
A Databricks a világ egyik legnagyobb adatfeldolgozó vállalata, ami egyebek mellett elemzéssel és mesterséges intelligencia fejlesztéssel is foglalkozik már egy ideje. Az Apache Spark alkotói által létrehozott vállalkozás dollármilliárdos bevétellel rendelkezik és az utóbbi időben egyre több energiát fordított az LLM, MI és ML technológiákra. Ennek eredményeként született meg a saját nyelvi modellje.
A DBRX névre hallgató modell generatív mesterséges intelligencia fejlesztések alapjául szolgálhat, és jobb, mint az Llama 2 vagy a Grok.
Az utóbbi időben sok technológiai cég kezdett saját nyelvi modell felépítésébe, és a Databricks a jelek szerint kiváló munkát végzett. A DBRX többféle kivitelben lesz hozzáférhető, és nyíltként hivatkozik rá a vállalkozás, de azt hozzá kell tenni, hogy azért nem teljesen nyílt, csak úgy kell itt érteni ezt, mint a Meta által biztosított Llama 2 esetében. Nem lehet teljesen a mélyére látni ezeknek, és az sem publikus, hogy milyen adatokkal tanították fel őket, de elérhetőek és ingyenesen felhasználhatók.

Van kereskedelmi célra elérhető verziója a DBRX-nek, ez a DBRX Base néven fut, és biztosít a Databricks egy precízebb és jobb képességű eszközt, ami a DBRX Instruct nevet viseli. A nyelvi modellt lehet majd használni akár egyedi adatokkal is, ebben az esetben jobb hatékonyságot tud majd elérni és biztonságosabb is lesz az alkalmazása.
Egyelőre csak az angol nyelvre van optimalizálva, de fordítani már képes más nyelvekre is, és a támogatás bővítésén folyamatosan dolgoznak. A fordítás például francia, német és spanyol nyelvekkel használható. A jelenlegi formájában a DBRX már kiváló teljesítményt nyújt, és erre vonatkozóan több eredményt is megosztott a nagyközönséggel a Databrick.
Az MMLU tesztben, ami a problémamegoldó képességeket mérik fel csaknem 60 különböző témakört érintő feladatok sokaságával, és ezen a fronton szoros versenyben, de a Mixtral, az Llama 2 és a Grok-1 modelleket egyaránt übereli a DBRX, noha csak kis előnyt élvez. Matematikai feladatok megoldásában (GSM8K) és programozásban (HumanEval) viszont már masszív az újdonság fölénye a cég mérései szerint.
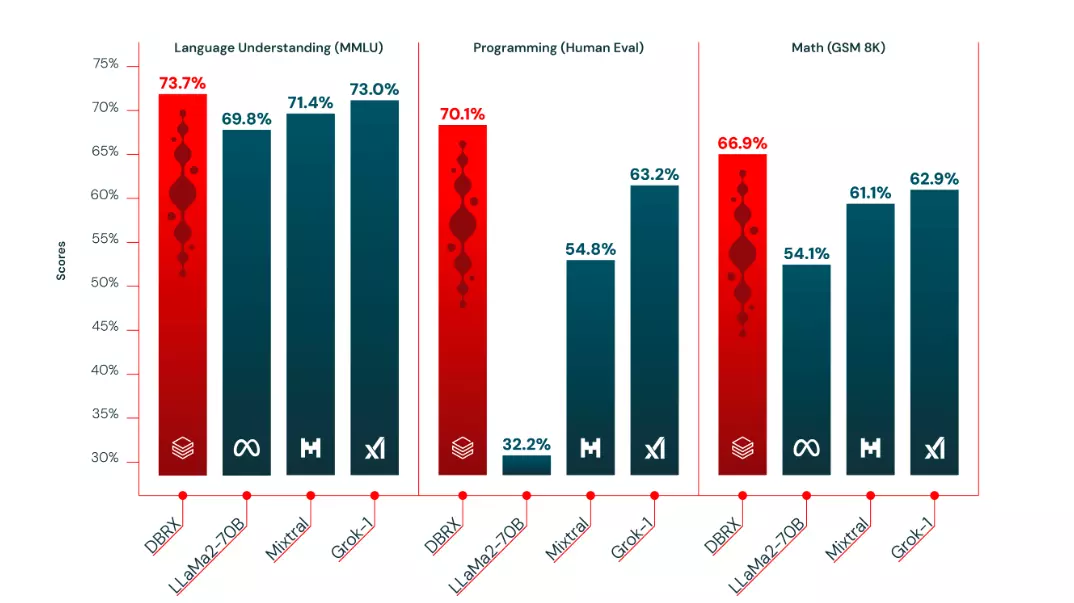
Azt is igyekezett hozzátenni a Databricks, hogy még az OpenAI által fejlesztett GPT-4 nagy nyelvi modelltől sem marad el sokkal a DBRX teljesítménye. De azért ez hitelesebb lenne akkor, ha a fenti ábrákon ezt is feltünteti a vállalkozás, és nemcsak azokat az eredményeket láthatjuk a saját fejlesztésük mellett, amiknél jobban teljesít. Nem a GPT-4 az egyedüli hiányzó, a Claude és a Gemini is kimaradt az összevetésekből.
Mindazonáltal kétségtelenül rendkívül ígéretes a Databricks generatív MI-k alapjául szolgáló nagy nyelvi modellje, ugyanis a saját bevallásuk szerint egészen szűkös keretösszegből sikerült ezt megalkotni. Állítólag nagyjából 10 millió dollárt emésztett fel a fejlesztés. Ez ugyan azért elég nagy pénz, de általában lényegesen többet költenek a technológiai cégek az MI-re, ilyen összegekből mások csak egy reklámra fizetnek be a Super Bowl szünetében.

A DBRX tréningezését a szakemberek rohamtempóban oldották meg, mindössze 2 hónap volt erre a feladatra. Azt is megtudhattuk, hogy a modell már a MoE (Mixture-of-Experts) architektúrát használja, ennek köszönhetően lényegesen gyorsabb is például a Llama 2-nél. A MoE mostanában kezd elterjedni, például a Google Gemini 1.5 Pro is ezt alkalmazza már a sebesség növelésére.
Érdeklődve várjuk, hogy a Databricks által nyújtott generatív MI eszközt hol használják majd fel elsőként, és mindenképpen érdekes lesz majd azt látni, hogy egy fogyasztóknak szánt közegben miként fog teljesíteni.
