A mesterséges intelligencia egy csodálatos dolog, de a sok pozitívuma mellett rengeteg gond is van vele. Az egyik probléma, ami rendszeresen előkerül, hogy a különböző modelleket és szolgáltatásokat az esetek túlnyomó többségében lopott adatokkal tanítják be. Ez elsőre erősnek hangozhat, de pontosan erről van szó, hiszen a tartalmakat előállítóknak egyáltalán nincs tudomása arról, hogy mi folyik a háttérben, és engedélyt általában senkitől nem kérnek ehhez.
Rengeteg különböző vizsgálat indult már annak kapcsán, hogyan élnek vissza a mesterséges intelligencia fejlesztők az internetről összeszedhető adatokkal. Most a Wired és a Proof News egy közös publikációjában azzal foglalkozott, hogy a nagy technológiai szereplők miként éltek vissza YouTube videók tartalmaival a szolgáltatásaik javítása érdekében. Sokan csinálják azt, hogy YouTube-ról lekapart adatokat használnak fel tréningezésre, és erre szeretnének rámutatni az elemzők. Viszont nincs új a nap alatt, ezt már hosszú ideje lehet tudni igazából, csak most egy újabb bizonyítást nyert a sötét tevékenység.
A YouTube egy aranybánya az adatok szempontjából, és ezzel már eddig is sokan éltek vissza, a jövőben pedig ez csak még jellemzőbb lehet. A mostani vizsgálat során bizonyítást nyert, hogy az Anthropic, az Nvidia, az Apple, és még a Salesforce is felhasználta azt az adatcsomagot, amire ezúttal fókuszáltak a vizsgálat keretében.
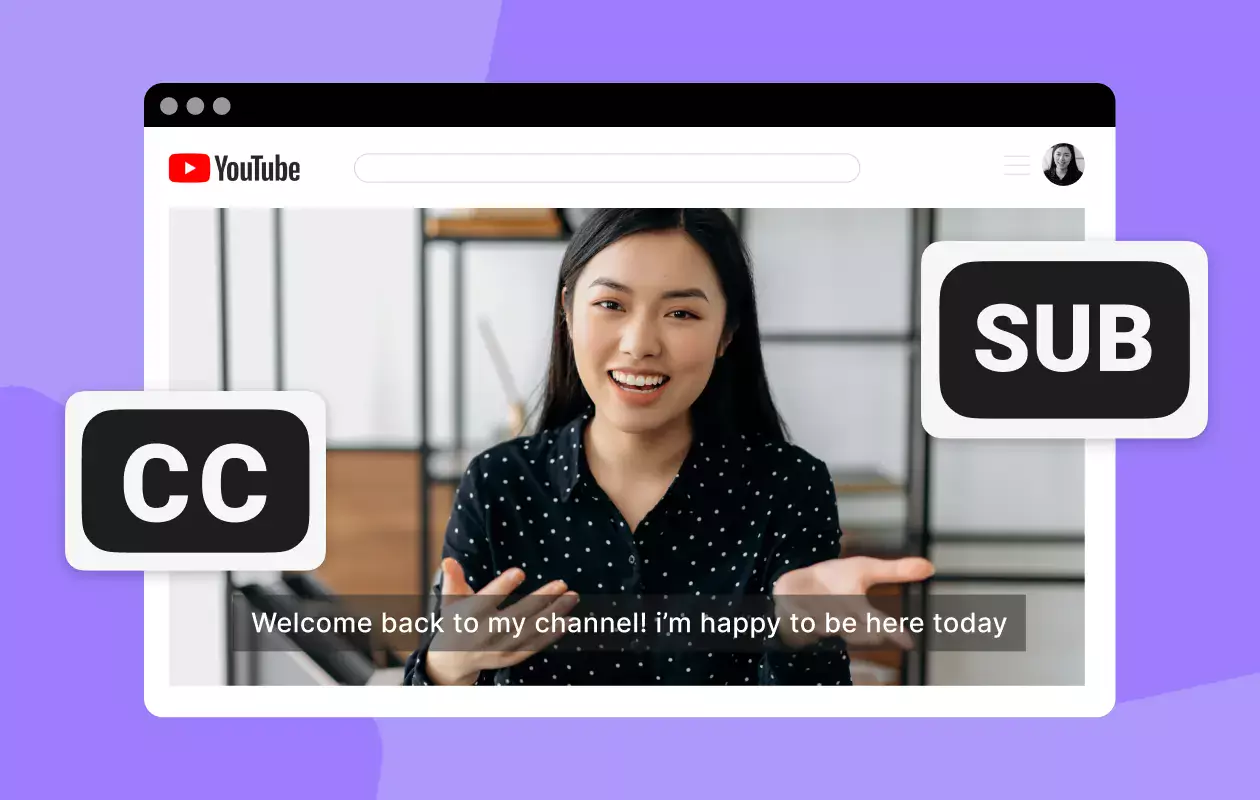
Egy olyan adatcsomagról van szó, ami több mint 48 ezer YouTube csatorna anyagait dolgozza fel, a képek, videók nincsenek benne az adatcsomagban, hanem csak a videók alatt elhangzó szövegek leíratát tartalmazzák. A YouTube videóknál már hosszú ideje elérhető a feliratozási lehetőség, és ezeknek az anyagát gyűjtötték össze a tréningezéshez. A chatbotoknak ez kiváló tanulási alapanyagot jelent, mert a természetes nyelvi készségeik fejlesztéséhez a videókban elhangzó szövegek éppen ideálisak.
173 536 YouTube videóból származtatott feliratot tartalmazott az a gyűjtemény, amit a Proof News fedezett fel a kutatásai során. Az Apple, az Nvidia és mások ezt használték fel a betanításhoz.
A lehető legváltozatosabb videókból származó adatok vannak ebben a nyilvánosságra hozott adatok szerint. Oktató, szórakoztató ismeretterjesztő videók anyagai egyaránt nagy mennyiségben vannak jelen az adatcsomagban. Az pedig egyértelmű, hogy ez a gyűjtemény egyszerűen nem is létezhetne, a YouTube szabályzata ugyanis egyértelműen tiltja azt, hogy az adatokat kinyerjék és összegyűjtsék a szolgáltatásból.
5,7 GB-nyi nyersanyagról beszélünk, ami elsőre egyáltalán nem hangzik szoknak, de látni kell azt, hogy kizárólag szöveges tartalomból jön ez össze. 489 millió szóból áll az adatcsomag, és prominens youtuberektől származó anyagok is a részét képezik ennek. MrBeast, Marques Brownlee, Jacksepticeye és mások mellett PewDiePie is érintett ebben az ügyben.
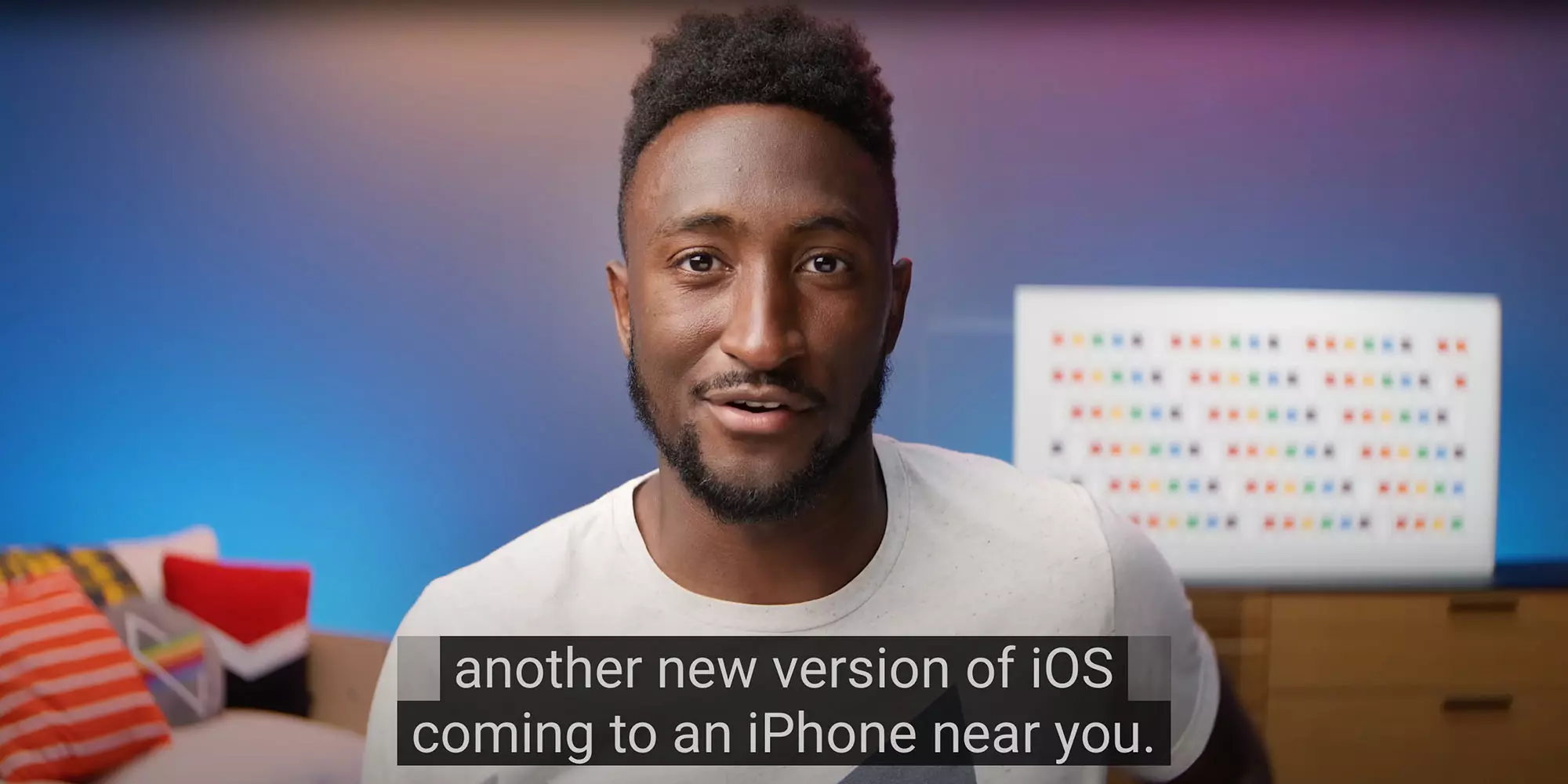
Mindez nagyon komoly probléma, de a gondot csak tetézi, hogy az anyagokat összeállító nem igazán foglalkozott azzal, hogy az adatok hitelesek legyenek. Konspirációs elméletekkel foglalkozó videók szövegeit is használták a tanításra, így a Lapos Föld hiedelemmel is tisztában lesz az MI ezáltal. Azt csak remélni lehet, hogy képes lesz az információkat a helyén kezelni. Sajnos már nagyon sok olyan példát láttunk az utóbbi időben, ahol internetes butaságokból tanult adatokat próbált a mesterséges intelligencia komolyan és meggyőzően előadni.
Valójában a cégek nem igazán foglalkoznak azzal, hogy honnan származnak az adatok, csak minél nagyobb mennyiségben álljon rendelkezésre.
A szóban forgó adatcsomag a The Pile névre hallgat, és az EleutherAI vállalat állította össze. Egy nagyobb gyűjteményről van szó, amit nyíltan lehet alkalmazni, és könyvek tartalmát, Wikipedia cikkeket és még sok más információt foglal magában. Az Apple és a többiek tehát nem szó szerint maguknak összekapart adatokat használtak fel, hanem egy olyan adatcsomagot vettek igénybe, amiben ezek is benne voltak. Ettől függetlenül azonban ugyanolyan felelősség terheli őket.

Nem a mostani az első eset, hogy ilyen módszerre derült fény, és biztosak lehetünk abban, hogy nem is az utolsó. Mostanra nagyon sok visszaélést követtek el a vállalatok, és csak az a kérdés, hogy ezeket mennyi esetben fogják feltárni. Mostanra talán jobban ügyelnek a technológiai cégek a forrásaik tisztaságára, de azért továbbra sem lenne az meglepő, ha ezt követően is lennének még a mostanihoz hasonló esetek.
A mesterséges intelligencia egy elképesztően jövedelmező terület jelenleg, és sokan próbálnak ebben a versenyben jobb pozíciót fogni. Ráadásul továbbra is a hajnalán vagyunk még ennek. A szabályozók már próbálnak hatékonyabban fellépni a mostani helyzetben, de egyelőre nem igazán vannak meg ehhez a szükséges eszközeik. Az Európai Unió lesz a nyugati világban az első, ahol a mesterséges intelligenciára vonatkozó jogszabály lép életbe, az AI Act augusztus elsejével élesedik.
