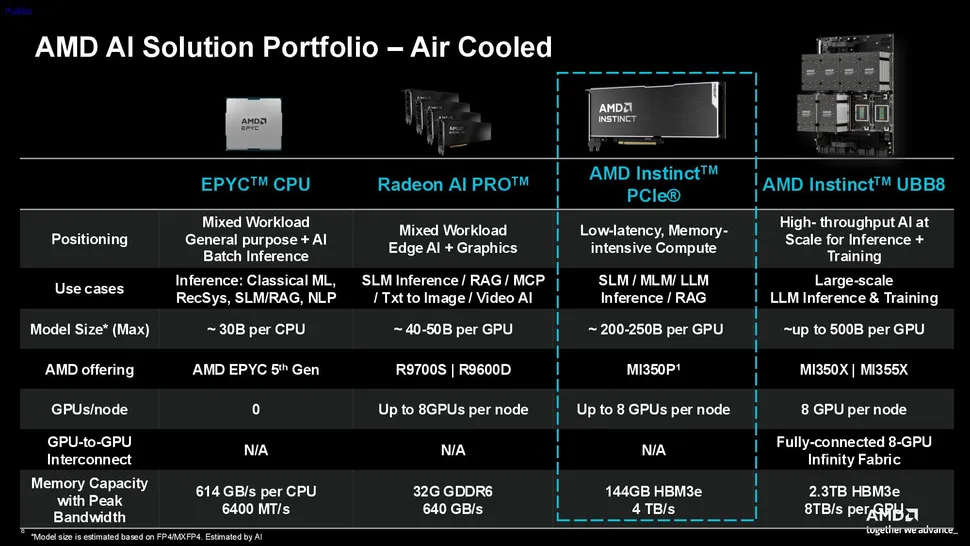
Az AMD az elmúlt napok folyamán egy új, speciális AI gyorsítót mutatott be, ami az MI350-es szériába érkezik, méghozzá egy 10,5 hüvelyk hosszú, kétslotos felépítésű PCI Express bővítőkártya formájában, ami a klasszikus léghűtésű szerverek rackjeiben kaphat helyet. Az új AI gyorsító 128 aktív CU tömböt foghat munkára, amelyek természetesen a CDNA4 architektúra köré épülnek, fedélzeti memóriaként pedig 144 GB-nyi HBM3E típusú memóriachip-szendvicshez férnek hozzá, méghozzá 4 TB/s-os memória-sávszélesség mellett.
Az új AI gyorsító passzív hűtéssel, ventilátor nélkül érkezik és 600 W-os TDP kerettel rendelkezik, de opcionálisan akár 450 W-os TDP kerettel is működhet annak érdekében, hogy még több léghűtésű szerverrel legyen kompatibilis. A kellő mennyiségű friss levegőt minden esetben az adott rack rendszerhűtői biztosítják, passzív módban nem használható a termék.

A 128 CU tömb révén összesen 8192 mag áll rendelkezésre, amelyekhez 512 darab mátrix mag is társul, míg a maximális GPU órajel 2,2 GHz-en tetőzik. A GPU rendelkezik még 128 MB-nyi utolsó szintű gyorsítótárral (LLC), a fedélzeti memória szerepét pedig az említett 144 GB-nyi HBM3E chip tölti be. Ebből az AI gyorsítóból akár nyolc is helyet foglalhat egy rendszerben, méghozzá MXFP4 és MXFP6 támogatással karöltve, amelyek révén hatékonyan gyorsíthatóak a különböző AI feladatok.
Az AMD szerint az MI350P jelenleg a piacon elérhető leggyorsabb megoldás a klasszikus PCI Express slotba illeszthető modellek közül, hiszen 2299 FLOP/s-os számítási teljesítményt nyújt MXFP4-es műveletek terén, míg MXFP4-es számítási teljesítményének csúcsa 4600 TFLOP/s magasságában helyezkedik el, ahogy az az egyik lentebbi dián is látszik.

Eddig az Nvidia H200 NVL uralta ezt a piaci szegmenset, az AMD MI350P azonban magasabbra helyezi a lécet, ugyanis FP64-es műveletek terén 20%-os, FP16-os műveletek esetén 43%-os, míg FP8-as műveletek terén 39%-os előnyt kínál riválisához képest, már ami az elméleti maximális értékek összehasonlítását illeti.

Az Nvidia térfelén a legmodernebb, Blackwell alapú B200-as modellekből egyelőre még nem érkezett PCI Express slotba illeszkedő, HBM memóriachip-szendvicseket alkalmazó kiadás, így egyelőre az AMD kínálja a leggyorsabb megoldást. A CUDA ökoszisztéma nyomasztó uralma ellen így is nehezen veheti fel a versenyt az AMD, de mivel a ROCm szoftverkörnyezetet folyamatosan fejlesztik, egyre versenyképesebbé válhatnak, ami előbb-utóbb a piaci részesedés növekedését hozhatja.
Persze az Nvidia csapata sem ül tétlenül a babérjain, próbálják biztosítani azt, hogy a vállalat továbbra is magabiztosan uralhassa a piacot.
