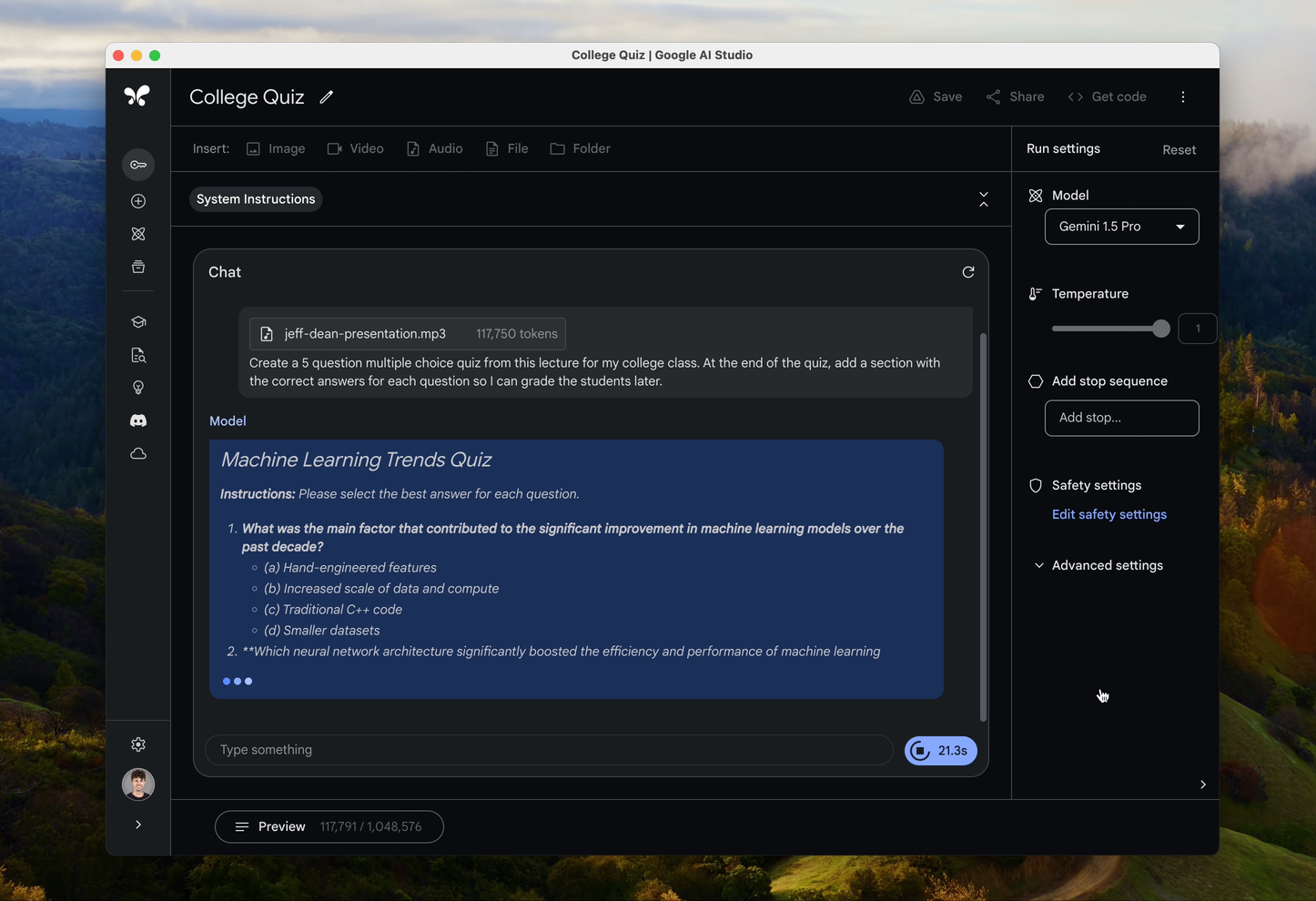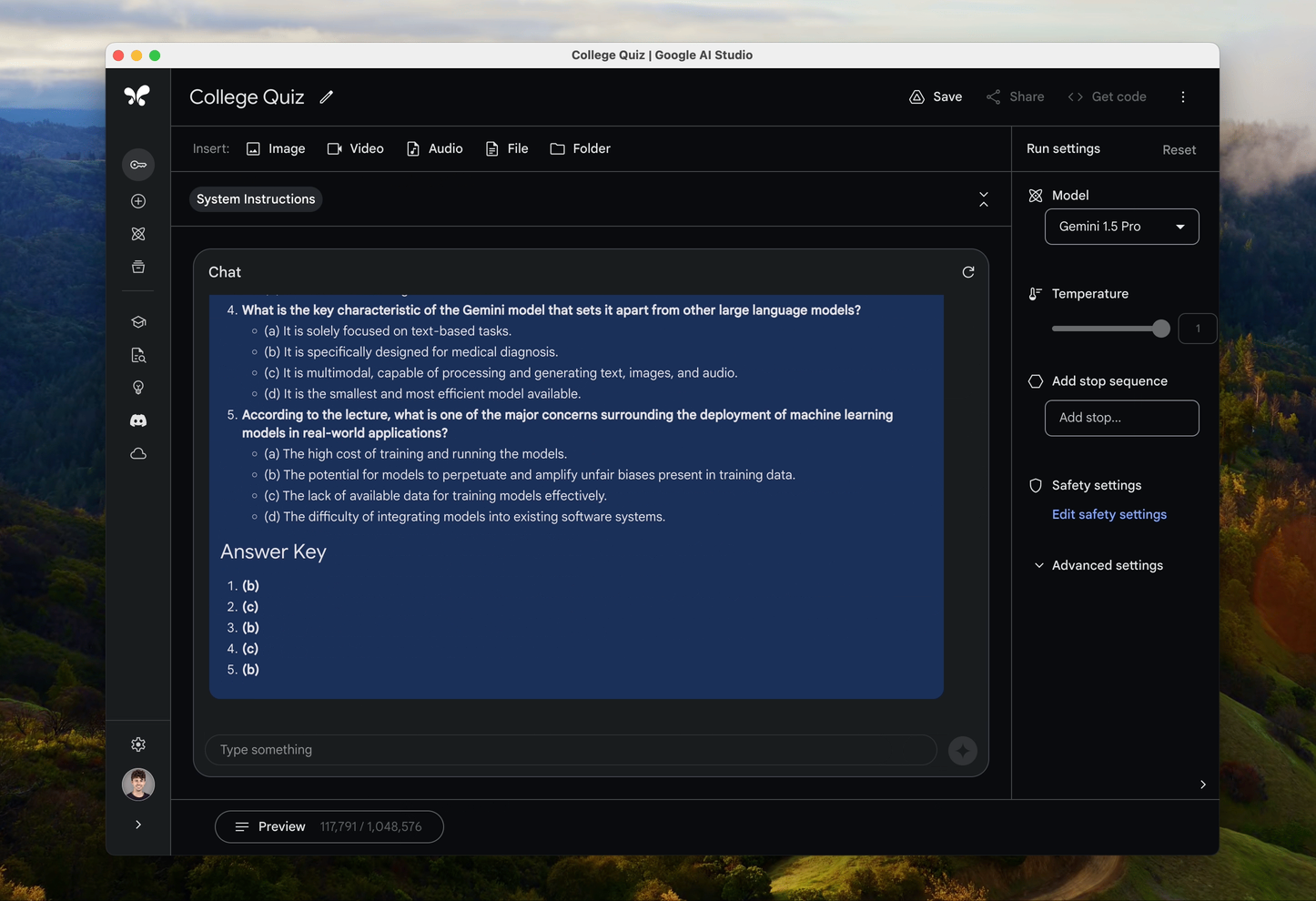
Korábban a Gemini 1.5 Pro kapcsán megtudtuk, hogy a szöveg mellett a képek és a videók feldolgozására is képes, és most ebbe a sorba megérkezett az audió tartalom is. Bejelentette a vállalat, hogy a továbbiakban képes lesz arra a nagy nyelvi modellje, hogy elemezzen, analizáljon különböző hangfelvételeket, és megértse azoknak a tartalmát is. Azt is meg tudja majd tenni, hogy különböző hanganyagokat hasonlítson össze, és természetesen ezen a téren is több nyelv támogatásával lehet majd számolni.
A fent említett 1 millió token hangmintákra lefordítva nagyjából 11 órányi folyamatos felvételt jelent, tehát a Gemini 1.5 Pro nyelvi modellt használó generatív MI technológiával csaknem fél napnyi folyamatosa beszélgetést lehet feldolgoztatni, és képes lesz ebből kérdéseket megválaszolni, esetleg egy összefoglalót írni, és így tovább. Ezzel az újítással egyszerűen lehet például videókat feliratozni, zenei klipekhez dalszöveget biztosítani, és így tovább.
Nem lenne meglepő, ha a jövőben a Google a legújabb Gemini modellt a YouTube mögött is bevetné, ugyanis azt kell tudni a YouTube és a mesterséges intelligencia viszonyáról, hogy a cég már korábban is egy olyan eszközt használt a hangfelismeréssel egybekötött feliratozásra, ami még fejlesztés alatt állt. Ebbe pedig nem is igazán szokott betekintést engedni a cég, így nem tudni, hogy most éppen mi a helyzeten ezen a fronton.
Azt elmondta a vállalat a Cloud Next eseményen, hogy a Gemini 1.5 Pro egyre több szolgáltatásba fog utat találni, és a tervek szerint például a Code Assist, programozást segítő generatív MI eszközénél biztosan képbe fog kerülni, hogy javítsa a teljesítményét minden szempontból. Programozásban állítólag hatalmas lesz a fejlődés az új modell megjelenésével, és a cég igyekszik is ezt azonnal kihasználni, hogy a felhasználók érdeklődését felkeltse.

A Google kitért még arra is, hogy az Imagen 2 névre hallgató text-to-image MI megoldása is szintet fog lépni. Már lesznek olyan funkciói, mint a belső kitöltés és a vászon kiszélesítése, így például már elemeket is el lehet majd távolítani a képekről, és azoknak a helyét teljesen feltűnésmentesen fogja kitölteni. Hasonló funkciókkal már a legtöbb képgeneráló bővült az utóbb időben, így nem meglepő, hogy a Google is ebbe az irányba indult el a fejlesztésekkel. Továbbá a Google is elkezdi a képeket vízjelezni az új SynthID használatával.
