
1. oldal
A Lumiére fivérek talán leghíresebb alkotása, A vonat érkezése az első nyilvánosan vetített filmek egyike volt 1896-ban. Az 50 másodperces jelenet, amelyben egy vonat érkezik La Ciotat állomására, most újra történelmet írt: 121 évvel bemutatása után ugyanis ez lett az egyik első film, amelyet DNS-alapú adattárolással rögzítettek. Yaniv Erlich és Dina Zielinski, a New Yorki Genomközpont és a Columbia Egyetem kutatói a filmecskén kívül egy operációs rendszert, egy képet, egy tanulmányt, egy számítógépes vírust és egy Amazon-ajándékkupont kódoltak az élethez elengedhetetlen molekula révén.
Egy új megoldásnak köszönhetően ráadásul mindezt rendkívül kis méretekben valósították meg. Míg egy 1 terabájtos merevlemez tömege nagyjából 150 gramm, Erlich és Zielinski 215 ezerszer ennyi adatot tud eltárolni egyetlen gramm DNS-ben. Ami azt jelenti, hogy az új módszerrel kódolva a világ összes adata elférne egy autó csomagtartójában.
A DNS adattárolásra való használata egyáltalán nem újdonság, hiszen az élet maga is ennek köszönhetően létezhet. A kettős spirál alakú molekulában négy nukleotid bázis (adenin – A, guanin – G, citozin – C, timin – T) kódolja azokat információkat, amelyek alapján az élőlények felépülnek és működnek. A kód révén ugyanakkor másfajta adatokat is lehetséges eltárolni, ehhez az említett digitális anyagok esetében mindössze át kellett fordítani a bázisok nyelvére az egyeseket és a nullákat, és egy nekik megfelelő DNS-t felépíteni.

És hogy mi ennek az értelme? A DNS-nek számos előnye van a ma használatos adattároló rendszerek többségével szemben. Először is, ahogy már említettük, nagyon kis helyen rengeteg információ tárolható, így az adatok kevesebb fizikai helyet foglalnak el. Másodszor a molekula rendkívül strapabíró: megfelelő körülmények közt tartva több tízezer évig is leolvashatók maradnak a benne tárolt adatok.
A harmadik és talán legfontosabb tény pedig, hogy a DNS több mint 3 milliárd éves múltra tekint vissza a bolygón. A modernkori adattárolók, a flopik, a videokazetták, a CD-k és társaik sorra elavulnak, ráadásul minden új megoldáshoz új olvasókat kell vásárolniuk a felhasználóknak, a DNS formájában rögzített adatokkal ez viszont nem fog megtörténni. Amíg lesz DNS-alapú élet a bolygón, arra is lesz törekvés, hogy ez leolvasható legyen. A szekvenáló módszerek persze fejlődnek majd, és a rögzítés is gyorsabbá válik, de az, hogy mit kell leolvasni, vagy milyen módon kell kódolni az adatokat, nem fog változni.
Ami a DNS-alapú adattárolásra irányuló első kísérleteket illeti, a szakértők kezdetben azzal próbálkoztak, hogy élő sejtek genomjába igyekeztek adatokat beleírni. Ezzel azonban az volt a fő probléma, hogy a sejt idővel elpusztult, vagyis az adatok hosszútávú tárolására nem volt alkalmas a módszer. A másik gondot az jelentette, hogy az élő sejt DNS-e folyamatosan változik, másolódik, javító mechanizmusok indulnak be rajta, így az adatok minősége a sejt élete folyamán is folyamatosan romlott.

Az első jól működő DNS-alapú adattárolót George Church, a Harvard kutatója alkotta meg 2012-ben. Church és társai a szakértő újonnan kiadott könyvét, néhány képet és egy Javascript-programot kódoltak a nukleotid bázisok révén. A sejteket kiiktatták a képből, és a kémiai úton szintetizált DNS-szakaszokat egyszerűen egy üvegchipre nyomtatták. Az egyesek helyére guanin vagy timin, a nullák helyére pedig adenin vagy citozin került a sorban. Az adatsort darabokra szabdalták és rövidebb fragmentumonként szintetizálták a kódoló szakaszokat. Ezek egyúttal egy-egy „vonalkódot” is kaptak, amely azt jelezte, hogy hol helyezkedtek el a teljes adatsorban. Az információ leolvasásához egy szekvenálóra és egy számítógépre volt szükség, amely sorba rendezte a töredékeket, majd visszafordította eredeti formátumukra a fájlokat.
A következő évben Church módszerét fejlesztette tovább Nick Goldman és Ewan Birney, az Európai Bioinformatikai Intézet (EBI) két tudósa egy kevesebb hibával működő rendszert dolgozva ki. Az első megoldással az volt a legnagyobb gond, hogy a leolvasás során a szekvenálók nehezen boldogultak az egymást követő egyforma bázisokkal, amelyekből pedig elég sok akadt a kódsorban. A szakértők ezért egyrészt egy hármas kódrendszerre tértek át, másrészt lemondtak az állandó megfeleltetésekről a kódolás során, és egy-egy bázis jelentését attól tették függővé, hogy azt milyen bázis előzi meg. Így kevesebb bázisismétlődés volt a sorokban, ami megkönnyítette a szekvenálást.
A kutatók a módszerrel DNS-re fordították Shakespeare mind a 154 ismert szonettjét, Francis Crick és James D. Watson a DNS szerkezetéről szóló tanulmányának PDF-változatát, egy fotót saját laborjukról, valamint Martin Luther King Van egy álmom kezdetű beszédének egy részletét MP3-formátumban. És ha már úgyis belelendültek a munkába, hozzácsapták ezekhez az átkódolást végrehajtó algoritmust is.
2. oldal
A DNS-alapú tárolás egyik, már említett problémája, hogy a szintetizálás és a szekvenálás is csak néhány száz bázisból álló szakaszokon működik megfelelően. A nagy fájlokat tehát apró darabokra kell bontani, majd ezeket DNS-ben kódolni. A végeredmény egy nagy halom DNS-darab lesz, amit aztán a leolvasáshoz úgy kell összerakni, hogy semmi ne maradjon ki a gigantikus kirakósból.
Church ezt a gondot úgy oldotta meg, hogy minden adatblokkot több ezer másolatban tárolt, amelyeket a leolvasáskor egymással is összevetett. Goldman és Birney a DNS-darabok számának csökkentése érdekében egymást átfedő fragmentumokkal dolgoztak. Egy-egy szakaszban 100 bázis kódolta a tárolni kívánt adatot, de a szintetizáláskor mindig csak 25 bázissal csúsztak odébb a szakértők az adatsorban. Így minden információmorzsa négy DNS-darabon is tárolódott. A módszer nagyjából bevált, de nagyon körülményes volt, és az elővigyázatosság ellenére is akadtak hibák.
Érdekes módon az online streameket kínáló szolgáltatások, például a Netflix vagy a Spotify nagyon hasonló gondokkal küzdenek. Ezek sokszor nagyon zajos csatornákon küldik keresztül adataikat, amelyekből az elveszett fragmentumok ellenére is élvezhető tartalomnak kell összeállnia. Ezt úgynevezett fountain kódok (vagy szökőkútkódok) segítségével oldják meg, amelyek véletlenszerű módon egységnyi csomagokat generálnak a forrásfájlból. Ha ezek megfelelő számban célba érnek, a vevő oldalán rekonstruálható belőlük az eredeti tartalom, még akkor is, ha nem minden csomag érkezett meg. A módszer előnye, hogy minimális redundancia mellett megbízható adatátvitelt lehet vele biztosítani még egyirányú csatornák esetén is.
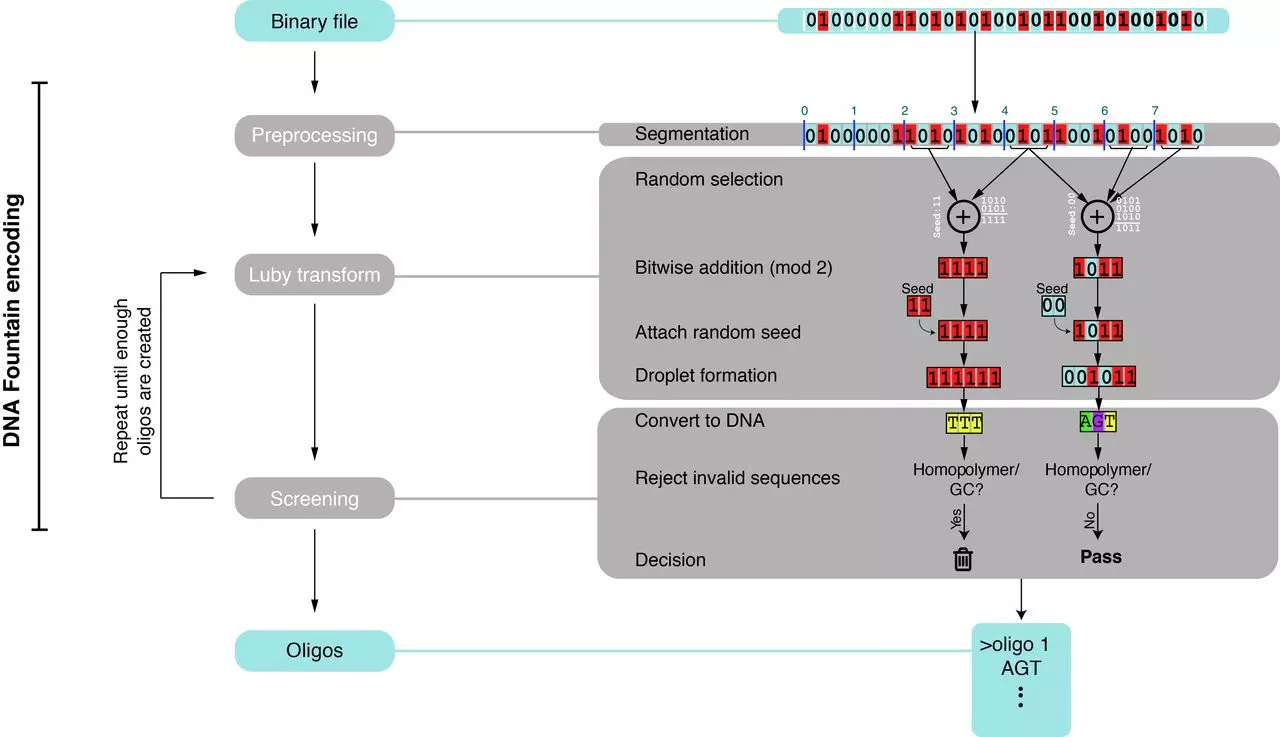
Erlich és Zielinski erre alapozva dolgozták ki saját módszerüket a DNS-alapú adattárolásra és adatolvasásra, a fountain kódok révén a korábbi megoldásoknál 60 százalékkal jobb hatásfokú adattárolást valósítva meg. Összesen 2,1 megabájt tömörített adatot fordítottak le DNS-szakaszokká, majd megpróbálták leolvasni ezeket. A fountain kód vezérletével 72 ezer DNS-szakaszt szintetizáltak, ami mindössze 7 százalékos redundanciát jelent, és a tárolt információkat akkor is sikerült tökéletes módon visszanyerniük, amikor véletlenszerűen megsemmisítettek 2000 szakaszt.
Saját becslésük szerint végül 216 petabájt/gramm adatsűrűséget valósítottak meg, ami ilyen alacsony redundanciaszint mellett nagyon közel jár a DNS formájában tárolható információmennyiség maximális adatsűrűségéhez. A kísérlet során a már említett vonatos film mellett DNS-ben rögzítették a KolibriOS-t, a Pioneer-űrszondákon utazó lemez képét, egy tanulmányt, amely arról szól, hogy különböző hordozókon mennyi információt lehetséges rögzíteni, a Zipbomb nevű vírust és egy 50 dolláros Amazon-ajándékkupont.
Az eredmény kétségkívül figyelemre méltó, ugyanakkor a DNS-alapú tárolásnak van néhány hátránya is, amelyeket meg kell oldani, mielőtt praktikusan használhatóvá válik a technika. A legnagyobb gond ezek közül, hogy a jelenleg használatos szekvenáló módszerek megsemmisítik a leolvasott szakaszokat. Vagyis a tárolt adatok olvasás közben eltűnnek. A DNS-t persze természetéből adódóan nagyon könnyű másolni, így minden olvasásra új kópiát lehet készíteni az adatokból, ezzel viszont az a probléma, hogy minden másolással nő a hibák előfordulási esélye. A fountain kódos módszer azonban erre is megoldást jelenthet. Zielinski például tízszer másolta le a szintetizált szakaszokat, és minden alkalommal tökéletes állapotban sikerült visszanyernie a fájlokat.
A másik gond a DNS-alapú tárolással, hogy jelenleg még rendkívül költséges mulatság. Bár a DNS-szekvenálás ára rengeteget csökkent az elmúlt pár évben, még mindig nem olcsó leolvasni a genetikai kódot, és ugyanez a helyzet a DNS szintetizálásával is. Amikor Birney és Goldman publikálták saját tanulmányukat, 12 400 dollárba került egy megabájt adat DNS-ként való kódolása. Ma ugyanez 3500 dollárba kerül. A költségeknél is nagyobb gond azonban, hogy bár a szekvenáló rendszerek egyre elterjedtebbek, DNS-szintézis egyelőre nagyon kevés helyen folyik. Jelenleg összesítve sincs elegendő kapacitás a Földön egy petabájt adat kódolására.
Erlich azonban azt reméli, hogy ha társaival meggyőznek mindenkit arról, hogy a DNS-alapú adattárolásban van a jövő, ezzel megindulnak a változások is. Az első merevlemezeket csak négy ember volt képes megemelni, néhány évtizeddel később pedig már körömnyi méretű pendrive-okat használunk – mondja a kutató. Egyelőre nagyon kevés pénz fordítódott a DNS-szintetizáló technikák fejlesztésére. De ha szükség lesz rá, biztosan születnek majd új, jobb megoldások ezen a téren is, folytatja Erlich.
