1. oldal
Amikor John Keats először olvasta George Chapman Homérosz-fordítását, saját bevallása szerint úgy érezte magát, mint egy csillagász, aki új világra bukkant. Most hasonló élményben lehet része a biológustársadalomnak, először kaparinthatják ugyanis kezükbe az ENCODE nevű projekt első eredményeit. Harminc tanulmány és óriási mennyiségű adat vált szabadon hozzáférhetővé a világhálón az elmúlt napokban. Több száz ember évekig tartó munkájának gyümölcse mindez, amely körülbelül annyi anyagi forrást emésztett fel, mint egy méretes távcső megépítése. És mint a szóban forgó teleszkóp, ez a projekt is egy új világba enged bepillantást.
Az ENCODE, avagy a DNS Elemeinek Enciklopédiája egy világszerte 32 intézetet összefogó konzorcium közös vállalkozása. A résztvevő 442 kutató a legfejlettebb rendelkezésre álló technológiákat bevetve azt tűzte ki célul, hogy génszekvenálás révén szisztematikusan elemzik az emberi szervezet 147 különböző sejtjét, annak megállapítása érdekében, hogy genom egyes részei pontosan mit is művelnek ezekben. Az eredmények megerősítik, amit a Humán Genom Projekt kezdetei óta sejtettek a kutatók: az emberi genom sokkal több egy hárommilliárd karakterből összeálló kódsornál.
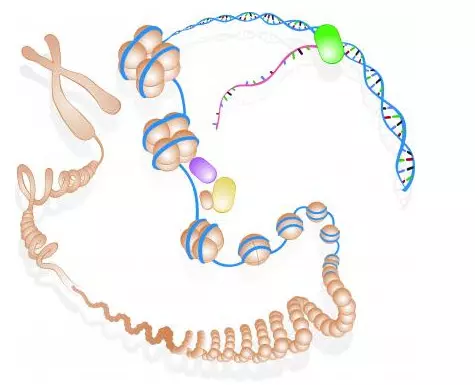
Amikor először ismertté vált a gének molekuláris felépítése, viszonylag egyszerűnek tűnt a képlet. Génnek nevezték a DNS-nek az a darabkáját, amely agy adott fehérjét kódol. Ha a sejtnek éppen szüksége van erre a fehérjére, az a nukleotidsorról transzkripció útján egy hírvivő RNS formájában „másolat” készül, ami a fehérjeszintézis helyszínére, a riboszómákhoz szállítja az információt. Viszonylag régóta ismeretes a szakértők előtt, hogy a genom fehérjéket kódoló szakaszai az egész DNS-nek csak egy nagyon kis részét ‒ alig több mint egy százalékát ‒ teszik ki. A maradék egy része a transzkripció technikai megvalósításához és szabályozásához szükséges, de alapvetően úgy tűnt, hogy a genom túlnyomó része az égvilágon semmit sem csinál, csak a helyet foglalja.

Az ENCODE során azonban világossá vált, hogy a genom több mint háromnegyed része a vizsgált sejtek valamelyikének legalább egy bizonyos életszakaszában átíródik RNS-sé. A transzkriptumok egy része rögtön szét is esik, de úgy tűnik, hogy az állomány 62 százaléka képes stabilan átíródni. A jelek szerint a fehérjeszintézis során információt továbbító mRNS-ek csak egyetlen típust jelentenek a sokféle funkciójú transzkriptum között.
A képződő RNS-ek számos feladatot láthatnak el a sejtben. Összetett módon szabályozzák például, hogy mely gének termeljenek ténylegesen fehérjét, és abból is pontosan mennyit; egyes transzkriptumokból több milliószor annyi van, mint más fajtákból. Az ENCODE jelen fázisában nem sikerült még teljesen feltérképezni ezt a sokféleséget, de azt legalább nagyjából már tudják a szakértők, hogy mit is kell keresniük.
Bár a sejttípusokban összesen a DNS 62 százaléka íródik át valamilyen célzattal, egy-egy sejtben ez az arány átlagosan mindössze 22 százalék, mivel az egyes gének aktivitását szabályozó molekuláris kapcsolók jelentős részeket kiiktatnak a genomból, attól függően, hogy éppen milyen sejtről van szó. Ezek a kapcsolók legalább olyan fontosak a sejtműködés szempontjából, mint a fehérjéket kódoló gének, ám jóval nehezebb azonosítani őket, még ha igen sok is van belőlük.
Egyértelműnek tűnik, hogy ahhoz, hogy egy adott sejtben a kizárólag a működéshez szükséges gének fejeződjenek ki, rengeteg génkapcsolóra van szükség. A szabályozó rendszer sokrétűsége azonban még feltérképezőit is meglepte. Ewan Birney, az Európai Bioinformatikai Intézet munkatársa és az ENCODE adatelemző csoportjának egyik irányítója elmondta, hogy még számukra is sokkoló volt az a felfedezés, hogy a genom 20 ezer körüli fehérjekódoló génjének működését négymillió kapcsoló irányítja. 
2. oldal
Az ENCODE most nyilvánosságra hozott adatsorai többek közt meghatározzák azokat a helyeket, ahol RNS íródik át, azokat a pontokat a DNS-en, ahová fehérjék kapcsolódnak a gének ki-, illetve bekapcsolásának céljából, felsorolják a DNS vegyileg megváltoztatott részeit, és általában mindenféle, a megszokottól eltérőnek tűnő régiót. Mindezzel pedig nagyon értékes adatbázis kerül mindazok kezébe, akiket például az érdekel, hogyan változik meg egy-egy sejt genomja a differenciálódás során, vagyis milyen módon lesz a pluripotens őssejtből „csak” összehúzódásra és elernyedésre képes izomsejt. De az adatok azok számára is érdekesek lehetnek, akik azt kutatják, hogyan és hol „romlik el” egy sejt, és lesz a szervezet ellensége.
Az emberi genommal kapcsolatos kutatásoknak a kezdetek óta slágertémái a genomszintű összehasonlító vizsgálatok. Ezek során egy-egy jellegzetes tulajdonság vagy egy betegség kapcsán vizsgálják a génállományt, és közös, szokatlannak tűnő régiókat keresnek a „hordozók” DNS-ében. Számos esetben előfordult, hogy az ilyen módon egy-egy betegség előfordulásával kapcsolatba hozott szakaszokról kiderült, hogy azok ténylegesen nem kódolnak fehérjét. Az ENCODE most végre rávilágított, hogy ilyen esetekben gyakran a szabályozó rendszer elemei érintettek.
Az emésztőrendszer ismeretlen eredetű krónikus betegsége, a Crohn-betegség esetében például az összehasonlító tanulmányok alapján a genom több része is relevánsnak tűnt, azonban ezek jelentős része nem kódol fehérjét. A mostani kutatás azonban kiderítette, hogy nagyon fontos, az immunsejtek működésével kapcsolatos génkapcsolókról van szó. Ez a tudás pedig segíthet a szakértőknek abban, hogy megértsék, pontosan milyen immunrendszeri probléma áll a betegség hátterében, és a tudás birtokában hatásos kezelési módokat dolgozzanak ki.

Az ENCODE eredményeinek másik óriási előnye, hogy bepillantást engednek abba, hogyan néz ki egy-egy sejttípus molekuláris szinten. A „regeneratív orvoslásnak” nevezett irányvonal pedig rengeteg reményt fűz a sejtek alapszinten történő újraprogramozásához. Tim Hubbard, a brit Sanger Intézet informatikai igazgatója szerint az ENCODE segítségével pontosabb képet kapunk arról, hogyan lesz egy sejtből izomsejt, őssejt vagy bármilyen más funkciójú sejt. Ennek révén ellenőrizhető válik, hogy például azok a mesterségesen létrehozott idegsejtek, amelyeket egy gerincsérülés gyógyítására ültetnek be, valóban ugyanolyan módon működnek-e, mint természetes verziójuk. A genom működésének pontos megismerése révén egészen új utak tárulnak fel a gyógyításban.
A gigantikus projektben résztvevő kutatók szerint az eddigi eredmények nagyon jelentősek ugyan, de még rengeteg munka van hátra. A vizsgálatok során kifejlesztett és alkalmazott technológiákat szélesebb körben is el kell terjeszteni, hogy hatékonyabb eszközök kerüljenek a tudományterület művelőinek kezébe. Ennél azonban sokkal konkrétabb célok is vannak. A 147 sejttípus közül egyelőre mindössze hatot vizsgáltak meg a lehető legnagyobb részletességgel, a többi „molekuláris boncolása” még hátravan, és egy darabig még biztosan ellátja teendővel a kutatókat.
Az ENCODE továbbá egyelőre egy-egy sejttípus esetében csak egyetlen ember genomját vizsgálja, így ennek kiterjesztése is a következő lépések közé tartozik. A kiindulópont persze érthető: a DNS szempontjából elsőre sokkal fontosabbnak tűnt megérteni azt, hogy milyen gének fejeződnek ki egy májsejtben és egy bőrsejtben egy szervezeten belül, mint azt, hogy milyen eltérések mutatkoznak két különböző egyed bőrsejtjei között. Természetesen a jövőbeli még kifinomultabb technológiák mellett az is nagyon fontos kutatási terület lesz, hogy miben különbözik májsejtünk egy másik embertársunk májának sejtjeitől, főleg ha ő egészséges, mi pedig betegek vagyunk.
Az ENCODE tehát még évtizedekre van a befejezéstől, és annak megértésétől, hogyan is működik az emberi genom a sejtek szintjén. Az azonban biztos, hogy nagyon jelentős lépések történtek ennek megfejtése felé, és a projekt eredményei messze túlmutatnak az egyszerű génszekvenálás révén megismerhető tudás határain.