
2022 óta a technológia szektorban egyre jelentősebb szerepet tölt be a mesterséges intelligencia különböző formákban. Azt lehetett látni az elmúlt években, hogy az amerikai vállalatok uralják ezt a piacot, de most szinte a semmiből állt elő egy kínai szereplő olyan ígéretekkel, amire senki nem számított.
A DeepSeek R1 állítólag olyan hatékony, mint az OpenAI o1 modellje, miközben töredéke áron üzemeltethető. Elsősorban ez utóbbi okból eredően alakult ki kisebb pánik a techszektorban a friss fejlesztések láttán.
Január 20-án publikálta az R1 nevű modelljét a DeepSeek nevű kínai startup. Ezt a fejlesztők elmondása alapján arra tervezték, hogy komplex problémákat legyen képes megoldani, többszörösen összetett kérdésekre is nagy pontossággal adhat választ. Az OpenAI égisze alatt a szeptemberben bejelentett o1 modell szolgál hasonló célt. A lehetőségek itt már messze túlmutatnak azon, amit a kezdeti chatbotok tudtak 1-1,5 évvel korábban.
A DeepSeek fejlesztésében önmagában az már nagy szó, hogy versenyre kelhet az OpenAI által fejlesztett o1 modellel, de ez önmagában még nem lenne ok arra, hogy nagy felbolydulást váltson ki. Az ad igazán nagy aggodalomra okot a nyugati világban, hogy a DeepSeek hihetetlenül olcsón tudta felépíteni a saját megoldását. Az MI előmenetelésével azt is megszoktuk, hogy szó szerint repkednek a tíz- és százmilliárdos összegek a különböző beruházások kapcsán. De nem itt.
Az R1 érvelésre kihegyezett modell a V3 LLM nagy nyelvi modellen alapszik, amit a cég decemberben leplezett le. Ezt pedig a hírek szerint hozzávetőlegesen 5,6 millió dolláros költségvetés mellett alkotta meg. Itt tényleg minden túlzás nélkül lehet azt kijelenteni, hogy a DeepSeek R1 és az OpenAI R1, vagy akár csak a GPT-4o, összemérhetetlen költségvetéssel üzemel.
Egy dolog a DeepSeek és a vezető technológiai cégek fejlesztéseiben így is közös: ugyanúgy Nvidia chipeket használ. Az Nvidia mindenhol ott van, még akkor is, hogyha egy új „csoda MI” lép a színre. Viszont érdekesség ezen a fronton is bőven akad. A V3 LLM rendszer tréningezéséhez a rendelkezésre álló információk szerint csak kb. 2000 darab Nvidia gyorsítóra volt szükség, míg a nagy techcégek ennek a tízszeresété is alkalmazzák adott esetben.
Nagyon érdekes az is, hogy a DeepSeeknek a munkája során még szankciókkal is szembe kellett néznie. Kínában már nem lehet egyszerűen hozzáférni az Nvidia gyorsítókártyákhoz. H800 gyorsítók munkálkodtak a betanításon, és a részletek szerint összesen közel 2,67 millió munkaórát vett igénybe a tréningezés ezekkel a feldolgozókkal. Az R1 nyelvi modell 128 ezer tokenes kontextusablakkal dolgozik.
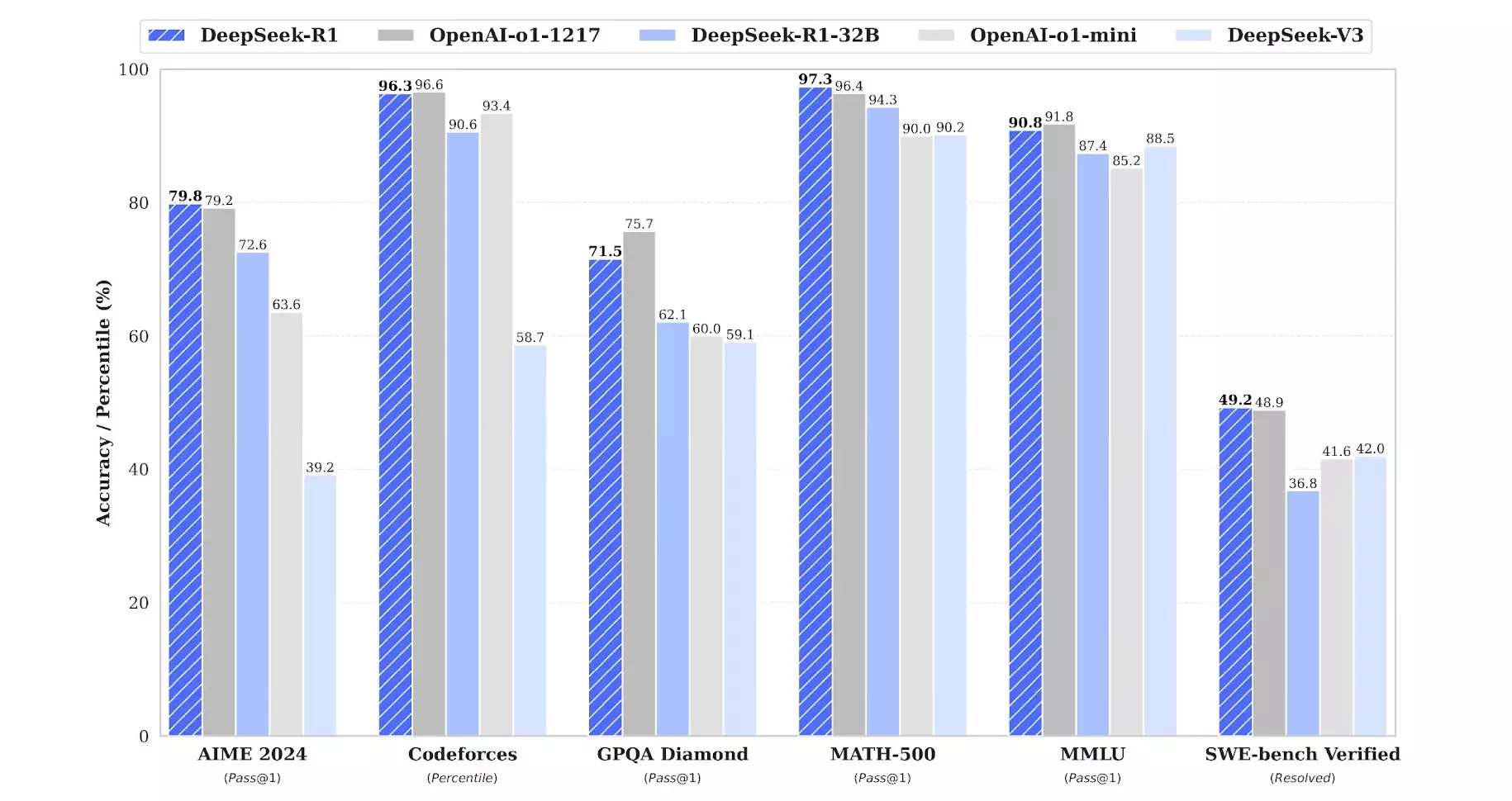
A beszámolók szerint érvelésben a DeepSeek R1 sokkal jobbnak érződik, mint a korábbi hagyományosabb modellek, viszont az OpenAI o1 legújabb kiadása már jobb valamivel, az o1-preview verziónál viszont már nem volt egyértelmű az eredmény. Matematikai fronton is hasonló a helyzet, az R1 elképesztően erős, de méréstől függően az o1 általában még jobb nála. Programozásban felveszi a versenyt az o1 modellel, egyszerű írásban viszont már az R1 jobban teljesít, részben annak köszönhetően, hogy kevésbé van „cenzúrázva”, szabadabban tud üzemelni. Az alábbiakban már néhány teszteredmény is látható.
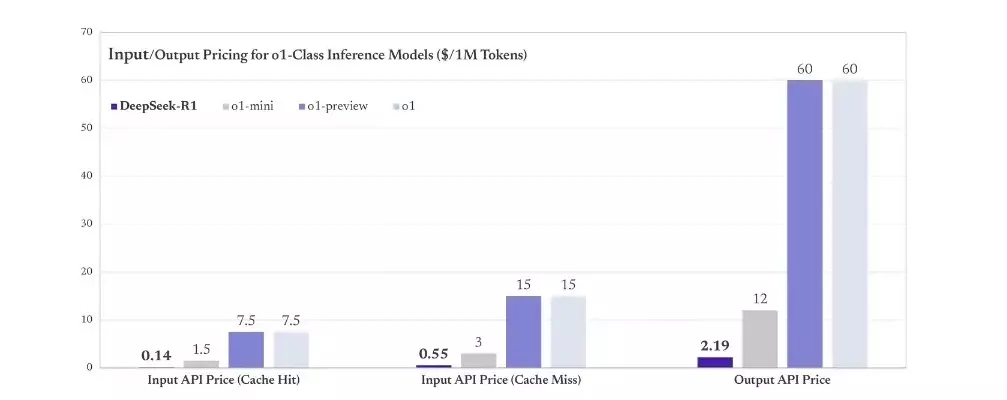
Az R1-ben az az igazán súlyos, hogy tényleg elképesztően olcsó. Csak az olyan apró, akár mobilon helyben is egyszerűen futtatható modellek olcsóbbak ennél, mint a GPT-4o-mini vagy a Claude 3 Haiku, miközben nem ezekkel játszik egy ligában, hanem a Claude 3.5 Sonnettel és az o1-gyel. 1 millió token feldolgozása az o1 esetén 15 dollár az OpenAI árjegyzéke szerint, míg az R1 érvelő modell 0,55 dollárba kerül. A kimenetben 1 millió token már 60 dollár az o1 esetén, míg az R1-nél ez 2,19 dollárt kóstál.
Nagyon érdekes lesz majd azt látni, hogy alakul a DeepSeek R1 jövője. Most elképesztően felkapták, már regionálisan korlátoznia kell a cégnek a regisztrációkat, állítólag egy jelentős kibertámadást is kapott azon felül, hogy elözönlötték az érdeklődők. Az App Store-ban a legnépszerűbb alkalmazás lett a chatbotja, megelőzve a ChatGPT-t.
