Az AMD háza táján az elkövetkező évek folyamán nagy változás mehet végbe a Radeon sorozatú grafikus processzorok dizájnjában, ugyanis a most még monolitikus felépítést használó termékek áttérhetnek a RYZEN családnál is használt chipletes megoldásra. Mint ismeretes, a monolitikus, vagyis egyetlen lapkából álló lapkák esetében a dizájn komplexitásának növekedésével a gyártáshoz kapcsolódó költségek is egyre növekednek, valamint a kihozatali arányt sem egyszerű magas szinten tartani, így több tekintetben is hátrányt jelentenek ezek a megoldások. Előny viszont, hogy az egyetlen nagy összefüggő lapkán belüli kommunikáció gyorsabb lehet, mint ha több kisebb lapkát kapcsolnak össze különböző összekötő technológiákkal, vagyis mindkét dizájnnak vannak előnyei és hátrányai.
A chipletes felépítéssel kapcsolatban 2020. december 31-én nyújtott be szabadalmat az AMD, a leírás pedig elég sok érdekességre világít rá, igaz, minden részletet sajnos nem tartalmaz, így még mindig vannak nyitott kérdések a témában. Azt persze fontos kiemelni, hogy attól, hogy egy szabadalmat bejegyez egy gyártó, még egyáltalán nem biztos, hogy abból a közeljövőben kézzel fogható termék lesz. Hasonló, vagyis több lapkából álló GPU tokozással kapcsolatban néhány éve egyébként az Nvidia is bejegyzett néhány szabadalmat, vagyis az irány kétségtelenül a többlapkás dizájn felé mutat hosszabb távon, a kérdés csak az, mikor vezetik be ezeket.
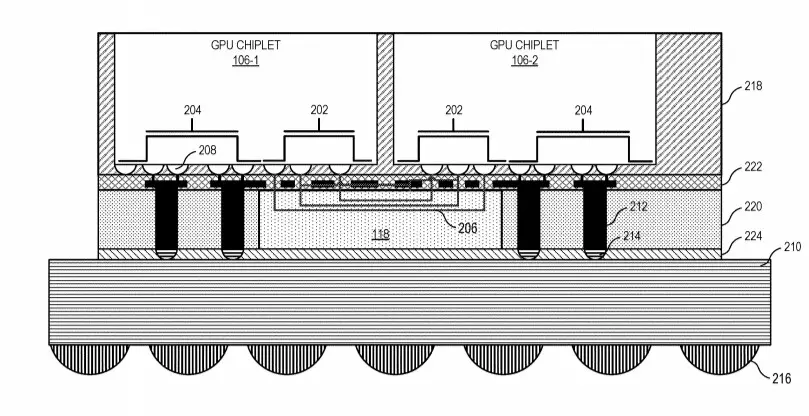
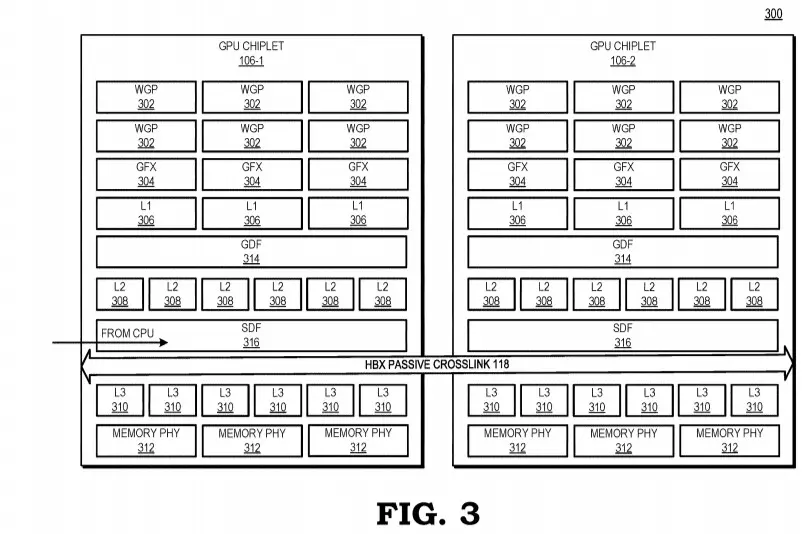
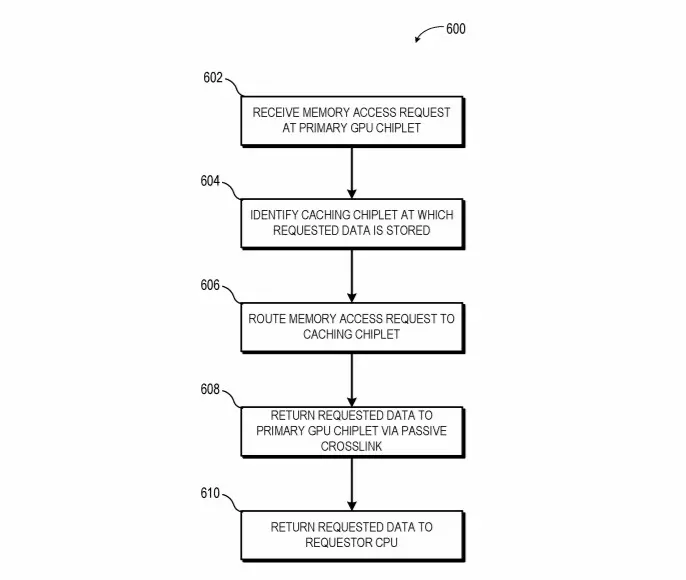
A monolitikus GPU dizájn eddig főként azért maradt életben ilyen sokáig, mert a Multi-GPU technológia nem működhetett eléggé hatékonyan, ennek pedig részben az erősen limitált szoftveres támogatás volt az oka, legalábbis az AMD szerint. A vállalat a jelek szerint megoldást talált erre a problémára, ez pedig nem más, mint egy nagy sebességű passzív crosslink technológia, ami segít az egyes chipletek közötti hatékony és gyors kommunikáció biztosításában.
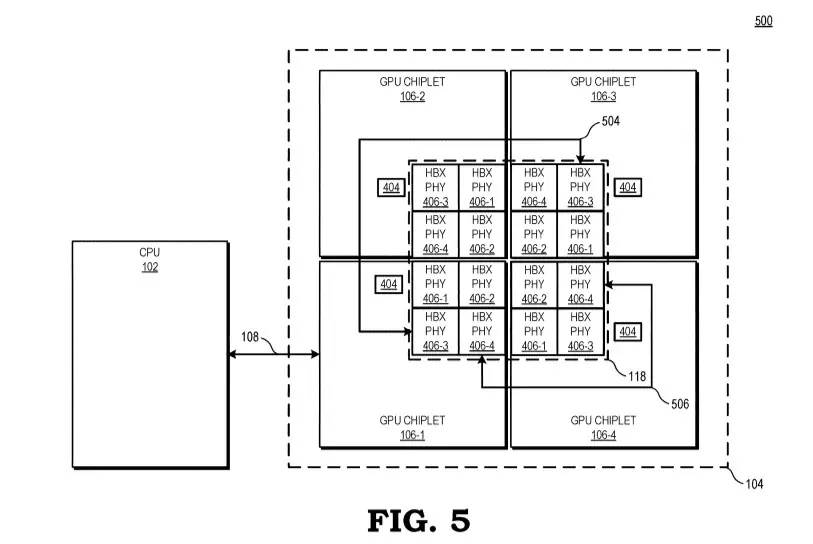
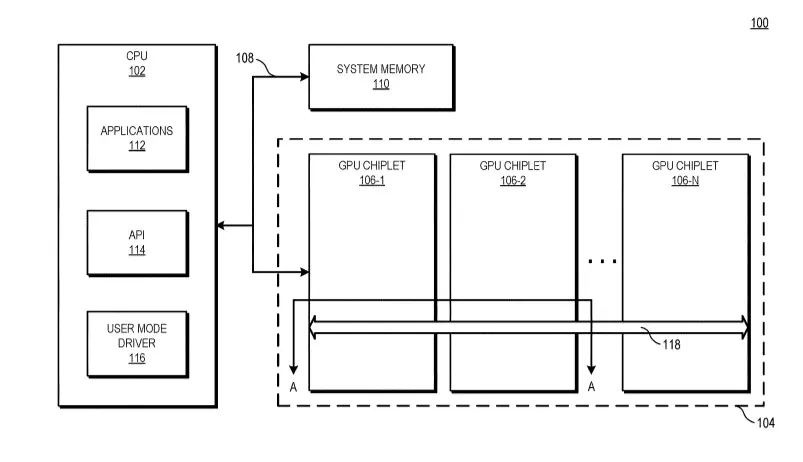
A tervezett dizájn lényege, hogy az összes chiplet kapcsolatban lenne tömbben található első GPU-val, maga a kommunikáció pedig egy aktív interposeren keresztül zajlana, ami több rétegnyi összekötőt tartalmaz a nagy sávszélességű passzív crosslink kapcsolat kiszolgálásához. A tömb első GPU-ja közvetlen kapcsolatban lenne a processzorral, ám ennek pontos technológiai megvalósításáról nem esett szó, így kérdéses, hogy a CPU az összes GPU tömb menedzselésében segítene egyfajta hídként, vagy ezt az egészet másképp oldanák-e meg – a késleltetés szempontjából nézve ez kritikusan fontos adalék.
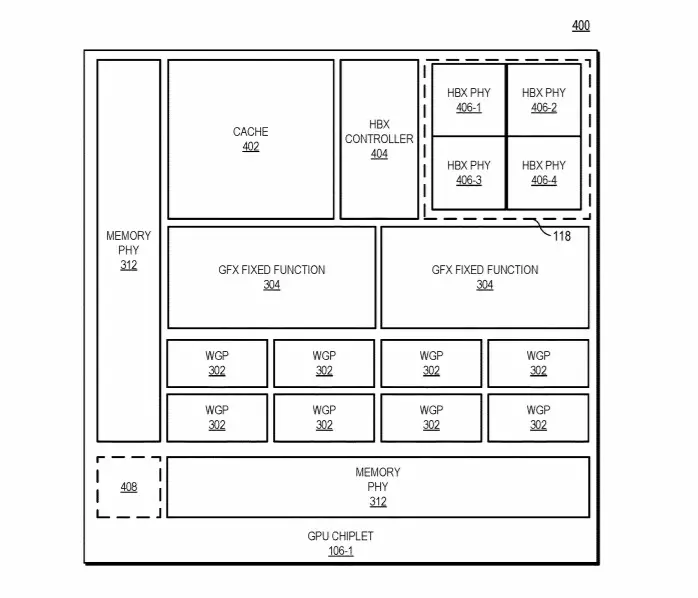
A szabadalmi bejegyzés alapján minden egyes GPU chiplet kapna egy saját utolsó szintű gyorsítótárat (LLC – Last Level Cache), valamint a chipletek közötti gyorsítótár-koherenciáról is gondoskodnának, ami a hatékony feladatvégzés kulcsa.
Az AMD esetében az aktuális információk szerint leghamarabb az RDNA 3 architektúra köré épülő GPU-k után lehet esély a chipletes felépítés bevetésére, ám ezzel kapcsolatosan hivatalos és publikus álláspont egyelőre nem áll rendelkezésre.
