
1. oldal
Napjaink paleontológusai rendszeresen vizsgálják a kihalt állatfajok DNS-ét, hogy információkat tudjanak meg a régmúlt idők élőlényeiről. Elképzelhető, hogy a nem túl távoli jövőben már nemcsak az őslénykutatók, hanem a könyvtárosok és levéltárosok mindennapi eszközei közt is megtaláljuk a mainál jóval kisebb és gyorsabb DNS-szekvenálókat. Tavaly nyáron a Harvard biomérnökei DNS-ben kódoltak egy genetika tankönyvet, elképesztő, 700 terabájtos grammonkénti adatsűrűséget demonstrálva, fél évvel később pedig a módszer továbbfejlesztése révén már ennek is több mint háromszorosánál, 2,2 petabájt/grammnál tartunk.
Mint a legtöbb jó ötlet, ez is egy kocsmai beszélgetés során született: Nick Goldman és Ewan Birney, az Európai Bioinformatikai Intézet (EBI) tudósai azon törték a fejüket, hogy mihez kezdjenek azzal az irgalmatlan mennyiségű archiválandó adattal, amelyet genetikai kutatócsoportjuk generál. Ez a probléma napjainkban általánosnak tekinthető: az adatmennyiség gyorsabban nő, mint a merevlemezek és egyéb adattárolók kapacitása. Ebből persze az következik, hogy egyre drágább lesz az adattárolás, a kutatóintézeti büdzsék viszont nem nagyon növekednek. Goldman és Birney így azon kezdtek elmélkedni, hogyan lehetne mesterségesen szintetizált DNS-ek révén megoldani az adattárolást. Rövidesen készen is álltak a tervvel, amelynek első kísérleti eredményeit a héten hozták nyilvánosságra.
Az ötlet persze nem új, hiszen a DNS alapvető rendeltetése szerint is információ tárolására szolgál: genomok formájában az élőlények biológiai adatait raktározza. A kutatók pár évtizede már kísérleteznek azzal, hogyan lehetne másfajta információk tárolására is alkalmassá tenni ezt a természetben évmilliárdok óta jól működő rendszert, azonban ennek megvalósítása nem bizonyult problémamentesnek.

A kezdeti próbálkozások során még élő sejtek genomjába próbáltak adatokat beleírni, ezzel azonban több gond is akad. A legszembeötlőbb közülük talán az, hogy a sejt előbb-utóbb elpusztul, így pedig képtelenség véghez vinni az új módszer fő célját: az adatok hosszú távú tárolását. A másik probléma, hogy az élő sejt DNS-e változik, replikálódik, javító mechanizmusok indulnak be rajta, mutációk történnek a kódban, így a tárolt adatok minősége folyamatosan romlik.
Mint már említettük, tavaly egy minden korábbinál sikeresebb kísérletet vittek véghez a Harvardon a DNS-alapú adattárolással kapcsolatban. George Church és kollégái kiiktatták a sejteket a képből, és a kémiai úton szintetizált DNS-fragmentumokat egy tintasugaras nyomtatóval egyszerűen egy üvegchipre nyomtatták. A kódolás során az egyeseket és nullákat egyszerűen a DNS bázisaira cserélték, nulla helyett adenin vagy citozin, egyes helyett pedig guanin vagy timin került a bázissorba. Az adathalmazt darabokra szabdalták, így csak rövidebb szakaszokat kellett egyszerre szintetizálni. A fragmentumok egyúttal egy-egy digitális „vonalkódot” is hordoztak, amely azt az információt tartalmazta, hogy az adatblokk hol helyezkedett el az eredeti fájlban. Az információ leolvasásához egy DNS-szekvenálóra és egy számítógépre volt szükség, amely sorba rendezte a töredékeket, és először bináris kóddá, majd eredeti formátumába fordította vissza a fájlt. A hibákat úgy igyekeztek kiküszöbölni, hogy minden adatblokkot több ezer kópiában tároltak, és a leolvasás során ezeket összevetették egymással.
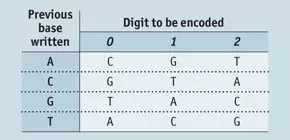
Az EBI kutatói tulajdonképpen ezt a metódust dolgozták át és fejlesztették tovább, minden korábbinál kisebb hibaszázalékkal működő rendszert dolgozva ki. A hasonló kísérleteknél, köztük Church projektje során is, komoly problémát okozott, hogy szekvenálást végző műszerek nehezen boldogulnak az egymást követő egyforma bázisokkal. A leolvasás során ilyenkor egyszerűen elvesztik a fonalat, és nem képesek pontosan rögzíteni, hogy mondjuk hány egyforma bázis is szerepel a TTTTT sorban. Ilyen sorozatok pedig egy alapvetően bináris kódolási rendszernél gyakran előfordulnak. Goldman és Birney ezért úgy döntöttek, hogy egyrészt trináris rendszerre térnek át, másrészt ebben sem használnak állandó megfeleltetéseket a kódolás során, hanem az adott bázis jelentését attól teszik függővé, hogy milyen bázis előzi meg azt.
A mellékelt táblázatot segítségül hívva látszik, hogy a módszerrel például a 000002221111 sorozat bázisokra való átfordításaként adeninnel kezdve az ACGTATGCTCTC szekvenciát kapjuk. A kódolási rendszer biztosítja, hogy sosem kerülhet egymás mellé két egyforma bázis, mivel amikor eldől, hogy egy adott számot milyen bázis kódol, a vele szomszédos bázis kimarad a szóba jöhető lehetőségek közül. Az ismétlődő bázisok hiánya pedig nagyban elősegíti a szekvenálási folyamat zökkenőmentességét.
2. oldal
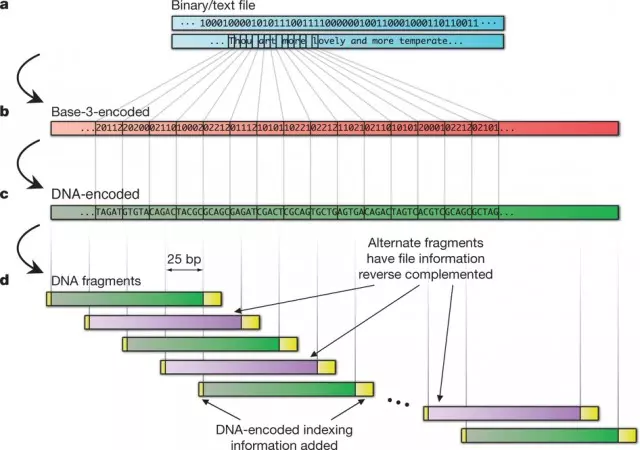
A szakértők Church módszerét követve rövidebb fragmentumokra tagolták a fájlokat, mivel a jelenlegi DNS-szintetizáló módszerek révén egyelőre nem lehetséges megbízható módon olyan hosszú molekulákat létrehozni, amelyek egy-egy fájl tárolására alkalmasak lennének. A darabok 117 bázisból álltak, ebből 100 bázis kódolta magát a fájlrészt, a maradék pedig az adott fragmentum adathalmazon belül elfoglalt helyének információit hordozta. A hibatolerancia növelése érdekében a kutatók úgy szintetizálták a fragmentumokat, hogy mindig csak 25 bázissal tolódtak el az előző darabhoz képest, így minden 25 bázisos szakasz összesen négy DNS-darabon szerepelt.
A módszert persze a gyakorlatban is kipróbálták, és az szinte tökéletesen működött. A szakértők külön hangsúlyt fektettek arra, hogy többféle különböző formátumot kódoljanak át, így DNS-re fordítódott Shakespeare mind a 154 ismert szonettje, Francis Crick és James D. Watson DNS szerkezetéről szóló tanulmányának PDF-változata, egy fotó az EBI egyik laborjáról, valamint Martin Luther King Van egy álmom kezdetű beszédének egy részlete MP3-formátumban. És ha már úgyis benne voltak, hozzácsapták ezekhez az átkódolást végrehajtó algoritmust is. A demonstráció során egyetlen probléma akadt, a PDF-cikk anyagából két 25 bázis hosszúságú szakasz elveszett. A szakértők megvizsgálták, hogy mi történt, és kiderült, hogy a hiba a szintetizálás során történt, és a két szakasz sajátos bázissorrendjéből adódott. Goldman szerint azonban ez a probléma, most, hogy már tudnak róla, viszonylag könnyen kijavítható a kódolási rendszer kismértékű módosítása révén.
A DNS-alapú adattárolásnak persze megvannak a hátrányai is. Egyrészt egyelőre rettenetesen lassú a kiolvasás sebessége: a kódolt 739,3 kilobájtnyi adat dekódolásához és rekonstrukciójához két hétre volt szükségük a szakértőknek, bár elmondásuk szerint ma már léteznek olyan berendezések is, amelyekkel ez egy nap alatt megoldható lehet. Gyakorlati használathoz ez persze még mindig nagyon lassú, de ahogy fejlődik a szekvenálás sebessége, idővel ez is megvalósulhat.
Ironikus módon tehát a metódus várhatóan még egy jó darabig nem lesz alkalmas arra, amire kitalálták, vagyis az EBI genomadatbázisának tárolására, mivel ennek információit nap, mint nap használják a szakértők. Akadnak azonban olyan adathalmazok, amelyekre jóval ritkábban van szükség, hosszú távú tárolásuk viszont nagyon fontos lenne. Ilyen például a CERN-kísérletek részecskeütközéseit tároló adatbázis. A másik, szintén remélhetőleg csak időlegesen fennálló akadály, hogy ez a fajta tárolás pillanatnyilag még igen drága. Goldman számításai szerint az általuk alkalmazott módszerrel 12 400 dollárba kerül egy megabájt adat kódolása.
Az adatok DNS-ben történő archiválása ugyanakkor rendkívüli előnyökkel is jár, így mindenképp érdemes lesz az adatátvitel sebességén és a költségek leszorításán dolgozni. Az óriási adatsűrűségen túl a módszer másik lényeges tulajdonsága, hogy valóban hosszú távú adatmegőrzést tesz lehetővé: a DNS-molekula akár több tízezer évig is képes változatlan formában tárolni a belé kódolt információkat, feltéve, hogy száraz, hűvös, fénytől védett helyen őrződik meg, és ezt sok más tartósnak ígért tárolási megoldással szemben már bizonyította is, gondoljunk csak a gyapjas mamut vagy a neandervölgyi ember fennmaradt DNS-mintáira.
Mindent összevetve a szakértők úgy vélik, hogy ha a jelenlegi ütemben fejlődik tovább a DNS szintetizálásának és szekvenálásának technológiája, módszerük egy évtizeden belül versenyképes alternatíva lehet az ötven évnél hosszabb idejű megőrzésre szánt, és viszonylag ritkán használt adatbázisok archiválására.
És persze van egy dolog, ami még vonzóbbá teszi a DNS-alapú adattárolás ötletét: a digitális adathordozók legnagyobb problémája, hogy nagyon gyorsan, a mindennapokban használt technológiák esetében akár pár év alatt elavulnak. A DNS viszont több mint 3 milliárd éve létezik, és amíg ez marad az élet alapja, addig várhatóan lesznek olyanok is, aki ki tudják olvasni, hogy mi van a molekulába írva.

