
A Google a közelmúltban beszélt a legújabb „nyílt” modelljéről, amit egyetlen GPU-val is jó teljesítmény mellett lehet használni, A friss Gemma variánst követően pedig most itt egy újabb Gemini.
Ezúttal már a Gemini 2.5-ről számolhatunk be, ami egy nagyobb nyelvi modell családot takar, ezen belül lesz több különböző megoldás.
Elsőként a Google a Gemini 2.5 Pro modellt leplezte le, ez lesz az egyik legjobb képességű opció a Gemini 2.5 égisze alatt. Egyelőre csak kísérleti verzióban fut, de már kiváló eredményeket tud felmutatni. Büszkén emelte ki a keresőóriás, hogy a Gemini 2.5 Pro Experimental a legtöbb népszerű tesztprogramban, az esetek túlnyomó többségében vezető helyen áll. A LMArena első helyét is kivívta magának az új modell.
Egy érvelő modellről beszélhetünk, és nem ez az első eset, hogy a Google ilyennel áll elő. A Gemini 2.0-nál jobb lesz az újdonság teljesítménye és pontossága is. Hatékonyabban dolgozhatnak majd vele a felhasználók, programozásban is új mércét állít fel, és valóban intelligensebb válaszokkal képes szolgálnia a korábbi eszközöknél. A Google már többféle eljárást egyszerre alkalmazva tanítja a modelljeit, hogy azok még jobbak legyenek. Ezúttal már egy szignifikánsan továbbfejlesztett alapmodellt ötvözött a cég fejlettebb post-traininggel.
A vállalat célja, hogy a kiemelkedő évelési lehetőségeket idővel minden modellbe integrálja, hogy azok képesek legyenek kezelni az egyre komplexebb problémákat is, és lehetővé tegyék a jobb képességű, tartalomérzékeny MI ügynökök létrehozását.
A Gemini 2.5 Pro Experimental elsőként a Google AI Studio keretében próbálható ki, illetve már benne van a Gemini alkalmazásban is, de nem mindenki számára érhető el. A Google úgy döntött, hogy egyelőre csak a Gemini Advanced előfizetőknek ad hozzáférést. Nem lenne meglepő, ha rövid időn belül megjelenne az ingyenes Gemini opciók között is, miközben már úton van a Vertex AI elérés is.
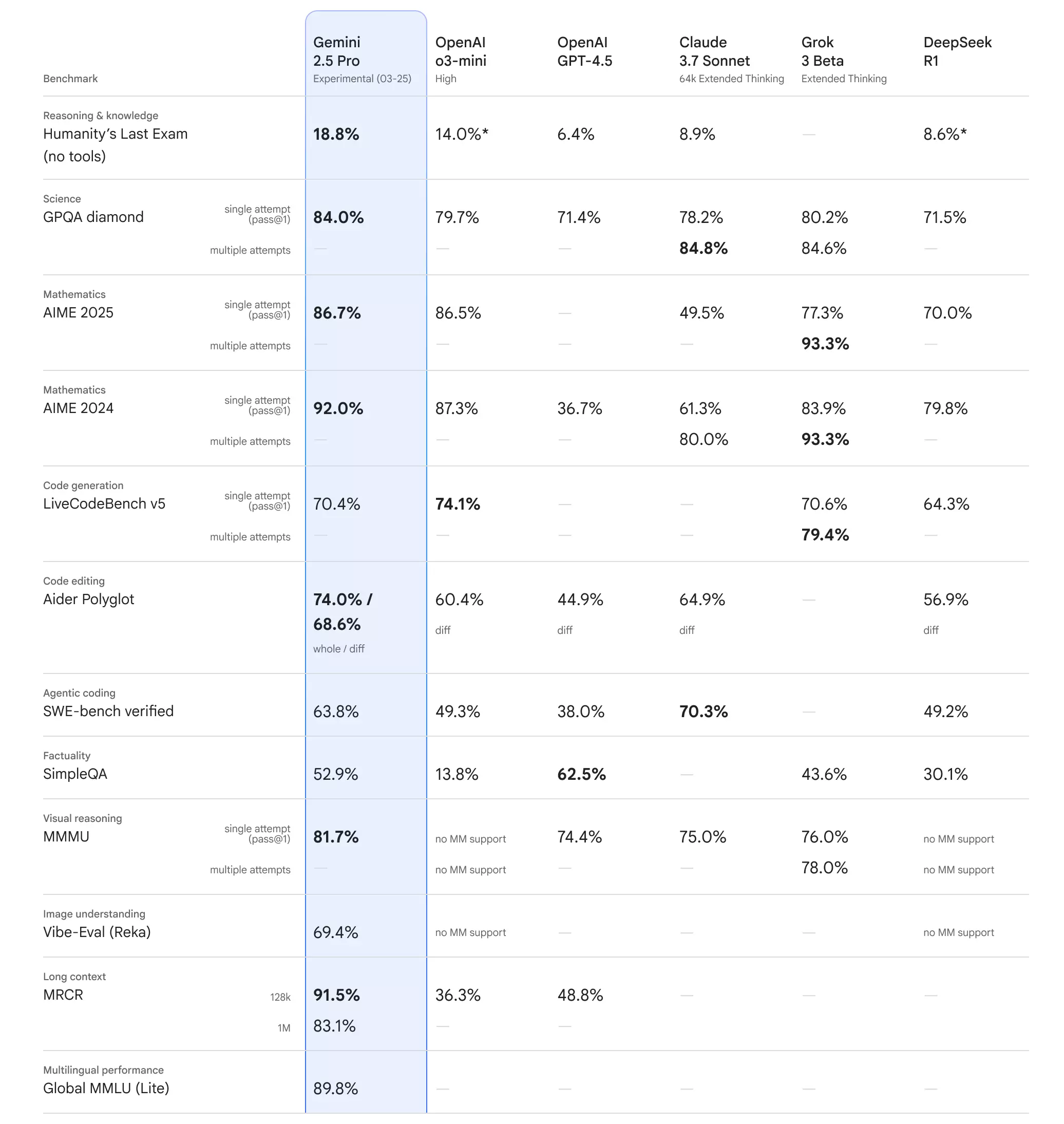
Az érvelési feladatok a mesterséges intelligenciának egyre jobban mennek, de azért vannak olyan tesztek, melyekben bőven van hova fejlődnie ezeknek. A „Humanity’s Last Exam” az egyik legnehezebb teszt, amivel a generatív MI eszközök képességeit szokták felmérni. A Google pedig sikeresen összehozott ebben is egy kiválónak tekinthető 18,8%-os eredményt. Az OpenAI o3-mini modellje ebben csak 14%-ot tud, a Claude 3.7 Sonnet pedig csak 8,9%-ra képes, a DeepSeek R1 pedig még ettől is elmarad 8,6%-kal. Ebben a tesztben már több ezer feladatot kell megoldani, részben multimodális kérdéseket megválaszolva.
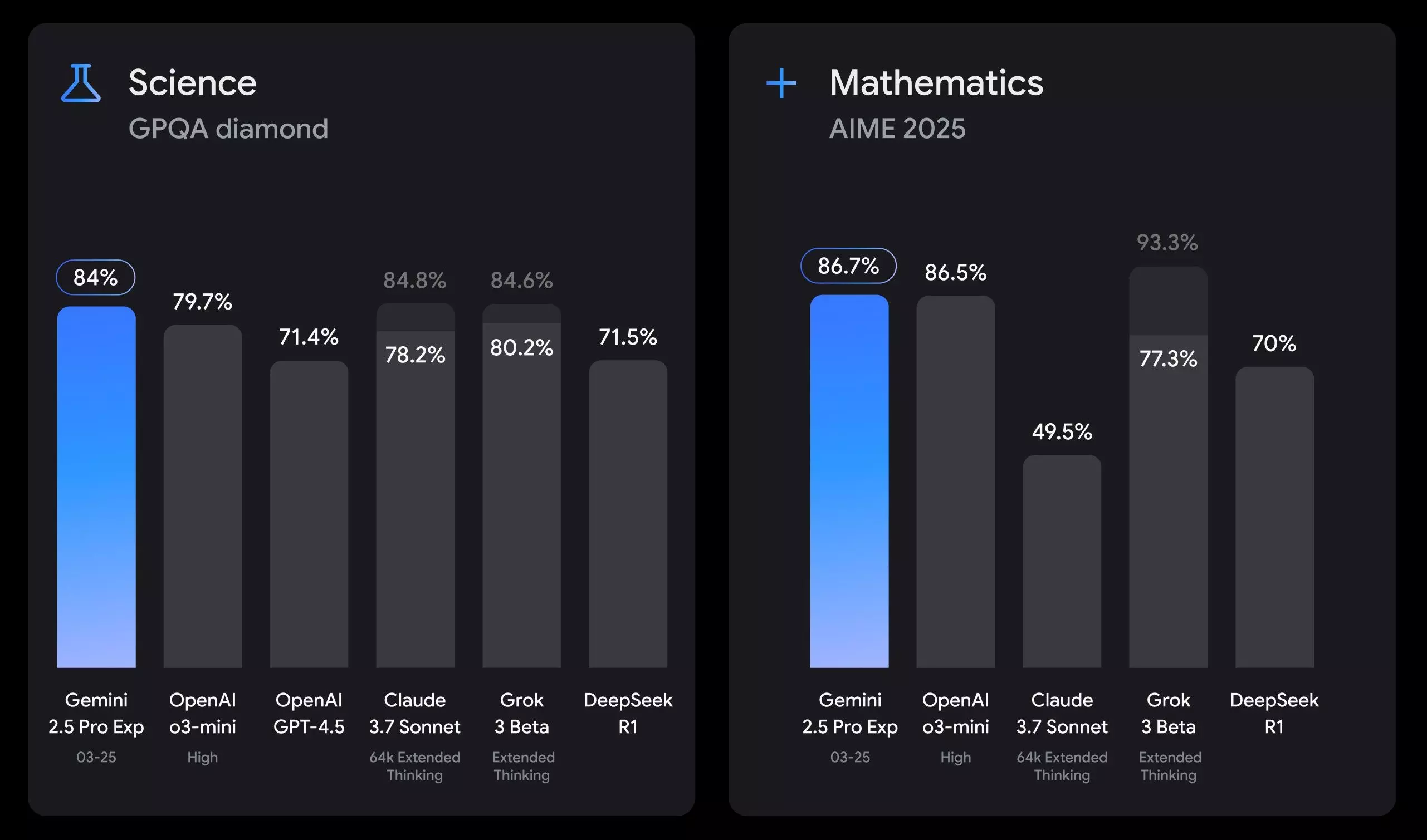
Programozásra nagyon sokan használják a mesterséges intelligencia szolgáltatásokat, a Google ezt pontosan tudja, és éppen ezért különöse figyel arra, hogy ezen a téren a Gemini jól tudjon teljesíteni. A Gemini 2.5 Pro kísérleti verziója kiválóan alkalmas vizuálisan kiemelkedő webes alkalmazások létrehozására, valamint meglévő kódok átalakításra, szerkesztésre. A széles körben alkalmazott SWE-Bench Verified megmérettetésen 63,8%-os eredményt ért el egyedi beállításokkal, ami rendkívül jónak számít, ha nem is páratlan teljesítmény.
A Gemini 2.5 az alapoktól multimodálisra tervezett, 1 millió tokenes kontextusablakot használ, de nem fognak itt megállni a tervezők, már szerepel az elképzelések között ennek a bővítése. A jövőben a kontextusablak 2 millió tokenesre lesz bővítve. Annak ellenére, hogy a Google a mostani modellel új magasságokba ért, már megvannak a tervei arra, hogy milyen területeken jönnek a következő fejlesztések.
