A Microsoft Office szoftvercsomagjával kapcsolatban egy érdekes információ bukkant fel nemrégiben, amely alapján úgy tűnt, a vállalat egy előre aktivált beállításon keresztül használhatja fel a Word és az Excel alkalmazásokban feldolgozott tartalmakat annak érdekében, hogy nagy nyelvi modelljét (LLM – Large Language Model) megfelelően tréningezhesse. A történetre időközben a Microsoft is reagált, de az előzményeket így is érdemes megismerni.
Az előzmények
Egy @nixCraft becenévvel posztoló „X” felhasználó, aki a cyberciti.biz weboldal szerzője is egyben, arra hívta fel a figyelmet a minap, hogy a Microsoft egy előre aktivált opción keresztül arra használja a Microsoft Office egyes alkalmazásait, hogy a bennük feldolgozott adatok segítségével tréningezze nagy nyelvi modelljét, ami a vállalat különböző AI alapú szolgáltatásainak biztosításáról gondoskodik. Lényegében az Excelben és a Wordben feldolgozott felhasználói adatok felhasználására hívta fel a figyelmet az említett rendszeradminisztrátor, aki szerint az AI modellekhez használt adatok gyűjtése a „Connected Experiences”, azaz a „Kapcsolt Funkciók” opción keresztül zajlik, ez pedig az adott Microsoft Office szoftvercsomag telepítését követően automatikusan aktív. Utóbbi azért is lehet problémás, mert az Európai Unióban érvényes GDPR alapján az efféle funkcióknak nem lehetnek alapértelmezetten bekapcsoltak, azokat a felhasználónak „ráutaló magatartással” kell kérniük, vagyis sajt maguknak kéne bekapcsolniuk, de ebben az esetben ez nincs így, ami már alapból is probléma lehet.
Azzal, hogy a felhasználói adatokat az AI modell térningezéséhez használják, óriási előnyre tehetnek szert a vetélytársakhoz képest, akik efféle gyakorlatokat nem alkalmaznak. A minőségi adatkészletek óriási értéket képviselnek, hiszen segítségükkel az adott LLM hatékonyabban és pontosabban működhet, valamint többféle funkciót is elláthat attól függően, hogyan és mire tréningezték.
Amennyiben az adatok között bizalmas céges vagy kormányzati információk is találhatóak, az mindenképpen problémát jelent, illetve az sem mellékes, ha kényes személyes adatokat tartalmaz. Az efféle adatokat a munka során kizárhatják a szakemberek a tréning-adatbázisból, de ha ez nem történik meg, a megfelelően képzett professzionális adatelemzők meg tudják őket szerezni a megfelelő módszerekkel, hiszen az LLM-ek esetében előfordul, hogy a tréninghez használt adatok egy részét kiszivárogtatják a megfelelő módszerek alkalmazása esetén.
A Microsoft hivatalos reakciója
Nem sokkal azután, hogy a média képviselői elkezdték felkapni a témát, a Microsoft szóvivője egy közleményben tudatta a cég álláspontját. Ez alapján a Microsoft nem használ felhasználói adatokat a Microsoft 465 szoftvercsomag konzumerpiaci és üzleti alkalmazásaiból a nagy nyelvi modellek tréningezéséhez. Hozzátette azt is, hogy a Connected Services beállításnak semmilyen módon sem kapcsolódik ahhoz, hogy a Microsoft miként tréningezi nagy nyelvi modelljeit.
A vállalat Connected Experience szolgáltatása a leírás szerint abban segít a felhasználóknak, hogy kereshessenek az online tartalmak között és le is tölthessék azokat annak érdekében, hogy kiegészíthessék dokumentumaikat. A letölthető dolgok közé tartoznak a sablonok, a képek, a 3D modellek, a videók, illetve a referencia anyagok is. A vállalat egy táblázatot is készített, ami tartalmazza, mi minden tartozik a Connected Experience szolgáltatás leöltései közé, ez az alábbiakban található.
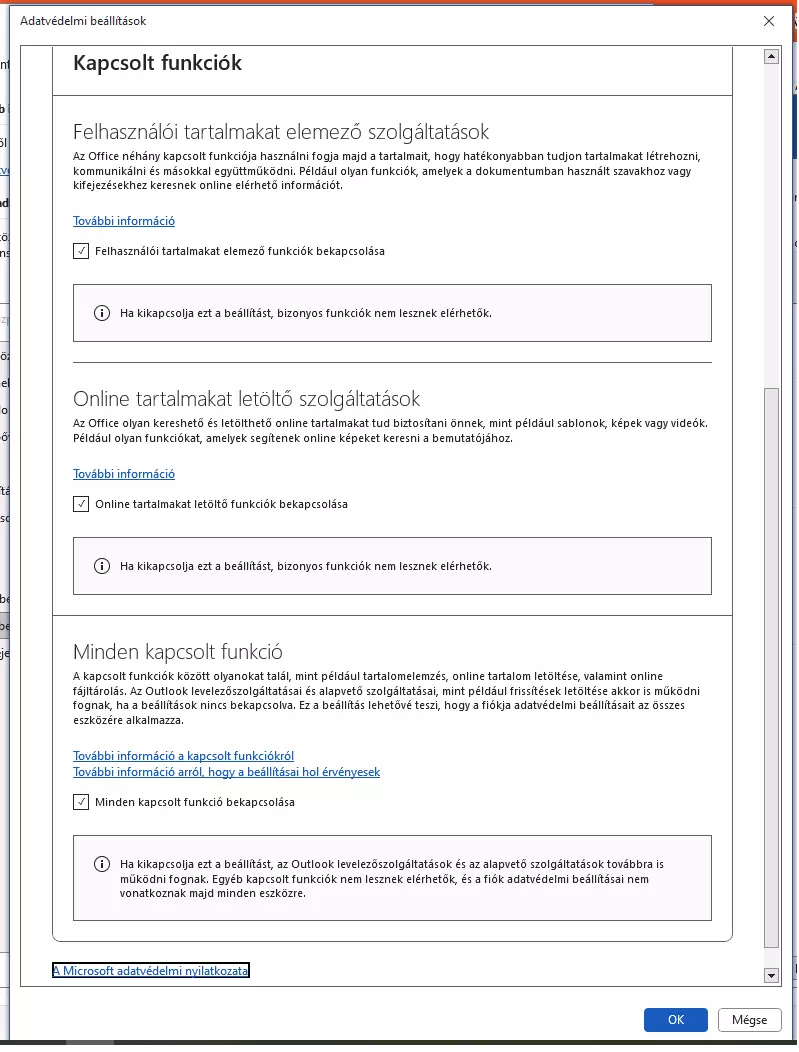
Aki mégis szeretné kikapcsolni a funkciót, ami saját személyes tapasztalatunk szerint a jogtiszta Office 2019 telepítésének végén alapból aktív volt, hét lépésben teheti meg. Először is el kell látogatni a Beállítások menübe, ahol az Adatvédelmi központon belül az Adatvédelmi beállítások menüpontot kell felkeresni. Itt a legfelső gombra, az Adatvédelmi beállításokra kattintva megtaláljuk a Kapcsol funkciók menüt, ahol a számunkra szükségtelennek ítélt opciókat kikapcsolhatjuk.
Az Office 2019 Word alkalmazásánál ebben a menüben az olvasható, hogy a szolgáltatás elemzi a felhasználói tartalmakat, ami nem biztos, hogy mindenki számára elfogadható, így aki úgy gondolja, ezt nem kéri, kapcsolja ki a szolgáltatást. Ettől persze még nem biztos, hogy megszabadulunk a tartalomelemző funkcióktól...
Ami a hivatalos dokumentáció alapján pluszban kiderül
Érdekesség, hogy az egyes funkciók leírásánál található linkeken keresztül sok hasznos információhoz lehet hozzájutni, ha vesszük a fáradtságot a tartalmak átböngészéséhez. Ezek között található az alábbi leírás is, ami a személyes adatok használatával kapcsolatos gyakorlatról ad képet.
„A Microsoft az adatok felhasználásával releváns és értékes információkat nyújt Önnek termékeinkről. Az adatokat főként a következő területeken használjuk fel:
- Termékeink biztosítása, amely magában foglalja a frissítést, a védelmet és a hibaelhárítást, valamint a támogatás nyújtását. Magában foglalja az adatok megosztását is, ha arra szükség van a szolgáltatás biztosításához vagy az Ön által kért tranzakciók elvégzéséhez.
- Termékeink javítása és fejlesztése.
- Termékeink személyre szabása és javaslatok nyújtása.
- Hirdetések és marketinganyagok megjelenítése Önnek, amely tartalmazza a reklámcélú tájékoztatóanyagok küldését, valamint célzott hirdetések és releváns ajánlatok megjelenítését.
Az adatokat vállalatunk működtetésére is felhasználjuk, például teljesítményünk elemzésére, jogi kötelezettségeink teljesítésére, munkatársaink fejlesztésére, valamint kutatások végrehajtására.
Ezen célok elérése érdekében összekapcsoljuk a különböző célokból (például két Microsoft-termék Ön általi használata során) gyűjtött vagy harmadik féltől beszerzett adatokat, hogy zökkenőmentesebb, egységesebb és személyre szabottabb felhasználói élményt nyújthassunk Önnek, megalapozottabb üzleti döntéseket hozhassunk, és egyéb jogszerű célokért.
A személyes adatok e célokra történő feldolgozása automatizált és manuális (emberek által végzett) feldolgozási módszereket is tartalmaz. Az automatizált módszereink gyakran kapcsolatban állnak a manuális módszereinkkel, és azokra építkeznek. Az automatizált feldolgozási módszerek (beleértve a mesterséges intelligenciát vagy az MI-t is) kiépítéséhez, betanításához és a pontosságuk javításához például manuálisan felülvizsgáljuk az automatizált módszerek eredményeit a mögöttes adatok tekintetében.
A termékeink javítására és fejlesztésére irányuló erőfeszítéseink részeként felhasználhatjuk adatait az AI-modellek fejlesztéséhez és betanításához. További információt itt talál.„
A fentiekben azt nem részletezik, pontosan milyen adatokról van szó és ezeket pontosan hogyan dolgozzák fel, a további információ linkre sajnos csak a Copilot weboldala jön be, pedig érdemes lenne tovább taglalni a kérdést.
A Tom’s Hardware munkatársa, Anton Shilov arra is rámutatott, a Microsoft szolgáltatásokra vonatkozó megállapodásában, vagyis a Microsoft Szolgáltatási Szerződésében az olvasható, hogy a felhasználó az egyezmény elfogadásával globális és jogdíjmentes szellemi tulajdonjogot ad a Microsoftnak a tartalmai használatára, ezekről például másolat készülhet, a tartalmakat megőrizhetik, továbbíthatják, újraformázhatják, megjeleníthetik, illetve kommunikációs eszközökön keresztül történő terjesztésükre is jogot kapnak a szolgáltatásokon keresztül.
Ebbe elméletben az is beletartozhat, hogy a tartalmakat AI tréningezésre is felhasználhatják, így igazából a kör bezárult: ha elfogadjuk a megállapodást, a fentieket is elfogadjuk. Igaz, a fenti részlet nem az EU-ban érvényes megállapodásból származik, hanem az Amerikai Egyesült Államok területére szabott verzióból.
A magyar kiadást felcsapva az alábbi leírást találjuk:
„A Szolgáltatásoknak az Ön és mások számára történő nyújtásához (ez magában foglalhatja az Ön Tartalmai méretének, alakjának vagy formátumának a jobb tárolhatóság és jobb megjeleníthetőség érdekében történő megváltoztatását is), az Ön és a Szolgáltatások védelméhez, valamint a Microsoft termékeinek és szolgáltatásainak továbbfejlesztéséhez szükséges mértékben Ön a Microsoftnak az egész világra kiterjedő, díjmentes, szellemi tulajdonjogi licencet ad az Ön Tartalmainak használatára, például az Ön Tartalmai megőrzésére, továbbítására, újraformázására, kommunikációs eszközökön keresztül történő terjesztésére, a Szolgáltatásokon történő megjelenítésére, valamint másodpéldányai elkészítésére. Ha Ön az Ön Tartalmait a Szolgáltatás nyilvános online elérésű vagy korlátozás nélküli területein teszi közzé, akkor az Ön Tartalmai a Szolgáltatást népszerűsítő bemutatókban vagy anyagokban is megjelenhetnek. A Szolgáltatás egyes részeit reklámbevételekből tartjuk fenn. A reklámok Microsoft általi személyre szabásának szabályai itt találhatók: https://choice.live.com. Amikor a reklámokat célzottan Önre irányítjuk, nem használjuk fel azt, amit Ön e-mailjeiben vagy dokumentumaiban ír, csevegése vagy videohívásai során vagy hangüzeneteiben mond, sem azt, amit fényképei vagy egyéb személyes fájljai tartalmaznak. Reklámozási irányelveinket Adatvédelmi nyilatkozatunk ismerteti részletesen.”
A fentiek alapján tehát erősen valószínű, hogy az LLM tréning kapcsán is felhasználásra kerülnek a felhasználóktól származó adatok, mindössze nem a Connected Experiences szolgáltatáson keresztül jutnak el a Microsofthoz, hanem egyéb úton, legalábbis most ez tűnik valószínűnek. Remélhetőleg a nagy médiafelhajtás hatására rövidesen tisztulhat a kép a témában, ha másképp nem, akkor egy esetleges Európai Uniós vizsgálat keretén belül.
Nem a Microsoft az egyetlen
Az elmúlt időszakban több esetben is fény derült arra, hogyan szereznek az egyes nagyvállalatok megfelelő mennyiségű és minőségű adatot az egyes LLM-ek tréningezéséhez. Ezek a nagy nyelvi modellek biztosítják a modern AI funkciókat, vagyis kifejezetten fontos, hogy minőségi és pontos adatokkal tréningezzék őket annak érdekében, hogy a szolgáltatás színvonala is magas lehessen.
A Meta például felhasználja a publikus bejegyzéseket, hozzászólásokat, illetve fényképeket amelyek a Facebook, az Instagram, a Threads, illetve a WhatsApp szolgáltatáson belül találhatóak, valamint a chatbotokkal folytatott felhasználói interakciókat is hasznosítják az LLM fejlesztéséhez. Az Amerikai Egyesült Államok területén ez ellen nem sokat tudnak tenni a felhasználók, hiszen általában nincs módjuk az adatgyűjtésből való kiszállásra úgy, mint az EU-ban vagy az Egyesült Királyságban, maximum privátra állíthatják az adott felhasználói fiókot, de rendszerint az sem feltétlenül akadályozza meg az adatok felhasználását.

Korábban az Adobe is hasonló helyzetbe került, mint a Microsoft, ugyanis egy felugró ablak azt sugallta, hogy a vállalat a felhasználó által készített tartalom felett rendelkezhet és felhasználhatja az AI modelljeinek tréningezésére is, ám abban az esetben a médiafelhajtás következtében tisztázták a tartalmak felhasználásnak lehetséges módjait. Nincs kizárva, hogy a Microsoft esetében is ez történik majd.
További érdekesség, hogy az Nvidia korábban naponta 80 évnyi videótartalmat töltött le a YouTube, a Netflix, illetve egyéb platformok igénybevételével annak érdekében, hogy tréningezni tudja saját AI modelljeit. Hasonló gyakorlatokat több vállalat is alkalmaz, amire mindenképpen megoldást kell találni annak érdekében, hogy az AI tréningezésre használt módszerek még véletlenül se legyenek jogsértőek.
