
A ChatGPT nevű, mesterséges intelligencián (MI) alapuló chatbot képes összefoglalni Moby Dicket, számítógépes kódot írni, vagy éppen ínycsiklandó csirkerecepteket ajánlani. Mindezt azért tudja megtenni, mert az interneten található írott információk nagy részéhez hozzáférése van. De mi lenne, ha ugyanezt a DNS-sel is meg tudná tenni?
Ez a koncepció áll egy új kutatás hátterében, amelynek eredményeit a napokban tették közzé a Science című folyóiratban. A szakértők egy olyan, több milliárd sornyi genetikai szekvencián képzett mesterségesintelligencia-modellt ismertetnek, amely képes kikövetkeztetni a baktériumok és vírusok genomjának működését, és ezt az információt új fehérjék, sőt egész mikrobiális genomok tervezéséhez felhasználni.
Az Evo névre keresztelt modell segíthet a kutatóknak az evolúciós folyamatok feltárásában, a betegségek vizsgálatában, új gyógymódok kifejlesztésében és potenciálisan számos más orvosbiológiai kérdés megválaszolásában is.
„Ez a munka rendkívül fontos” – mondja Arvind Ramanathan, az Argonne National Laboratory komputációs biológusa, aki nem vett részt a vizsgálatban. Szerinte a tesztek, amelyeknek a szerzők az Evo rendszert alávetették, nagyszerű alkalmazási lehetőségekkel kecsegtetnek a mesterséges intelligencia számára.
A genom ChatGPT-je
A kutatók az elmúlt években számos olyan speciális MI-modellt terveztek, amelyek bizonyos típusú molekulákkal kapcsolatos, célzott feladatokat hajtanak végre. Ennek legismertebb példája talán az AlphaFold, amely a fehérjék szerkezetét jósolja meg az aminosav-szekvenciákból. Vannak azonban olyan rendszerek is, mint a ChatGPT és sok más mesterséges intelligencia, amelyek általánosabb célúak, és amelyeket éppen ezért alapmodelleknek neveznek. Sokoldalúságuk azért előnyös, mert a kutatóknak nem kell minden feladathoz más modellt létrehozniuk és betanítaniuk, amivel időt és pénzt takaríthatnak meg.
A ChatGPT, amely egy úgynevezett nagy nyelvi modell (LLM), például szinte bármilyen szavakat tartalmazó dokumentummal működik, legyen az egy kormányzati jelentés vagy egy recept. A molekuláris biológiában a DNS mindennek az alapja, ezért a szakértők kifejlesztettek néhány alapmodellt, amelyek úgy elemzik a DNS-szekvenciákat, mintha azok szavak lennének egy nagy nyelvi modellben. Ezek a mesterséges intelligenciák azonban mostanáig csak viszonylag rövid DNS-szakaszokat tudtak értelmezni és előre jelezni.
Ezen korlátok leküzdésére kifejlesztett Evo rendszert Brian Hie, a Stanford Egyetem komputációs biológusa, aki kollégáival, köztük a nemrégiben alakult Arc Institute néhány kutatójával egyik fontos lépésként növelte a kontextusok hosszát. Ez azt jelenti, hogy megnövelték azt a keresési ablakot, amelyet a modell használ, amikor DNS-ben mintázatokat próbál találni. A nagyobb kontextushossz javítja a modell képességét a gének vagy más DNS-szekvenciák közötti kapcsolatok azonosítására.
A fejlesztés egyúttal azt is lehetővé tette, hogy az Evo felbontását a DNS építőkövei, vagyis az egyes nukleotidok szintjére emeljék, míg a korábbi modellek még csak nukleotidcsoportokkal tudtak dolgozni.
Miután a kutatók létrehozták az Evo rendszert, 4 hétig tréningeztették. Ennek során a modell 80 ezer mikroba genomján, valamint a baktériumokat célzó vírusok és a plazmidok néven ismert félig független DNS-hurkok több millió szekvenciáján képezte magát. Hie elmondása szerint a rosszindulatú felhasználók elméletileg kihasználhatnák az olyan modelleket, mint az Evo, hogy biológiai fegyvert tervezzenek, ezért a kutatók kiiktatták az MI képzési adatbázisából az olyan vírusok szekvenciáit, amelyek az embert vagy más eukariótákat, vagyis a sejtmaggal rendelkező organizmusokat támadják.
Összességében az Evo 300 milliárd nukleotidnyi szekvencián tanulta meg a DNS-szerkesztés csínját-bínját.
Az MI teszteléséhez a kutatók arra kérték a rendszert, hogy jósolja meg bizonyos mutációk hatásait a fehérjék működésére. Ez nagyon fontos annak megértéséhez, hogy a DNS-hibák hogyan vezetnek betegségekhez, és az új gyógymódok tervezésében is segíthet. A csapat úgy ellenőrizte az Evo előrejelzéseit, hogy összehasonlította azokat olyan közzétett kísérletekkel, amelyekben más szakértők a kérdéses mutációkat idézték elő baktériumsejtekben. Az Evo pedig egyértelműen felülmúlta a korábbi mesterségesintelligencia-modelleket, amelyek a mutációk hatásaira DNS-szekvenciákból következtettek. Nagyjából ugyanolyan jól működött, mint a hasonló, de fehérjeszekvenciákra támaszkodó mesterségesintelligencia-modellek.
Tervezzünk genomot!
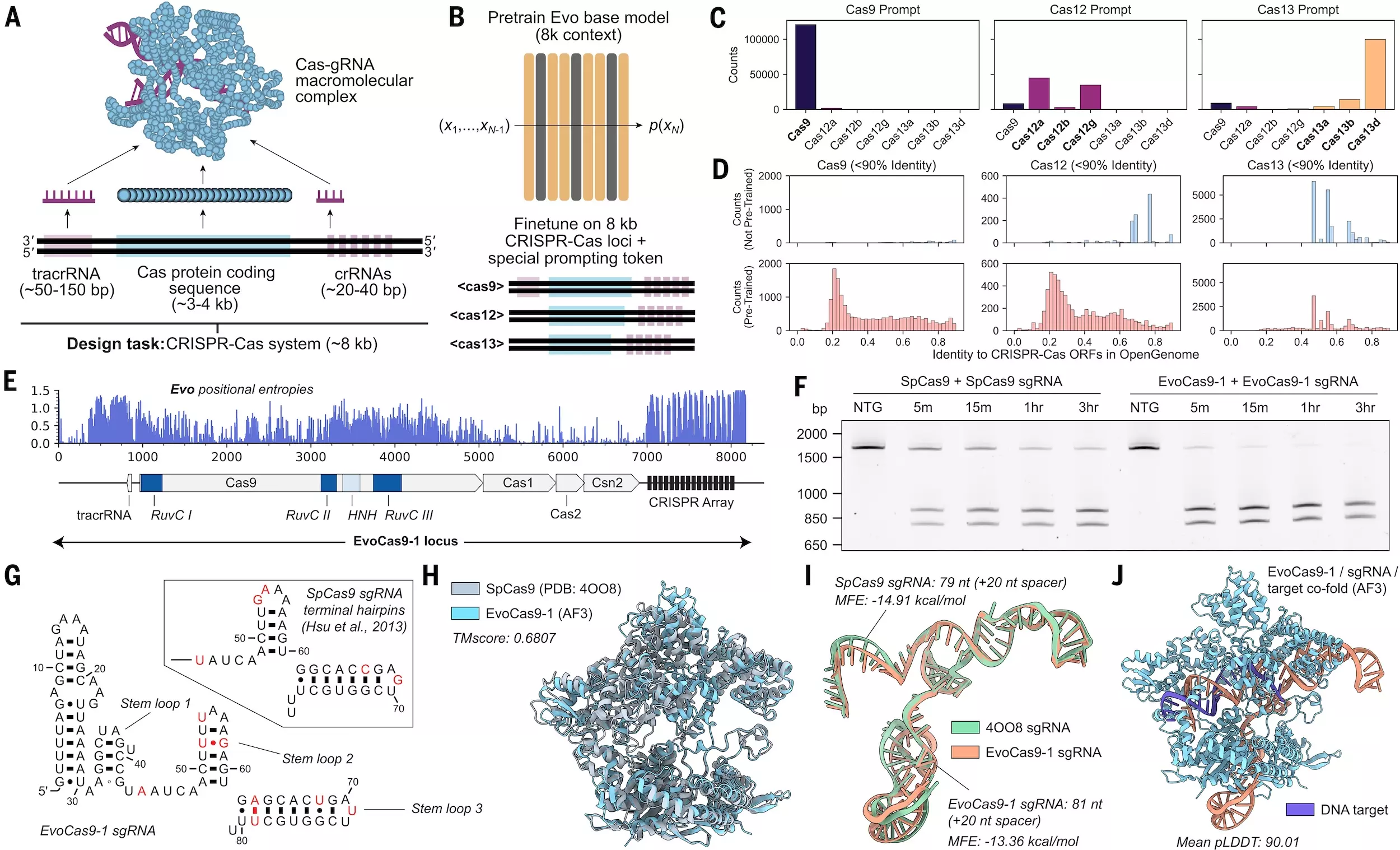
A ChatGPT-hez hasonló mesterségesintelligencia-modellek többek között azért is nagyon hasznosak, mert képesek új tartalmakat létrehozni. „Meg akartuk mutatni, hogy a mi modellünk is rendelkezik ezzel a képességgel” – mondja Hie. Ezért ő és kollégái azt mondták az Evo rendszernek, hogy tervezzen új verziókat a CRISPR genomszerkesztőből. Ez a feladat azért jelent kihívást, mert a CRISPR kétféle komponenst tartalmaz, amelyeknek együtt kell működniük: DNS-t elvágni képes Cas-fehérjéket és RNS-molekulákat, amelyek az enzimeket a szerkesztendő genomhelyekre irányítják.
Az Evo először több mint 70 ezer bakteriális DNS-szekvenciát analizált, amelyek Cas-fehérjéket és ezekhez tartozó RNS-eket kódoltak. Ezután pedig a kérdéses molekulák több millió lehetséges változatát dolgozta ki. A kutatók kiválasztották 11 nagyon ígéretes változatot választottak ki a Cas9-ből, a biotechnológiában használt Cas-fehérjék legfontosabb típusából, majd a rendszer által megtervezett enzimeket laboratóriumban szintetizálták.
A laborban végzett kísérletek során a kutatók megállapították, hogy az Evo által tervezett Cas9-enzimek közül a legjobb ugyanolyan hatékonyan vágja a DNS-t, mint a fehérje iparilag használt változata.
A Cas-fehérjék tökéletesítése érdekében a kutatók hagyományosan olyan baktériumokat kerestek, amelyekben az enzimek hatékonyabb változatai találhatók. Hie szerint az Evo segítségével viszont nem kell kivárni, amíg az evolúció kitermel egy még jobb Cas9-et, hanem azt mesterségesen létre lehet hozni. Sok nagy nyelvi modellhez hasonlóan persze az Evo is képes furcsaságokra, például olyan Cas9-eket is javasolt, amelyeknek esélyük sincs a működésre. Hie szerint az ilyen „hallucinációk” ellenére az MI még mindig jobb az új molekuláris lehetőségek megtalálásában, mint a nyers szűrések vagy a véletlenszerű találgatások.
A vizsgálat Hie elmondása szerint leglátványosabb és legőrültebb részében a kutatók arra kérték az Evo rendszert, hogy generáljon olyan DNS-szekvenciákat, amelyek elég hosszúak ahhoz, hogy baktériumok genomjaként szolgáljanak.
Úgy találták, hogy ezek a mesterséges genomok sok olyan gént hordoztak, amelyre a sejteknek szükségük van, de más, biztosan szükséges gének hiányoztak. Hie mégis úgy véli, hogy az eredmények fontos lépést jelenthetnek a mesterséges intelligencia által tervezett szintetikus genomok felé.
Az alapmodellek azért is fontosak, mert javítják a genomokkal kapcsolatos megértési és jellemzési képességeinket, ezért is jelentenek fontos továbblépést a korábbi modellekhez képest, mondja Ramana Davuluri, a Stony Brook Egyetem komputációs biológusa, aki nem vett részt a vizsgálatban.
A munka többek között abban is kiemelkedik a korábbiak közül, mert a kutatók nagyon sokat tettek a modell előrejelzéseinek kísérleti megerősítése érdekében, mondja Yunha Hwang, a New York-i székhelyű Tatta Bio nonprofit szervezet komputációs biológusa, aki genomikai mesterségesintelligencia-modellek fejlesztésével foglalkozik. „A laboratóriumi validálás jelen esetben nagyon erős” – mondja Hwang, aki nem kapcsolódott a kutatáshoz. A hatalmas adatmennyiség, amelyen az Evo tanult, szintén kiemelkedővé teszi a vizsgálatot, hiszen minél több információt szív fel egy ilyen modell, annál megbízhatóbb.
A kutatás további erénye, hogy bár mesterséges intelligencián alapuló rendszerekkel kapcsolatos projektek nagy része titokban zajlik, az Evo fejlesztői nyilvánosan közzétették az Evo rendszert, hogy más kutatók is használhassák azt. Hie elmondása szerint a csapat nem is tervezi, hogy kereskedelmi forgalomba hozza a modellt, mivel elsősorban kutatási projektként tekintek rá.
